1 基础准备
1.1 集群环境介绍
| 操作系统 | 主机名 | 公网IP地址 | 内网IP | VPN内网IP | 角色 | k8s版本 | containerd版本 | 配置 |
|---|---|---|---|---|---|---|---|---|
| Rocky Linux 9.4 | k8s-master | 49.235.53.189 | 10.0.0.9 | 10.8.0.13 | master节点 | 1.33.5 | v2.1.4 | 4核4G |
| Rocky Linux 9.4 | k8s-node1 | 150.158.57.109 | 10.0.0.14 | 10.8.0.14 | node1节点 | 1.33.5 | v2.1.4 | 4核4G |
| Rocky Linux 9.4 | k8s-node2 | 110.40.154.116 | 10.0.0.9 | 10.8.0.16 | node2节点 | 1.33.5 | v2.1.4 | 4核4G |
1.2 关闭防火墙和SELinux
# 下列步骤需要在集群中所有机器上完成
# 关闭防火墙并设置为开机自动关闭
systemctl disable --now firewalld
# 关闭SELinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
# 临时关闭SELinux
setenforce 01.3 修改主机名
1.hostnamectl命名可立即生效
# master节点
sudo hostnamectl set-hostname k8s-master
# node1节点
sudo hostnamectl set-hostname k8s-node1
# node2节点
sudo hostnamectl set-hostname k8s-node2
2.修改配置文件
2.1 修改主机名配置文件
# 备份原配置文件 sudo cp /etc/hostname /etc/hostname.backup
# 修改主机名 echo "new-hostname" | sudo tee /etc/hostname
2.2 更新/etc/hosts文件
# 备份hosts文件 sudo cp /etc/hosts /etc/hosts.backup
# 修改hosts文件,确保有对应的解析 sudo sed -i "s/old-hostname/new-hostname/g" /etc/hosts
# 或者手动编辑,确保包含:
# 127.0.0.1 localhost new-hostname
# ::1 localhost new-hostname
2.3 立即生效操作
# 方法A:使用sysctl(推荐) sudo sysctl kernel.hostname=new-hostname
# 方法B:使用hostname命令 sudo hostname new-hostname
# 方法C:重启hostname服务(某些系统) sudo systemctl restart systemd-hostnamed1.4 内网通信-内网IP不重叠
云主机信息:
| 云主机名称 | 公网地址 | 内网地址 | VPN内网地址 | 区域 |
|---|---|---|---|---|
| k8s-master | 49.235.53.189 | 10.0.0.9 | 10.8.0.13 | 上海五区 |
| k8s-node1 | 150.158.57.109 | 10.0.0.14 | 10.8.0.14 | 上海八区 |
确保集群机器的安全组开放以下端口:
| 协议 | 端口 | 源 | 名称 | 协议号 |
|---|---|---|---|---|
| TCP | 6443 | 0.0.0.0/0(或对方IP) | ||
| TCP | 10250 | 0.0.0.0/0 | ||
| TCP | 179 | 0.0.0.0/0 | Calico BGP | |
| IPIP | 0.0.0.0/0 | Calico IPIP 隧道 | 4 | |
| TCP | 5473 | 0.0.0.0/0 | Typha | |
| TCP | 9099 | 0.0.0.0/0 | Calico typha |
通过公网建立VPN隧道,使用WireGuard的VPN解决方案,构建全互联的VPN网络-内网IP不重叠时:
1.在两台云主机上安装WireGuard:
# 安装EPEL源
1.Ubuntu
sudo apt install epel-release -y
2.CentOS/RHELL
sudo dnf install epel-release -y
# 检查内核模块
sudo modprobe wireguard
lsmod | grep wireguard
# 安装WireGuard
1.Ubuntu
sudo apt update && sudo apt install wireguard-tools -y
2.CentOS/RHELL
sudo dnf update && sudo dnf install wireguard-tools -y
# 生成密钥对
cd /etc/wireguard
wg genkey | sudo tee privatekey | wg pubkey | sudo tee publickey
# 这条命令会一次性生成一对密钥:私钥保存在 privatekey 文件中,公钥保存在 publickey 文件中
[root@k8s-master ~]# wg genkey | sudo tee privatekey | wg pubkey | sudo tee publickey
1g17zvnlX/SVkLa3i3sIqcaMhoMoGB15VQ5IRHZOsgk=
[root@k8s-node1 ~]# wg genkey | sudo tee privatekey | wg pubkey | sudo tee publickey
Ng+Q0TT1swm4eDW33xyOUCvIF6Oz+Qq+hcAvwmBZTGI=2.创建配置文件
# 在49.235.53.189(10.0.0.9)上配置:
[root@k8s-master ~]# sudo vim /etc/wireguard/wg0.conf
[Interface]
PrivateKey = 0Bv0/jwmgYuL/0HA430p2jS7ImRbUy9CpD0ojqVIf2A= # <49.235.53.189的私钥>
Address = 10.0.100.13/24
ListenPort = 51820
SaveConfig = false
[Peer]
PublicKey = Ng+Q0TT1swm4eDW33xyOUCvIF6Oz+Qq+hcAvwmBZTGI= # <150.158.57.109的公钥>
Endpoint = 150.158.57.109:51820
AllowedIPs = 10.0.0.14/32, 10.0.0.0/16
# 在150.158.57.109(10.0.0.14)上配置:
[root@k8s-node1 ~]# sudo vim /etc/wireguard/wg0.conf
[Interface]
PrivateKey = aEVbCZDrGtDlraK9JMkTDO3h8WCP34Lw6oebaPrz4Hg= # <150.158.57.109的私钥>
Address = 10.0.100.14/24
ListenPort = 51820
SaveConfig = false
[Peer]
PublicKey = 1g17zvnlX/SVkLa3i3sIqcaMhoMoGB15VQ5IRHZOsgk= # <49.235.53.189的公钥>
Endpoint = 49.235.53.189:51820
AllowedIPs = 10.0.0.9/32, 10.0.0.0/16
3.启动VPN服务
# 在两台服务器分别执行以下命令
sudo systemctl enable wg-quick@wg0
sudo systemctl restart wg-quick@wg0
# 防火墙允许51820/UDP并在腾讯云安全组添加规则(51820/udp)
1.firewalld防火墙
sudo firewall-cmd --zone=public --add-port=51820/udp --permanent
2.iptables防火墙
sudo iptables -A INPUT -p udp --dport 51820 -j ACCEPT1.5 内网通信-内网IP重叠
通过公网建立VPN隧道,使用WireGuard的VPN解决方案,构建全互联的VPN网络-内网IP重叠时:
注明:如果内网IP相同,需通过VPN分配不同的IP,还要允许通过VPN访问原始内网IP,但因为内网IP有重复,所以只能通过VPN IP进行通信,如果内网IP不重复,可以配置AllowedIPs包括原始内网IP
网络规划:
| VPN网段 | 服务器名称 | 服务器分配(公网) | VPN IP |
|---|---|---|---|
| 10.8.0.0/24 | k8s-master | 49.235.53.189 | 10.8.0.13 |
| 10.8.0.0/24 | k8s-node1 | 150.158.57.109 | 10.8.0.14 |
| 10.8.0.0/24 | k8s-node2 | 110.40.154.116 | 10.8.0.16 |
| 10.8.0.0/24 | k3s-master | 124.222.84.111 | 10.8.0.17 |
1.在四台云主机上安装WireGuard:
# 安装EPEL源
1.Ubuntu
sudo apt install epel-release -y
2.CentOS/RHELL
sudo dnf install epel-release -y
# 检查内核模块
sudo modprobe wireguard
lsmod | grep wireguard
# 安装WireGuard
1.Ubuntu
sudo apt update && sudo apt install wireguard-tools -y
2.CentOS/RHELL
sudo dnf update && sudo dnf install wireguard-tools -y
# 生成密钥对
cd /etc/wireguard
wg genkey | sudo tee privatekey | wg pubkey | sudo tee publickey
# 这条命令会一次性生成一对密钥:私钥保存在 privatekey 文件中,公钥保存在 publickey 文件中
[root@k8s-master ~]# wg genkey | sudo tee privatekey | wg pubkey | sudo tee publickey
1g17zvnlX/SVkLa3i3sIqcaMhoMoGB15VQ5IRHZOsgk=
[root@k8s-node1 ~]# wg genkey | sudo tee privatekey | wg pubkey | sudo tee publickey
Ng+Q0TT1swm4eDW33xyOUCvIF6Oz+Qq+hcAvwmBZTGI=
[root@k8s-node2 wireguard]# wg genkey | sudo tee privatekey | wg pubkey | sudo tee publickey
otIZjQ+qRISEB6NmkXJhIysw3frIshBSizDBIkIhdyE=
[root@k3s-master wireguard]# wg genkey | sudo tee privatekey | wg pubkey | sudo tee publickey
nOPoG9nUI26jk80tJTlf0O4b3anHHFN/gfDMbeUhZVU=2.创建配置文件
# 在49.235.53.189(10.0.0.9)上配置:
[Interface]
PrivateKey = 0Bv0/jwmgYuL/0HA430p2jS7ImRbUy9CpD0ojqVIf2A= # <49.235.53.189的私钥>
Address = 10.8.0.13/24
ListenPort = 51820
SaveConfig = false
[Peer]
PublicKey = Ng+Q0TT1swm4eDW33xyOUCvIF6Oz+Qq+hcAvwmBZTGI= # <150.158.57.109的公钥>
Endpoint = 150.158.57.109:51820
AllowedIPs = 10.8.0.14/32
PersistentKeepalive = 25
[Peer]
PublicKey = otIZjQ+qRISEB6NmkXJhIysw3frIshBSizDBIkIhdyE= # <110.40.154.116的公钥>
Endpoint = 110.40.154.116:51820
AllowedIPs = 10.8.0.16/32
PersistentKeepalive = 25
[Peer]
PublicKey = nOPoG9nUI26jk80tJTlf0O4b3anHHFN/gfDMbeUhZVU= # <124.222.84.111的公钥>
Endpoint = 124.222.84.111:51820
AllowedIPs = 10.8.0.17/32
PersistentKeepalive = 25
# 在150.158.57.109(10.0.0.14)上配置:
[root@k8s-node1 ~]# sudo vim /etc/wireguard/wg0.conf
[Interface]
PrivateKey = aEVbCZDrGtDlraK9JMkTDO3h8WCP34Lw6oebaPrz4Hg= # <150.158.57.109的私钥>
Address = 10.8.0.14/24
ListenPort = 51820
SaveConfig = false
[Peer]
PublicKey = 1g17zvnlX/SVkLa3i3sIqcaMhoMoGB15VQ5IRHZOsgk= # <49.235.53.189的公钥>
Endpoint = 49.235.53.189:51820
AllowedIPs = 10.8.0.13/32
PersistentKeepalive = 25
[Peer]
PublicKey = otIZjQ+qRISEB6NmkXJhIysw3frIshBSizDBIkIhdyE= # <110.40.154.116的公钥>
Endpoint = 110.40.154.116:51820
AllowedIPs = 10.8.0.16/32
PersistentKeepalive = 25
[Peer]
PublicKey = nOPoG9nUI26jk80tJTlf0O4b3anHHFN/gfDMbeUhZVU= # <124.222.84.111的公钥>
Endpoint = 124.222.84.111:51820
AllowedIPs = 10.8.0.17/32
PersistentKeepalive = 25
# 在110.40.154.116(10.0.0.9)上配置:
[root@k8s-node2 ~]# sudo vim /etc/wireguard/wg0.conf
[Interface]
PrivateKey = cGJ2ZLB99dopnpUNwL4IVG5UQrLPNZaKsfkFTUs0XEs= # <110.40.154.116的私钥>
Address = 10.8.0.16/24
ListenPort = 51820
SaveConfig = false
[Peer]
PublicKey = 1g17zvnlX/SVkLa3i3sIqcaMhoMoGB15VQ5IRHZOsgk= # <49.235.53.189的公钥>
Endpoint = 49.235.53.189:51820
AllowedIPs = 10.8.0.13/32
PersistentKeepalive = 25
[Peer]
PublicKey = Ng+Q0TT1swm4eDW33xyOUCvIF6Oz+Qq+hcAvwmBZTGI= # <150.158.57.109的公钥>
Endpoint = 150.158.57.109:51820
AllowedIPs = 10.8.0.14/32
PersistentKeepalive = 25
[Peer]
PublicKey = nOPoG9nUI26jk80tJTlf0O4b3anHHFN/gfDMbeUhZVU= # <124.222.84.111的公钥>
Endpoint = 124.222.84.111:51820
AllowedIPs = 10.8.0.17/32
PersistentKeepalive = 25
# 在124.222.84.111(10.0.0.5)上配置:
[root@k3s-master ~]# sudo vim /etc/wireguard/wg0.conf
[Interface]
PrivateKey = qPfhLQ8srpyZs660FyUuqVqksHYEnVis9IIX7RNhV2Q= # <124.222.84.111的私钥>
Address = 10.8.0.17/24
ListenPort = 51820
SaveConfig = false
[Peer]
PublicKey = 1g17zvnlX/SVkLa3i3sIqcaMhoMoGB15VQ5IRHZOsgk= # <49.235.53.189的公钥>
Endpoint = 49.235.53.189:51820
AllowedIPs = 10.8.0.13/32
PersistentKeepalive = 25
[Peer]
PublicKey = Ng+Q0TT1swm4eDW33xyOUCvIF6Oz+Qq+hcAvwmBZTGI= # <150.158.57.109的公钥>
Endpoint = 150.158.57.109:51820
AllowedIPs = 10.8.0.14/32
PersistentKeepalive = 25
[Peer]
PublicKey = otIZjQ+qRISEB6NmkXJhIysw3frIshBSizDBIkIhdyE= # <110.40.154.116的公钥>
Endpoint = 110.40.154.116:51820
AllowedIPs = 10.8.0.16/32
PersistentKeepalive = 253.启动VPN服务
# 在四台服务器分别执行以下命令
sudo systemctl enable wg-quick@wg0
sudo systemctl restart wg-quick@wg0
# 防火墙允许51820/UDP并在腾讯云安全组添加规则(51820/udp)
1.firewalld防火墙
sudo firewall-cmd --zone=public --add-port=51820/udp --permanent
2.iptables防火墙
sudo iptables -A INPUT -p udp --dport 51820 -j ACCEPT2 Containerd与Docker部署
2.1 Containerd部署
下载包含 containerd 和 nerdctl 的完整工具包。
解压到 /usr/local 目录,安装所有组件。
安装 nerdctl-full 版本集成了 containerd 。如主机已安装 containerd 请选择 nerdctl简易版(nerdctl-2.1.6-linux-amd64.tar.gz)
下载地址:https://github.com/containerd/nerdctl/releases
# 下列步骤需要在集群中所有机器上完成
# 下载nerdctl工具,这个工具使用containerd作为底层运行时,命令行高度兼容docker,是首选方案,下载好之后,把压缩包解压到 /usr/local 目录下,这样就可以方便后面使用
wget https://github.com/containerd/nerdctl/releases/download/v2.1.6/nerdctl-full-2.1.6-linux-amd64.tar.gz
tar Cxzvvf /usr/local nerdctl-full-2.1.6-linux-amd64.tar.gz
# 查看containerd安装好的版本
[root@k8s-master ~]# containerd -v
containerd github.com/containerd/containerd/v2 v2.1.4 75cb2b7193e4e490e9fbdc236c0e811ccaba3376
[root@k8s-node1 ~]# containerd -v
containerd github.com/containerd/containerd/v2 v2.1.4 75cb2b7193e4e490e9fbdc236c0e811ccaba3376
[root@k8s-node2 ~]# containerd -v
containerd github.com/containerd/containerd/v2 v2.1.4 75cb2b7193e4e490e9fbdc236c0e811ccaba33762.1.1 生成配置文件
创建配置目录并生成默认配置文件。
替换 pause 镜像为国内源,这里的国内源可以是任何你能访问的源。
配置镜像加速器路径。
# 下列步骤需要在集群中所有机器上完成
# 要给 containerd 做一些配置,让它能更好地工作。首先创建一个配置文件夹 /etc/containerd,然后生成默认的配置文件
mkdir /etc/containerd
# containerd生成配置文件
containerd config default > /etc/containerd/config.toml
# 配置crictl连接containerd
cat >> /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
# 修改镜像源
1.修改一下配置文件,把默认的 pause 镜像地址换成一个国内的镜像地址,这样在国内访问会更快
sed -i "s|sandbox = 'registry.k8s.io/pause:3.10'|sandbox = 'registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.10'|" /etc/containerd/config.toml
2.将 sandbox_image 镜像源设置为阿里云google_containers镜像源
sed -i "s#registry.k8s.io/pause:3.8#registry.aliyuncs.com/google_containers/pause:3.10#g" /etc/containerd/config.toml
# 设置镜像仓库的配置路径,让containerd知道去哪里找镜像之类的,如果有容器镜像加速器,就应该配置在这个路径下。
# containerd的1.X版本和containerd的2.X版本,这里的路径是不一样的
sed -i '/^\s*\[plugins.'"'"'io.containerd.cri.v1.images'"'"'.registry\]/{n;s|^\(\s*\)config_path = .*$|\1config_path = '"'"'/etc/containerd/certs.d'"'"'|}' /etc/containerd/config.toml
# 配置containerd cgroup 驱动程序为systemd
sed -i 's#SystemdCgroup = false#SystemdCgroup = true#g' /etc/containerd/config.toml2.1.2 使用镜像加速器
在中国需要设置国内镜像加速器,提升拉取镜像的速度
为了能让 containerd 正常拉取镜像,还要配置一下镜像仓库的证书信息。首先,创建一个目录来存放证书,创建一个配置文件,告诉 containerd 我们要使用一个国内的镜像代理地址,这样拉取镜像会更快。
Containerd容器可用的免费镜像加速器配置方法。Containerd的配置方式与Docker不同,主要分为旧版本(1.5之前)和新版本(1.5及以上)两种方法:
1.旧版本配置方法(1.5之前)
对于Containerd 1.5版本之前的配置,需要直接修改/etc/containerd/config.toml文件:
tomlCopy Code[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://docker.m.daocloud.io", "https://hub-mirror.c.163.com"]修改后需要重启Containerd服务。
systemctl restart containerd2.新版本配置方法(1.5及以上)
新版本推荐使用/etc/containerd/certs.d/目录进行配置,这种方式支持热加载,无需重启服务:
# 下列步骤需要在集群中所有机器上完成
mkdir /etc/containerd/certs.d/docker.io -p
cat > /etc/containerd/certs.d/docker.io/hosts.toml <<-'EOF'
server = "https://docker-0.unsee.tech"
[host."https://docker-0.unsee.tech"]
capabilities = ["pull", "resolve", "push"]
EOF3.常用免费加速器地址
以下是一些可用的免费镜像加速器地址,可以根据需要选择使用:
阿里云镜像加速器:https://<your_id>.mirror.aliyuncs.com(需替换为您的ID)
https://1016220537097033.mirror.aliyuncs.com
DaoCloud镜像加速器:https://docker.m.daocloud.io
优先推荐(就近+稳定):https://docker.1ms.run、https://docker-0.unsee.tech
其他备选(均正常):
https://ccr.ccs.tencentyun.com
4.测试拉取镜像
配置完成后,可以使用以下命令测试加速器是否生效:
[root@k8s-master ~]# nerdctl pull calico/node:v3.30.4
docker.io/calico/node:v3.30.4: resolved |++++++++++++++++++++++++++++++++++++++|
index-sha256:362f10b69142fcc654c0ab65a5f371923f9a1d8f7772eac0ff223b9dc67704de: done |++++++++++++++++++++++++++++++++++++++|
manifest-sha256:b6c92e535b935575f48092edadcfaec716ebce53f1fbc56d312744e86ce0fb17: done |++++++++++++++++++++++++++++++++++++++|
config-sha256:833e8e11d9dc187377eab6f31e275114a6b0f8f0afc3bf578a2a00507e85afc9: done |++++++++++++++++++++++++++++++++++++++|
layer-sha256:44c2028a3ff8d71676da71a6c671786584592f991e0eea338c6de86237383ff7: done |++++++++++++++++++++++++++++++++++++++|
elapsed: 10.1s total: 149.6 (14.8 MiB/s)2.1.3 启动Containerd服务
启动并设置 containerd 和 buildkit 服务为开机自启。
containerd 是一个高性能的容器运行时,负责管理容器的生命周期,包括镜像拉取、容器创建、运行、停止等,是 Kubernetes 支持的主流运行时之一。
BuildKit 是 Docker 和 containerd 的构建引擎,用于高效地构建镜像,支持并行构建、缓存优化和安全隔离等高级功能。
# 下列步骤需要在集群中所有机器上完成
# 启动 containerd 和 buildkit 服务
systemctl daemon-reload
# 启动containerd并设置开机自启动
systemctl enable --now containerd
systemctl enable --now buildkit
# 查看containerd状态
systemctl status containerd2.1.4 nerdctl命令自动补齐
生成 bash 自动补齐脚本,立即生效,提高命令行操作效率。
# 下列步骤需要在集群中所有机器上完成
nerdctl completion bash > /etc/bash_completion.d/nerdctl
source /etc/bash_completion.d/nerdctl2.2 Docker CE 部署
dockerd实际真实调用的还是containerd的api接口,containerd是dockerd和runC之间的一个中间交流组件。所以启动docker服务的时候,也会启动containerd服务的。
kubernets自v1.24.0后,就不再使用docker.shim,替换采用containerd作为容器运行时端点。因此需要安装containerd(在docker的基础下安装),上面安装docker的时候就自动安装了containerd了。这里的docker只是作为客户端而已。容器引擎还是containerd。
可以直接安装container.io,而不用安装docker
2.2.1 卸载旧版本
在安装 Docker Engine 之前,需要卸载任何冲突的软件包。
Linux 发行版可能会提供非官方的 Docker 包,这可能会发生冲突 使用 Docker 提供的官方软件包。必须卸载这些包在安装正式版 Docker Engine 之前。
# dnf可能会报告您没有安装这些软件包。
# 存储在 卸载 Docker 时自动删除。/var/lib/docker/
sudo dnf remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine \
podman \
runc2.2.2 使用 rpm 存储库安装
可以根据需要以不同的方式安装 Docker Engine:
可以设置 Docker 的存储库并安装,从他们那里方便安装和升级任务。这是推荐的方法。
可以下载 RPM 包,手动安装,然后管理完全手动升级。适合在无法访问互联网的的系统上安装Docker。
在测试和开发环境中,可以使用自动化便利脚本来安装 Docker。
1.设置存储库
在首次在新主机上安装 Docker Engine 之前,需要设置 Docker 存储库。之后可以从存储库安装和更新 Docker 。
# yum install -y yum-utils device-mapper-persistent-data lvm2
# yum-config-manager --add-repo https://download.docker.com/linux/rhel/docker-ce.repo
sudo dnf -y install dnf-plugins-core
sudo dnf config-manager --add-repo https://download.docker.com/linux/rhel/docker-ce.repo2.安装 Docker 引擎
1.安装 Docker 包
# yum install -y docker-ce docker-ce-cli containerd.io
sudo dnf install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
2.启动 Docker 引擎
sudo systemctl enable --now docker3.关于Docker的完整安装
1.卸载docker旧版本
yum remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-selinux docker-engine-selinux docker-engine
2.安装相关工具类
yum install -y yum-utils device-mapper-persistent-data lvm2
3.配置docker仓库(阿里云)
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
4.安装docker
yum install docker-ce
5.验证docker安装成功
#启动docker
systemctl start docker
# 创建开机自启
sudo systemctl enable --now docker
#检查 Docker 服务状态
sudo systemctl status docker
#验证docker
docker run hello-world2.2.3 Docker 镜像加速器
添加Docker 镜像加速器,这里只限在国内部署时才需要加速,在国外这样加速反而缓慢
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://mirror.ccs.tencentyun.com",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://mirror.gcr.io",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com"
],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
systemctl daemon-reload
systemctl restart docker3 准备DNS解析
这一步需要在集群中所有机器上完成
# 配置内网IP进行DNS解析,生产环境中建议使用内网在集群中通信
# 如果内网不通,可考虑使用公网进行解析或使用VPN打通内网连接
cat >> /etc/hosts <<EOF
10.8.0.13 k8s-master
10.8.0.14 k8s-node1
10.8.0.16 k8s-node2
EOF4 操作Containerd容器
4.1 镜像操作
1.拉取镜像
[root@k8s-master ~]~# nerdctl pull registry.myk8s.cn/library/httpd
[root@k8s-master ~]~# nerdctl images
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
registry.myk8s.cn/library/httpd latest 4564ca760495 2 minutes ago linux/amd64 162.2MB 58.5MB
registry.myk8s.cn/library/nginx latest 5ed8fcc66f4e 22 minutes ago linux/amd64 207MB 72.39MB
2.删除镜像
[root@k8s-master ~]~# nerdctl rmi registry.myk8s.cn/library/httpd
[root@k8s-master ~]~# nerdctl images
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
registry.myk8s.cn/library/nginx latest 5ed8fcc66f4e 23 minutes ago linux/amd64 207MB 72.39MB
[root@k8s-master ~]~# nerdctl rmi -f $(nerdctl images -aq)
[root@k8s-master ~]~# nerdctl images
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
<none> <none> 5ed8fcc66f4e 6 seconds ago linux/amd64 207MB 72.39MB
参数说明:
1.删除镜像 nerdctl rmi 镜像名
2.删除所有镜像 nerdctl rmi -f $(docker images -aq)
说明:列出所有镜像的ID,并使用nerdctl rmi -f强制删除
3.使用nerdctl system prune命令 nerdctl system prune -a --volumes
说明:删除所有停止的容器、未被使用的网络、卷、没有关联容器的镜像以及所有构建缓存
4.使用nerdctl image prune命令 nerdctl image prune -a -f
说明:删除所有未被使用的镜像,-a参数表示删除所有未使用的镜像,而不仅仅是悬空镜像,-f参数表示不进行确认提示4.2 创建持续运行的容器
[root@k8s-master ~]~# nerdctl run -d -p 9000:80 --name container1 registry.myk8s.cn/library/nginx
9a834031839a1dbe75a454f8e4dbab6717b9a4f921d8a8657785502b565f376b
[root@k8s-master ~]~# nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9a834031839a registry.myk8s.cn/library/nginx:latest "/docker-entrypoint.…" 10 seconds ago Up 0.0.0.0:9000->80/tcp container1
[root@k8s-master ~]~# nerdctl images
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
registry.myk8s.cn/library/nginx latest 5ed8fcc66f4e 9 minutes ago linux/amd64 207MB 72.39MB
# 参数说明:
-d:后台运行
-p:端口映射,此处是将宿主机的8000端口和容器内的80端口映射到一起
–name:容器的名字
nginx:本次使用的镜像名字
nerdctl ps 查看正在运行的容器
nerdctl ps -a 查看所有容器4.3 进入容器并访问
1.进入容器
[root@k8s-master ~]~# nerdctl exec -it container1 /bin/bash
root@9a834031839a:/# echo Hello Containerd > /usr/share/nginx/html/index.html
root@9a834031839a:/# exit
exit
2.访问容器
[root@k8s-master ~]~# curl http://127.0.0.1:900
curl: (7) Failed to connect to 127.0.0.1 port 900 after 0 ms: Couldn't connect to server
[root@k8s-master ~]~# curl http://127.0.0.1:9000
Hello Containerd4.4 删除容器
[root@k8s-master ~]~# nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9a834031839a registry.myk8s.cn/library/nginx:latest "/docker-entrypoint.…" 22 minutes ago Up 0.0.0.0:9000->80/tcp container1
[root@k8s-master ~]~# nerdctl rm -f container1
container1
[root@k8s-master ~]~# nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 参数说明:
1.删除已经停止的容器 nerdctl rm 容器名称、nerdctl rm 容器ID
2.强制删除正在运行的容器 nerdctl rm -f 容器名称
说明:使用强制删除选项-f会立即停止并删除容器,可能会导致数据丢失或服务中断
3.删除多个容器 nerdctl rm container1 container2 ...
4.删除所有容器(包括正在运行的容器) nerdctl rm -f $(nerdctl ps -aq)
说明:通过nerdctl ps -aq列出所有容器的ID,然后通过nerdctl rm -f强制删除
[root@k8s-master ~]~# nerdctl run -d -p 9000:80 --name container1 registry.myk8s.cn/library/nginx
[root@k8s-master ~]~# nerdctl run -d -p 7000:80 --name container2 registry.myk8s.cn/library/httpd
[root@k8s-master ~]~# nerdctl ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
edd159eed7e1 registry.myk8s.cn/library/httpd:latest "httpd-foreground" 43 seconds ago Up 0.0.0.0:7000->80/tcp container2
9f789c6447dc registry.myk8s.cn/library/nginx:latest "/docker-entrypoint.…" About a minute ago Up 0.0.0.0:9000->80/tcp container1
[root@k8s-master ~]~# nerdctl ps -aq
[root@k8s-master ~]~# nerdctl rm -f $(nerdctl ps -aq)
[root@k8s-master ~]~# nerdctl ps -a4.5 构建与使用镜像
4.5.1 nerdctl commit构建
使用容器中发生更改的部分生成一个新的镜像,通常的使用场景为,基于普通镜像启动了容器,在容器内部署了所需的业务后,把当前的状态重新生成镜像,以便以当前状态快速部署业务所用
[root@k8s-master ~]~# nerdctl images
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
registry.myk8s.cn/library/httpd latest 4564ca760495 7 minutes ago linux/amd64 162.2MB 58.5MB
registry.myk8s.cn/library/nginx latest 5ed8fcc66f4e 18 minutes ago linux/amd64 207MB 72.39MB
<none> <none> 5ed8fcc66f4e 32 minutes ago linux/amd64 207MB 72.39MB
[root@k8s-master ~]~# nerdctl tag registry.myk8s.cn/library/nginx:latest nginx:v0
[root@k8s-master ~]~# nerdctl images
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
nginx v0 5ed8fcc66f4e 5 seconds ago linux/amd64 207MB 72.39MB
registry.myk8s.cn/library/httpd latest 4564ca760495 9 minutes ago linux/amd64 162.2MB 58.5MB
registry.myk8s.cn/library/nginx latest 5ed8fcc66f4e 21 minutes ago linux/amd64 207MB 72.39MB
<none> <none> 5ed8fcc66f4e 34 minutes ago linux/amd64 207MB 72.39MB
[root@k8s-master ~]~# nerdctl run -d -p 9000:80 --name container1 nginx:v0
[root@k8s-master ~]~# nerdctl ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6f8c50caccc3 docker.io/library/nginx:v0 "/docker-entrypoint.…" 8 seconds ago Up 0.0.0.0:9000->80/tcp container1
1.将上述的container1容器生成一个新的镜像:nginx:v1
[root@k8s-master ~]~# nerdctl commit container1 nginx:v1
sha256:75075d88243da88c3be2009c39bbed95d384c90383c9122d06dc40f3492d4f0e
[root@k8s-master ~]~# nerdctl images
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
nginx v1 ff3d36d56246 23 seconds ago linux/amd64 207MB 72.39MB
nginx v0 5ed8fcc66f4e 2 minutes ago linux/amd64 207MB 72.39MB
registry.myk8s.cn/library/httpd latest 4564ca760495 12 minutes ago linux/amd64 162.2MB 58.5MB
registry.myk8s.cn/library/nginx latest 5ed8fcc66f4e 23 minutes ago linux/amd64 207MB 72.39MB
<none> <none> 5ed8fcc66f4e 37 minutes ago linux/amd64 207MB 72.39MB
2.使用Commit镜像:使用nginx:v1镜像在本机的3000端口提供一个名为container2的容器
[root@k8s-master ~]~# nerdctl run -d -p 3000:80 --name container2 nginx:v1
eb4c803b8104b6ae66dba79b3d0e9cea01a7e5950ee834dded8575432e25025f
[root@k8s-master ~]~# nerdctl ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
eb4c803b8104 docker.io/library/nginx:v1 "/docker-entrypoint.…" 5 seconds ago Up 0.0.0.0:3000->80/tcp container2
6f8c50caccc3 docker.io/library/nginx:v0 "/docker-entrypoint.…" 2 minutes ago Up 0.0.0.0:9000->80/tcp container1
[root@k8s-master ~]~# nerdctl exec -it container2 /bin/bash
root@eb4c803b8104:/# echo hello ChengDu! > /usr/share/nginx/html/index.html
root@eb4c803b8104:/# exit
exit
[root@k8s-master ~]~# curl http://127.0.01:3000
hello ChengDu!4.5.2 Dockerfile构建
从零开始构建自己所需的镜像,在创建镜像之初把所需的各种设置和所需要的各种应用程序包含进去,生成的镜像可直接用于业务部署
Dockerfile高频指令集:
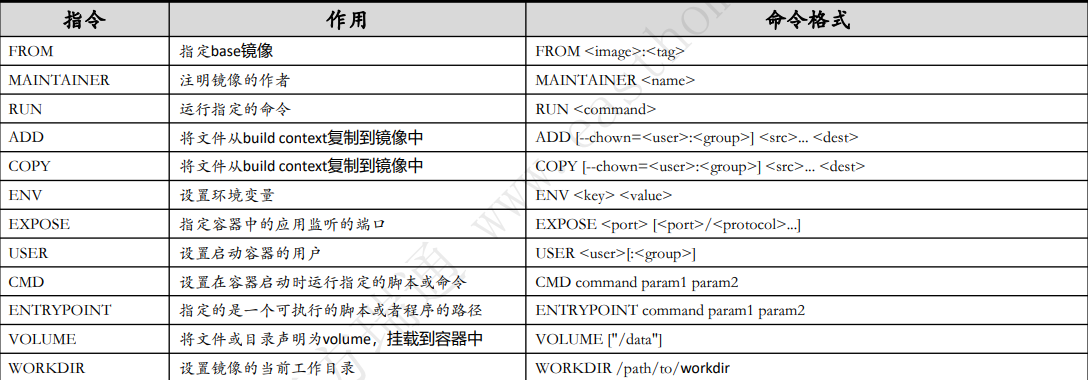
设计Dockerfile时应考虑: 容器应该是暂时的、避免安装不必要的软件包、每个容器只应该有一个用途、避免容器有过多的层、多行排序、建立缓存
1.创建dockerfile文件并构建
[root@k8s-master ~]~# vim dockerfile
FROM registry.myk8s.cn/library/httpd
MAINTAINER 252414302@qq.com
RUN echo 你好,中国 > /usr/local/apache2/htdocs/index.html
EXPOSE 80
WORKDIR /usr/local/apache/htdocs/
[root@k8s-master ~]~# nerdctl build -t httpd:v2 -f dockerfile .
[root@k8s-master ~]~# nerdctl images
REPOSITORY TAG IMAGE ID CREATED PLATFORM SIZE BLOB SIZE
httpd v2 43243a4ac567 2 seconds ago linux/amd64 162.2MB 58.5MB
httpd v1 43243a4ac567 About a minute ago linux/amd64 162.2MB 58.5MB
nginx v1 ff3d36d56246 11 minutes ago linux/amd64 207MB 72.39MB
nginx v0 5ed8fcc66f4e 13 minutes ago linux/amd64 207MB 72.39MB
registry.myk8s.cn/library/httpd latest 4564ca760495 23 minutes ago linux/amd64 162.2MB 58.5MB
registry.myk8s.cn/library/nginx latest 5ed8fcc66f4e 34 minutes ago linux/amd64 207MB 72.39MB
<none> <none> 5ed8fcc66f4e 48 minutes ago linux/amd64 207MB 72.39MB
注明:如果文件名是Dockerfile时可不指定
nerdctl build -t web:v1 .
#参数说明:
1.t 或 -tag:此选项允许为构建的镜像分配标签,以便于引用和版本控制
示例用法: nerdctl build -t sampleapp:latest .
2.f 或 file:如果 Dockerfile 的名称不是 “Dockerfile”,则可以使用此选项指定不同的 Dockerfile 名称或位置
示例用法: nerdctl build -f ProductionDockerfile .
2.使用Dockerfile镜像:用httpd:v1的镜像在本机4000端口上提供一个名为dockerfilecontainer的容器
[root@k8s-master ~]~# nerdctl run -d -p 4000:80 --name dockerfilecontainer httpd:v1
[root@k8s-master ~]~# nerdctl ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8ade7ac2dd39 docker.io/library/httpd:v1 "httpd-foreground" 8 seconds ago Up 0.0.0.0:4000->80/tcp dockerfilecontainer
eb4c803b8104 docker.io/library/nginx:v1 "/docker-entrypoint.…" 11 minutes ago Up 0.0.0.0:3000->80/tcp container2
6f8c50caccc3 docker.io/library/nginx:v0 "/docker-entrypoint.…" 14 minutes ago Up 0.0.0.0:9000->80/tcp container15 部署kubernetes集群
5.1 时间同步
可选步骤,主要是让三个节点的时间同步。
# 下列步骤需要在集群中所有机器上完成
yum install -y chrony
sed -i 's/^pool.*/#&/' /etc/chrony.conf
cat >> /etc/chrony.conf << EOF
pool ntp1.aliyun.com iburst
EOF
systemctl restart chronyd
chronyc sources
# 修改时区,如果之前是这个时区就不用修改
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
echo 'Asia/Shanghai' > /etc/timezone
[root@k8s-master ~]# date
Tue Nov 11 04:21:58 PM CST 2025
[root@k8s-master ~]# cat /etc/timezone
Asia/Shanghai
[root@k8s-node1 ~]# date
Tue Nov 11 04:21:58 PM CST 2025
[root@k8s-node1 ~]# cat /etc/timezone
Asia/Shanghai
[root@k8s-node2 ~]# date
Thu Nov 13 08:10:31 PM CST 2025
[root@k8s-node2 ~]# cat /etc/timezone
Asia/Shanghai5.2 关闭交换分区
Kubernetes 在1.34版本之前要求禁用 swap 分区,否则 kubelet 会拒绝启动。第一条命令临时关闭 swap,第二条命令注释掉 /etc/fstab 中的 swap 配置,防止重启后自动启用
1.34以上的版本还是推荐禁用swap分区以提升稳定性
# 下列步骤需要在集群中所有机器上完成
# 关闭当前交换分区
swapoff -a
# 禁止开机自动启动交换分区
sed -i 's/.*swap.*/#&/' /etc/fstab5.3 允许iptables检查桥接流量
这些配置确保 Kubernetes 网络插件(如 Calico)能正确处理容器之间的网络流量:
加载 br_netfilter 模块,使 Linux 能够检查桥接网络流量,将桥接的IPv4流量传递到iptables的链
设置内核参数,允许 iptables 处理 IPv4 和 IPv6 桥接数据包。
启用 IP 转发,支持容器之间的通信。
# 下列步骤需要在集群中所有机器上完成
# 加载内核模块
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
# 加载
modprobe overlay
modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
# 加载生效
sysctl -p /etc/sysctl.d/k8s.conf
sysctl --system
# 查看是否加载完成
lsmod | grep br_netfilter
[root@k8s-master ~]# lsmod | grep br_netfilter
br_netfilter 36864 0
bridge 417792 1 br_netfilter
[root@k8s-node1 ~]# lsmod | grep br_netfilter
br_netfilter 36864 0
bridge 417792 1 br_netfilter
[root@k8s-node2 ~]# lsmod | grep br_netfilter
br_netfilter 36864 0
bridge 417792 1 br_netfilter5.4 配置免密登录
可选操作,主要便于批量管理
# 以下步骤仅在master节点完成即可
ssh-keygen # 连续回车三次
ssh-copy-id -i ~/.ssh/id_ed25519.pub root@150.158.57.109
ssh-copy-id -i ~/.ssh/id_ed25519.pub root@110.40.154.116
[root@k8s-master ~]# ssh-keygen
[root@k8s-master ~]# ssh-copy-id -i ~/.ssh/id_ed25519.pub root@150.158.57.109
[root@k8s-master ~]# ssh-copy-id -i ~/.ssh/id_ed25519.pub root@110.40.154.116
# 测试登录
[root@k8s-master ~]# ssh root@150.158.57.109
[root@k8s-master ~]# ssh root@110.40.154.1165.5 安装ipvs转发支持
在kubernetes中Service有两种代理模型,一种是基于iptables的,一种是基于ipvs,两者对比ipvs的性能要高。默认使用iptables,所以要手动加载ipvs。
# 下列步骤需要在集群中所有机器上完成
# 安装依赖包
yum install -y conntrack ipvsadm ipset jq sysstat curl iptables libseccomp
mkdir /etc/sysconfig/modules
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
chmod +x /etc/sysconfig/modules/ipvs.modules
# 执行脚本
/etc/sysconfig/modules/ipvs.modules
# 验证ipvs模块
[root@k8s-master ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
ip_vs_sh 12288 0
ip_vs_wrr 12288 0
ip_vs_rr 12288 0
ip_vs 237568 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 229376 1 ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 12288 3 nf_conntrack,nf_tables,ip_vs
[root@k8s-node1 ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
ip_vs_sh 12288 0
ip_vs_wrr 12288 0
ip_vs_rr 12288 0
ip_vs 237568 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 229376 1 ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 12288 3 nf_conntrack,nf_tables,ip_vs
[root@k8s-node2 ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
ip_vs_sh 12288 0
ip_vs_wrr 12288 0
ip_vs_rr 12288 0
ip_vs 237568 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 229376 3 nf_nat,nft_ct,ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 12288 4 nf_conntrack,nf_nat,nf_tables,ip_vs5.6 配置k8s在国内的yum源
配置南京大学软件仓库进行加速,本次安装的k8s版本是1.34
# 下列步骤需要在集群中所有机器上完成
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.nju.edu.cn/kubernetes/core%3A/stable%3A/v1.33/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.nju.edu.cn/kubernetes/core%3A/stable%3A/v1.33/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
yum clean all
yum makecache
# 查看所有的可用版本 yum list kubelet --showduplicates | sort -r |grep 1.34
[root@k8s-master ~]# yum list kubelet --showduplicates | sort -r |grep 1.345.7 安装kubectl、kubelet和kubeadm
安装kubelet kubeadm kubectl这三个包,把kubelet服务启动一下
# 下列步骤需要在集群中所有机器上完成
# 安装指定版本
# yum install -y kubectl-1.34.1 kubelet-1.34.1 kubeadm-1.34.1
# 若不指定版本默认安装最高版本
sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
# 安装包解释
1.kubectl是命令行工具
2.kubeadm仅是一个集群搭建工具,不涉及启动
3.kubelet是一个守护进程程序,由kubeadm在搭建过程中自动启动,这里仅设置开机启动即可
sudo systemctl enable --now kubelet5.8 添加命令自动补齐功能
启用 bash 自动补齐,提高命令行效率,避免拼写错误。
# 下列步骤需要在集群中所有机器上完成
kubectl completion bash > /etc/bash_completion.d/kubectl
kubeadm completion bash > /etc/bash_completion.d/kubeadm
source /etc/bash_completion.d/kubectl
source /etc/bash_completion.d/kubeadm5.9 集成Containerd
crictl 是一个用来管理容器运行时的命令行工具,它就像是一个“中间人”,帮助 Kubernetes 和容器运行时(比如 containerd)之间进行通信。
Kubernetes 通过 CRI 与容器运行时通信。这里使用 crictl 工具配置运行时接口:
如果使用 cri-dockerd,则指向 /run/cri-dockerd.sock。
如果使用 containerd,则指向 /run/containerd/containerd.sock。
1.runtime-endpoint
这个字段告诉 crictl,容器运行时(containerd)的运行时接口地址在哪里。这里写的是 unix:///run/containerd/containerd.sock,意思就是通过 Unix 套接字(socket)的方式,连接到 /run/containerd/containerd.sock 这个地址。简单来说,就是告诉 crictl 怎么和 containerd 通信。
2.image-endpoint
这个字段和 runtime-endpoint 类似,不过它是用来指定镜像服务的接口地址。这里也是 unix:///run/containerd/containerd.sock,说明镜像服务和运行时服务是同一个地址,都是通过 containerd 来管理的。
# 下列步骤需要在集群中所有机器上完成
# crictl config --set runtime-endpoint=unix:///run/containerd/containerd.sock
# crictl config --set image-endpoint=unix:///run/containerd/containerd.sock
# crictl images
cat > /etc/crictl.yaml <<-'EOF'
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF
# 集成是否成功,可以用下面的命令来简单检查一下,不报错就是成功了
[root@k8s-master ~]# crictl images
IMAGE TAG IMAGE ID SIZE
[root@k8s-node1 ~]# crictl images
IMAGE TAG IMAGE ID SIZE
[root@k8s-node2 ~]# crictl images
IMAGE TAG IMAGE ID SIZE
# 顺便给crictl做一个命令补齐功能
crictl completion bash > /etc/bash_completion.d/crictl
source /etc/bash_completion.d/crictl5.10 开通防火墙
# 下列步骤需要在集群中所有机器上完成
1.开启 IP 隧道协议(IP-in-IP)
sudo firewall-cmd --zone=public --add-protocol=ipip --permanent
2.开启 BGP 所需的 TCP 179 端口
sudo firewall-cmd --zone=public --add-port=179/tcp --permanent
3.开启 VXLAN 所需的 UDP 4789 端口
sudo firewall-cmd --zone=public --add-port=4789/udp --permanent
4.开启 Wireguard 所需的 UDP 51820 端口
sudo firewall-cmd --zone=public --add-port=51820/udp --permanent
5.开启 IPv6 Wireguard 所需的 UDP 51821 端口
sudo firewall-cmd --zone=public --add-port=51821/udp --permanent
6.开启 Typha 代理所需的 TCP 5473 端口
sudo firewall-cmd --zone=public --add-port=5473/tcp --permanent
7.开启 Kubernetes API (kube-apiserver) 所需的 TCP 443 和 6443 端口
sudo firewall-cmd --zone=public --add-port=443/tcp --permanent
sudo firewall-cmd --zone=public --add-port=6443/tcp --permanent
8.开启 Calico Enterprise API 服务器所需的 TCP 8080 和 5443 端口
sudo firewall-cmd --zone=public --add-port=8080/tcp --permanent
sudo firewall-cmd --zone=public --add-port=5443/tcp --permanent
9.开启 calico-node (Felix, BIRD, confd) 所需的 TCP 9090 端口
sudo firewall-cmd --zone=public --add-port=9090/tcp --permanent
10.开启 Prometheus 指标所需的 TCP 9081 端口
sudo firewall-cmd --zone=public --add-port=9081/tcp --permanent
11.开启 Prometheus BGP 指标所需的 TCP 9900 端口
sudo firewall-cmd --zone=public --add-port=9900/tcp --permanent
12.开启 Elasticsearch with fluentd 数据存储所需的 TCP 9200 端口
sudo firewall-cmd --zone=public --add-port=9200/tcp --permanent
13.开启 Elasticsearch 云 (ECK) 所需的 TCP 9443 端口
sudo firewall-cmd --zone=public --add-port=9443/tcp --permanent
14.开启 Elasticsearch 网关所需的 TCP 5444 端口
sudo firewall-cmd --zone=public --add-port=5444/tcp --permanent
15.开启 Kibana 所需的 TCP 5601 端口
sudo firewall-cmd --zone=public --add-port=5601/tcp --permanent
16.开启 数据包捕获 API 所需的 TCP 8444 端口
sudo firewall-cmd --zone=public --add-port=8444/tcp --permanent
17.开启 Calico Enterprise Manager UI 所需的 TCP 9443 端口
sudo firewall-cmd --zone=public --add-port=9443/tcp --permanent
18.开启 多集群管理所需的 TCP 9449 端口
sudo firewall-cmd --zone=public --add-port=9449/tcp --permanent
19.开启 出口网关所需的 UDP 4790 端口
sudo firewall-cmd --zone=public --add-port=4790/udp --permanent
20.重新加载防火墙配置,使更改生效
sudo firewall-cmd --reload
21.查看开放的端口
sudo firewall-cmd --list-ports # firewalld
sudo iptables -L -n # iptables
22.查看开放的端口和服务
sudo firewall-cmd --list-all # firewalld
sudo iptables -L -n --line-numbers # iptables5.11 集群部署
下方kubeadm.yaml中name字段必须在网络中可被解析,也可以将解析记录添加到集群中所有机器的/etc/hosts中
这个初始化集群部署的操作只能在k8s-master上执行
这里生产了k8s安装所需要的配置文件,将配置文件中的API服务器地址改成本地的IP,然后集群名字我们用的k8s-master,容器镜像拉取选择了阿里云,为将来的pod网络预留了一个172.16.0.0/16
# 以下步骤仅在master节点完成即可
kubeadm config print init-defaults > kubeadm-config.yaml
# 生产环境中基于安全考虑,一般使用内网IP作为监听地址
# 在云服务器环境中,如果配置了公网 IP 作为监听地址,但该公网IP可能无法在服务器内部直接绑定
sed -i 's/.*advert.*/ advertiseAddress: 10.8.0.13/g' kubeadm-config.yaml
sed -i 's/.*name.*/ name: k8s-master/g' kubeadm-config.yaml
sed -i 's|imageRepo.*|imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers|g' kubeadm-config.yaml
sed -i "/^\\s*networking:/a\\ podSubnet: 172.16.0.0/16" kubeadm-config.yaml
# 解决跨账号的云服务器内网无法通信的问题(生产中不会存在该问题)
# 使用ifconfig命令可以临时为eth0指定IP地址和子网掩码,但重启后配置会失效
ifconfig eth0 192.168.80.111 netmask 255.255.255.0 生成默认配置文件并进行定制:
设置主节点 IP 地址。
设置集群名,这个名称要求集群之间能互相解析。
使用阿里云镜像源加速拉取镜像。
设置 Pod 网段(与 Calico 配置保持一致)。
指定 CRI socket(仅当使用 cri-dockerd 时需要)。
使用 kubeadm init 初始化集群,成功后会输出 kubeadm join 命令,用于添加node节点。
# 以下步骤仅在master节点完成即可
modprobe br_netfilter
kubeadm init --config kubeadm-config.yaml出现下面的提示就是成功了,保存好join的命令
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 10.8.0.13:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:19732328bad4a6bec16004e27bd92803edf5c57517ac1f823138683e447061b6 授权管理权限,将集群配置文件复制到当前用户目录,使 kubectl 能正常访问和管理集群。
# 以下步骤仅在master节点完成即可
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config5.12 部署Calico网络插件
Calico网络插件部署的操作只能在k8s-master上执行
在开始之前,请打开以下calico官方网址,将所有镜像都下载到机器上,不然无法成功
1.Use the following commands to pull the required Calico images.
nerdctl pull quay.io/tigera/operator:v1.38.7
nerdctl pull calico/node:v3.30.4
nerdctl pull calico/cni:v3.30.4
nerdctl pull calico/apiserver:v3.30.4
nerdctl pull calico/kube-controllers:v3.30.4
nerdctl pull calico/envoy-gateway:v3.30.4
nerdctl pull calico/envoy-proxy:v3.30.4
nerdctl pull calico/envoy-ratelimit:v3.30.4
nerdctl pull calico/dikastes:v3.30.4
nerdctl pull calico/pod2daemon-flexvol:v3.30.4
nerdctl pull calico/key-cert-provisioner:v3.30.4
nerdctl pull calico/goldmane:v3.30.4
nerdctl pull calico/whisker:v3.30.4
nerdctl pull calico/whisker-backend:v3.30.4
2.Retag the images with the name of your registry $REGISTRY.
nerdctl tag quay.io/tigera/operator:v1.38.7 harbor.cncf.net:447/library/quay.io/tigera/operator:v1.38.7
nerdctl tag calico/node:v3.30.4 harbor.cncf.net:447/library/calico/node:v3.30.4
nerdctl tag calico/cni:v3.30.4 harbor.cncf.net:447/library/calico/cni:v3.30.4
nerdctl tag calico/apiserver:v3.30.4 harbor.cncf.net:447/library/calico/apiserver:v3.30.4
nerdctl tag calico/kube-controllers:v3.30.4 harbor.cncf.net:447/library/calico/kube-controllers:v3.30.4
nerdctl tag calico/envoy-gateway:v3.30.4 harbor.cncf.net:447/library/calico/envoy-gateway:v3.30.4
nerdctl tag calico/envoy-proxy:v3.30.4 harbor.cncf.net:447/library/calico/envoy-proxy:v3.30.4
nerdctl tag calico/envoy-ratelimit:v3.30.4 harbor.cncf.net:447/library/calico/envoy-ratelimit:v3.30.4
nerdctl tag calico/dikastes:v3.30.4 harbor.cncf.net:447/library/calico/dikastes:v3.30.4
nerdctl tag calico/pod2daemon-flexvol:v3.30.4 harbor.cncf.net:447/library/calico/pod2daemon-flexvol:v3.30.4
nerdctl tag calico/key-cert-provisioner:v3.30.4 harbor.cncf.net:447/library/calico/key-cert-provisioner:v3.30.4
nerdctl tag calico/goldmane:v3.30.4 harbor.cncf.net:447/library/calico/goldmane:v3.30.4
nerdctl tag calico/whisker:v3.30.4 harbor.cncf.net:447/library/calico/whisker:v3.30.4
nerdctl tag calico/whisker-backend:v3.30.4 harbor.cncf.net:447/library/calico/whisker-backend:v3.30.4镜像下载后,用下面这个operator把calico组件给安装上:
kubectl create -f https://raw.gitmirror.com/projectcalico/calico/v3.31.0/manifests/operator-crds.yaml
kubectl create -f https://raw.gitmirror.com/projectcalico/calico/v3.31.0/manifests/tigera-operator.yaml
[root@k8s-master ~]# kubectl create -f https://raw.gitmirror.com/projectcalico/calico/v3.31.0/manifests/tigera-operator.yaml
namespace/tigera-operator created
serviceaccount/tigera-operator created
clusterrole.rbac.authorization.k8s.io/tigera-operator-secrets created
clusterrole.rbac.authorization.k8s.io/tigera-operator created
clusterrolebinding.rbac.authorization.k8s.io/tigera-operator created
rolebinding.rbac.authorization.k8s.io/tigera-operator-secrets created
deployment.apps/tigera-operator created 1.operator-crds.yaml 的作用
这个文件用于部署 Calico Operator 的 CRDs(Custom Resource Definitions,自定义资源定义)。
CRDs 是 Kubernetes 中的一种扩展机制,允许你定义新的资源类型。
operator-crds.yaml 中定义了 Calico Operator 所需的资源类型,比如 Installation、IPPool、FelixConfiguration 等。
这些资源类型是 Calico Operator 管理网络组件的基础,必须先创建它们,Operator 才能识别和处理后续的配置。
简单来说:这是为 Calico Operator 打好“地基”,让 Kubernetes 能识别 Calico 的专属资源类型。
2.custom-resources.yaml 的作用
这个文件是一个 Calico 的自定义资源配置文件,用于告诉 Calico Operator 如何部署和配置网络插件。
它定义了一个 Installation 资源,指定 Calico 的网络模式、IP 地址池等关键参数。
其中的 ipPools 字段设置了 Pod 网络的地址范围(例如 172.16.0.0/16),必须与 kubeadm.yaml 中的 podSubnet 保持一致。
应用该文件后,Calico Operator 会根据这些配置自动部署 Calico 的核心组件(如 calico-node、typha 等)。
简单来说:这是告诉 Calico Operator“怎么部署”,包括网络范围、组件行为等。
用下面的自定义资源设置一下calico在集群中的网段:
wget https://raw.gitmirror.com/projectcalico/calico/v3.31.0/manifests/custom-resources.yaml
[root@k8s-master ~]# wget https://raw.gitmirror.com/projectcalico/calico/v3.31.0/manifests/custom-resources.yaml
# 修改 custom-resources.yaml 中的 cidr 字段,确保与 kubeadm.yaml 中的 podSubnet 保持一致
[root@k8s-master ~]# vim custom-resources.yaml
......
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
ipPools:
- name: default-ipv4-ippool
blockSize: 26
cidr: 172.16.0.0/16 #这里换成上面规定好的172.16.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
......将自定义资源发布到集群中:
应用配置后,Calico 会自动部署网络组件,确保 Pod 间通信正常。
[root@k8s-master ~]# kubectl apply -f custom-resources.yaml
installation.operator.tigera.io/default created
apiserver.operator.tigera.io/default created
goldmane.operator.tigera.io/default created
whisker.operator.tigera.io/default created查询集群组件是否工作正常,正常应该都处于running:
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 4m31s v1.33.5
[root@k8s-master ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
calico-system calico-apiserver-5f5c6bb57f-pm8nv 1/1 Running 0 101s
calico-system calico-apiserver-5f5c6bb57f-s5lk4 1/1 Running 0 101s
calico-system calico-kube-controllers-6857dfcf57-qq6cm 1/1 Running 0 101s
calico-system calico-node-5w4dk 1/1 Running 0 101s
calico-system calico-typha-6db7695558-2jnl5 1/1 Running 0 101s
calico-system csi-node-driver-hdsrb 2/2 Running 0 101s
calico-system goldmane-5cfbfbffd6-4rzdn 1/1 Running 0 101s
calico-system whisker-5bb68b49c4-zr8n8 2/2 Running 0 97s
kube-system coredns-746c97786-bm45f 1/1 Running 0 4m1s
kube-system coredns-746c97786-l5gr2 1/1 Running 0 4m1s
kube-system etcd-k8s-master 1/1 Running 1 4m7s
kube-system kube-apiserver-k8s-master 1/1 Running 1 4m7s
kube-system kube-controller-manager-k8s-master 1/1 Running 2 4m7s
kube-system kube-proxy-56nqb 1/1 Running 0 4m1s
kube-system kube-scheduler-k8s-master 1/1 Running 2 4m7s
tigera-operator tigera-operator-75f6548d76-jqgjt 1/1 Running 0 2m41s6 加入node节点
加入节点操作需在所有的worker节点完成,这里要注意,Worker节点需要完成以下先决条件才能执行kubeadm join:
1.Containerd部署
2.Swap 分区关闭
3.iptables 桥接流量的允许
4.安装kubeadm等软件
5.集成Containerd
6.所有节点的/etc/hosts中互相添加对方的解析
如果时间长忘记了join参数,可以在master节点上用以下方法重新生成
[root@k8s-master ~]# kubeadm token create --print-join-command
kubeadm join 10.8.0.13:6443 --token kuvhy9.67bgyeqcg4jlvngs --discovery-token-ca-cert-hash sha256:19732328bad4a6bec16004e27bd92803edf5c57517ac1f823138683e447061b6如果有多个CRI对象,在worker节点上执行以下命令加入节点时,指定CRI对象,案例如下:
[root@k8s-node1 ~]# kubeadm join 10.8.0.13:6443 --token kuvhy9.67bgyeqcg4jlvngs --discovery-token-ca-cert-hash sha256:19732328bad4a6bec16004e27bd92803edf5c57517ac1f823138683e447061b6 --cri-socket=unix:///run/containerd/containerd.sock
......
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
[root@k8s-node2 ~]# kubeadm join 10.8.0.13:6443 --token g06ne2.xgnj4vw10q0a5qal --discovery-token-ca-cert-hash sha256:19732328bad4a6bec16004e27bd92803edf5c57517ac1f823138683e447061b6 --cri-socket=unix:///run/containerd/containerd.sock
......
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.注意上描述命令最后的–cri-socket参数,在系统中部署了docker和cri-docker时,必须明确指明此参数,并将此参数指向我们的cri-docker,不然命令会报告有两个重复的CRI的错误,而我们部署的是containerd,就没这个问题
在master机器上执行以下内容给节点打上node角色标签,便于资源调度和管理。
kubectl label nodes k8s-node1 node-role.kubernetes.io/node=
kubectl get nodes
[root@k8s-master ~]# kubectl label nodes k8s-node1 node-role.kubernetes.io/node1=
node/k8s-node1 labeled
[root@k8s-master ~]# kubectl label nodes k8s-node2 node-role.kubernetes.io/node2=
node/k8s-node2 labeled
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 6h2m v1.33.5
k8s-node1 Ready node1 5h56m v1.33.5
k8s-node2 Ready node2 41m v1.33.6
[root@k8s-master ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master Ready control-plane 6h3m v1.33.5 10.8.0.13 <none> Rocky Linux 9.6 (Blue Onyx) 5.14.0-570.58.1.el9_6.x86_64 containerd://2.1.4
k8s-node1 Ready node1 5h58m v1.33.5 10.8.0.14 <none> Rocky Linux 9.6 (Blue Onyx) 5.14.0-570.58.1.el9_6.x86_64 containerd://2.1.4
k8s-node2 Ready node2 42m v1.33.6 10.8.0.16 <none> Rocky Linux 9.6 (Blue Onyx) 5.14.0-503.15.1.el9_5.x86_64 containerd://2.1.4开放node节点的防火墙:
# 开启 IP 隧道协议(IP-in-IP)
sudo firewall-cmd --zone=public --add-protocol=ipip --permanent
# 开启 BGP 所需的 TCP 179 端口
sudo firewall-cmd --zone=public --add-port=179/tcp --permanent
# 开启 VXLAN 所需的 UDP 4789 端口
sudo firewall-cmd --zone=public --add-port=4789/udp --permanent
# 开启 Wireguard 所需的 UDP 51820 端口
sudo firewall-cmd --zone=public --add-port=51820/udp --permanent
# 开启 IPv6 Wireguard 所需的 UDP 51821 端口
sudo firewall-cmd --zone=public --add-port=51821/udp --permanent
# 开启 Typha 代理所需的 TCP 5473 端口
sudo firewall-cmd --zone=public --add-port=5473/tcp --permanent
# 开启 Kubernetes API (kube-apiserver) 所需的 TCP 443 和 6443 端口
sudo firewall-cmd --zone=public --add-port=443/tcp --permanent
sudo firewall-cmd --zone=public --add-port=6443/tcp --permanent
# 开启 Calico Enterprise API 服务器所需的 TCP 8080 和 5443 端口
sudo firewall-cmd --zone=public --add-port=8080/tcp --permanent
sudo firewall-cmd --zone=public --add-port=5443/tcp --permanent
# 开启 calico-node (Felix, BIRD, confd) 所需的 TCP 9090 端口
sudo firewall-cmd --zone=public --add-port=9090/tcp --permanent
# 开启 Prometheus 指标所需的 TCP 9081 端口
sudo firewall-cmd --zone=public --add-port=9081/tcp --permanent
# 开启 Prometheus BGP 指标所需的 TCP 9900 端口
sudo firewall-cmd --zone=public --add-port=9900/tcp --permanent
# 开启 Elasticsearch with fluentd 数据存储所需的 TCP 9200 端口
sudo firewall-cmd --zone=public --add-port=9200/tcp --permanent
# 开启 Elasticsearch 云 (ECK) 所需的 TCP 9443 端口
sudo firewall-cmd --zone=public --add-port=9443/tcp --permanent
# 开启 Elasticsearch 网关所需的 TCP 5444 端口
sudo firewall-cmd --zone=public --add-port=5444/tcp --permanent
# 开启 Kibana 所需的 TCP 5601 端口
sudo firewall-cmd --zone=public --add-port=5601/tcp --permanent
# 开启 数据包捕获 API 所需的 TCP 8444 端口
sudo firewall-cmd --zone=public --add-port=8444/tcp --permanent
# 开启 Calico Enterprise Manager UI 所需的 TCP 9443 端口
sudo firewall-cmd --zone=public --add-port=9443/tcp --permanent
# 开启 多集群管理所需的 TCP 9449 端口
sudo firewall-cmd --zone=public --add-port=9449/tcp --permanent
# 开启 出口网关所需的 UDP 4790 端口
sudo firewall-cmd --zone=public --add-port=4790/udp --permanent
# 重新加载防火墙配置,使更改生效
sudo firewall-cmd --reload一定要开通端口,不然calico的node pod会报告这些日志
2025-05-23 09:26:26.390 [INFO][4264] tunnel-ip-allocator/discovery.go 188: (Re)discovering Typha endpoints using the Kubernetes API...
W0523 09:26:26.393216 4264 warnings.go:70] v1 Endpoints is deprecated in v1.33+; use discovery.k8s.io/v1 EndpointSlice
2025-05-23 09:26:26.393 [INFO][4264] tunnel-ip-allocator/discovery.go 243: Found ready Typha addresses. addresses=[]discovery.Typha{discovery.Typha{Addr:"10.0.0.9:5473", IP:"10.0.", NodeName:(*string)(0xc000b31790)}}
2025-05-23 09:26:26.393 [FATAL][4264] tunnel-ip-allocator/startsyncerclient.go 86: Failed to connect to Typha error=failed to load next Typha address to try: tried all available discovered addresses7 确认集群状态
#这里的pod必须是全部running 到此已经成功部署了k8s集群
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 6h2m v1.33.5
k8s-node1 Ready node1 5h56m v1.33.5
k8s-node2 Ready node2 41m v1.33.6
[root@k8s-master ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
calico-system calico-apiserver-5f5c6bb57f-pm8nv 1/1 Running 0 6h2m
calico-system calico-apiserver-5f5c6bb57f-s5lk4 1/1 Running 0 6h2m
calico-system calico-kube-controllers-6857dfcf57-qq6cm 1/1 Running 0 6h2m
calico-system calico-node-5w4dk 1/1 Running 0 6h2m
calico-system calico-node-bhb2x 1/1 Running 0 5h59m
calico-system calico-node-l5bpc 1/1 Running 0 43m
calico-system calico-typha-6db7695558-2jnl5 1/1 Running 0 6h2m
calico-system calico-typha-6db7695558-lrcnl 1/1 Running 0 43m
calico-system csi-node-driver-5bctz 2/2 Running 0 5h59m
calico-system csi-node-driver-c46wz 2/2 Running 0 43m
calico-system csi-node-driver-hdsrb 2/2 Running 0 6h2m
calico-system goldmane-5cfbfbffd6-4rzdn 1/1 Running 0 6h2m
calico-system whisker-5bb68b49c4-zr8n8 2/2 Running 0 6h2m
kube-system coredns-746c97786-bm45f 1/1 Running 0 6h4m
kube-system coredns-746c97786-l5gr2 1/1 Running 0 6h4m
kube-system etcd-k8s-master 1/1 Running 1 6h5m
kube-system kube-apiserver-k8s-master 1/1 Running 1 6h5m
kube-system kube-controller-manager-k8s-master 1/1 Running 2 6h5m
kube-system kube-proxy-56nqb 1/1 Running 0 6h4m
kube-system kube-proxy-5ww8g 1/1 Running 0 43m
kube-system kube-proxy-w4hdn 1/1 Running 0 5h59m
kube-system kube-scheduler-k8s-master 1/1 Running 2 6h5m
tigera-operator tigera-operator-75f6548d76-jqgjt 1/1 Running 0 6h3m8 重置集群
如果在安装好集群的情况下,想重复练习初始化集群,或者包括初始化集群报错在内的任何原因,想重新初始化集群时,可以用下面的方法重置集群,重置后,集群就会被删除,可以用于重新部署,一般来说,这个命令仅用于k8s-master这个节点
1.kubeadm reset 清除集群配置。
2.手动清理 CNI 网络配置、iptables 规则和 kubeconfig 文件。
3.清理后可重新部署集群
[root@k8s-master ~]# kubeadm reset --cri-socket=unix:///run/containerd/containerd.sock
...
[reset] Are you sure you want to proceed? [y/N]: y
...
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the "iptables" command.
If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar)
to reset your system's IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.
# 根据提示,手工完成文件和规则的清理
[root@k8s-master ~]# rm -rf /etc/cni/net.d
[root@k8s-master ~]# iptables -F
[root@k8s-master ~]# rm -rf $HOME/.kube/config
# 清理后就可以重新部署集群了9 K8S集群节点剔除与加入
9.1 安全剔除节点
9.1.1 准备工作
# 查看当前集群节点状态
kubectl get nodes
# 查看节点详细信息
kubectl describe node <node-name>
# 检查节点上的Pod
kubectl get pods -o wide --all-namespaces | grep <node-name>9.1.2 安全驱逐节点上的pod
# 将节点标记为不可调度(cordon)
kubectl cordon <node-name>
# 驱逐节点上的所有Pod(drain)
kubectl drain <node-name> \
--ignore-daemonsets \
--delete-emptydir-data \
--force \
--grace-period=300
# 参数说明:
# --ignore-daemonsets: 忽略DaemonSet管理的Pod
# --delete-emptydir-data: 删除emptyDir数据
# --force: 强制驱逐
# --grace-period: 优雅终止时间(秒)9.1.3 验证驱逐完成
# 检查节点上是否还有用户Pod
kubectl get pods --all-namespaces -o wide --field-selector spec.nodeName=<node-name>
# 检查节点状态
kubectl get node <node-name>9.1.4 集群中删除节点
# 从集群中删除节点
kubectl delete node <node-name>
# 验证节点已删除
kubectl get nodes9.2 节点重置清理
在被剔除的节点上执行清理操作
9.2.1 重置kubeadm
# 重置kubeadm
sudo kubeadm reset -f
# 清理网络配置
sudo ip link delete cni0
sudo ip link delete flannel.1
# 清理iptables规则
sudo iptables -F && sudo iptables -t nat -F && sudo iptables -t mangle -F && sudo iptables -X
# 清理IPVS规则
sudo ipvsadm -C 2>/dev/null || true9.2.2 清理文件和目录
# 删除Kubernetes相关目录
sudo rm -rf /etc/cni /etc/kubernetes /var/lib/etcd /var/lib/kubelet \
/var/lib/dockershim /var/run/kubernetes /var/lib/cni \
~/.kube /opt/cni
# 清理容器运行时
sudo docker system prune -a -f 2>/dev/null || true
# 如果是containerd
sudo ctr -n k8s.io containers list -q | xargs -r sudo ctr -n k8s.io containers delete
sudo ctr -n k8s.io images list -q | xargs -r sudo ctr -n k8s.io images delete9.2.3 清理网略配置(可选)
# 清理残留网络接口
sudo ip link list | grep -E 'calico|flannel|cni' | awk -F: '{print $2}' | xargs -r -I {} sudo ip link delete {}
# 清理路由表
sudo ip route show | grep -E 'calico|flannel' | awk '{print $1}' | xargs -r -I {} sudo ip route delete {}9.3 重新加入集群
9.3.1 控制平面获取加入命令
# 生成新的token(如果需要)
kubeadm token create
# 获取discovery-token-ca-cert-hash
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
# 直接打印加入命令(推荐)
kubeadm token create --print-join-command
# 输出示例
kubeadm join 192.168.1.100:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:1234567890abcdef...9.3.2 工作节点执行加入命令
# 执行加入命令(使用上面获取的命令)
sudo kubeadm join <control-plane-ip>:6443 \
--token <token> \
--discovery-token-ca-cert-hash sha256:<hash>
# 如果token过期,可以生成新的
sudo kubeadm join <control-plane-ip>:6443 \
--token <new-token> \
--discovery-token-ca-cert-hash sha256:<hash>9.3.3 验证节点加入
在控制平面节点检查
# 查看节点状态
kubectl get nodes
# 查看节点详细信息
kubectl describe node <node-name>
# 检查节点是否就绪
kubectl wait --for=condition=Ready node/<node-name> --timeout=300s9.4 自动化脚本
9.4.1 安全剔除节点脚本
# reove-node.sh
#!/bin/bash
set -e
NODE_NAME=$1
TIMEOUT=300
if [ -z "$NODE_NAME" ]; then
echo "用法: $0 <节点名称>"
exit 1
fi
echo "=== 开始安全剔除节点: $NODE_NAME ==="
# 检查节点是否存在
if ! kubectl get node "$NODE_NAME" &> /dev/null; then
echo "错误: 节点 $NODE_NAME 不存在"
exit 1
fi
# 标记为不可调度
echo "1. 标记节点为不可调度..."
kubectl cordon "$NODE_NAME"
# 驱逐Pod
echo "2. 驱逐节点上的Pod..."
kubectl drain "$NODE_NAME" \
--ignore-daemonsets \
--delete-emptydir-data \
--force \
--grace-period=120 \
--timeout="${TIMEOUT}s"
# 从集群删除
echo "3. 从集群中删除节点..."
kubectl delete node "$NODE_NAME"
echo "=== 节点 $NODE_NAME 已安全剔除 ==="
echo "请在目标节点上执行清理操作"9.4.2 节点重置脚本
# reset-node.sh
#!/bin/bash
set -e
echo "=== 开始重置Kubernetes节点 ==="
# 重置kubeadm
echo "1. 重置kubeadm..."
sudo kubeadm reset -f
# 清理网络
echo "2. 清理网络配置..."
sudo ip link delete cni0 2>/dev/null || true
sudo ip link delete flannel.1 2>/dev/null || true
# 清理iptables
echo "3. 清理iptables规则..."
sudo iptables -F && sudo iptables -t nat -F && sudo iptables -t mangle -F && sudo iptables -X
# 清理IPVS
echo "4. 清理IPVS规则..."
sudo ipvsadm -C 2>/dev/null || true
# 清理文件
echo "5. 清理Kubernetes文件..."
sudo rm -rf /etc/cni /etc/kubernetes /var/lib/etcd /var/lib/kubelet \
/var/lib/dockershim /var/run/kubernetes /var/lib/cni \
~/.kube
# 清理容器
echo "6. 清理容器..."
if command -v docker &> /dev/null; then
sudo docker system prune -a -f
elif command -v ctr &> /dev/null; then
sudo ctr -n k8s.io containers list -q | xargs -r sudo ctr -n k8s.io containers delete
sudo ctr -n k8s.io images list -q | xargs -r sudo ctr -n k8s.io images delete
fi
echo "=== 节点重置完成 ==="
echo "现在可以重新加入集群"9.5 特殊情况处理
9.5.1 节点卡在NotReady状态
# 强制删除节点
kubectl delete node <node-name> --force --grace-period=0
# 清理finalizers(如果节点删除卡住)
kubectl patch node <node-name> -p '{"metadata":{"finalizers":null}}' --type=merge9.5.2 处理残留的pod
# 强制删除残留Pod
kubectl delete pod <pod-name> --force --grace-period=0 --namespace <namespace>
# 清理所有未知状态的Pod
kubectl get pods --all-namespaces --field-selector status.phase=Failed -o json | \
kubectl delete -f -9.5.3 Token过期处理
# 生成新的token
kubeadm token create
# 或者重新生成完整的加入命令
kubeadm token create --print-join-command
# 如果需要重新生成CA hash
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'9.6 验证集群健康状态
节点重新加入后,验证集群状态
# 检查所有节点状态
kubectl get nodes -o wide
# 检查核心组件状态
kubectl get componentstatuses
# 检查所有命名空间的Pod状态
kubectl get pods --all-namespaces
# 检查网络插件
kubectl get pods -n kube-system -l k8s-app=kube-proxy
kubectl get pods -n kube-system -l k8s-app=flannel # 或calico-node等
# 运行集群健康检查
kubectl cluster-info
kubectl get cs10 Kubernetes Dashboard
10.1 前置环境检查
首先检查集群状态
# 检查节点状态
kubectl get nodes -o wide
[root@k8s-master ~]# kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master Ready control-plane 8d v1.33.5 10.8.0.13 <none> Rocky Linux 9.6 (Blue Onyx) 5.14.0-570.58.1.el9_6.x86_64 containerd://2.1.4
k8s-node1 Ready node1 8d v1.33.5 10.8.0.14 <none> Rocky Linux 9.6 (Blue Onyx) 5.14.0-570.58.1.el9_6.x86_64 containerd://2.1.4
k8s-node2 Ready node2 7d20h v1.33.6 10.8.0.16 <none> Rocky Linux 9.6 (Blue Onyx) 5.14.0-570.58.1.el9_6.x86_64 containerd://2.1.4
# 检查集群组件状态
kubectl get cs
[root@k8s-master ~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy ok
# 检查当前命名空间
kubectl get ns
[root@k8s-master ~]# kubectl get ns
NAME STATUS AGE
calico-system Active 8d
cattle-fleet-system Active 50m
cattle-impersonation-system Active 52m
cattle-system Active 56m
default Active 8d
kube-node-lease Active 8d
kube-public Active 8d
kube-system Active 8d
local Active 51m
tigera-operator Active 8d10.2 部署 Kubernetes Dashboard
10.2.1 创建专用命名空间
kubectl create namespace kubernetes-dashboard
[root@k8s-master ~]# kubectl create namespace kubernetes-dashboard
namespace/kubernetes-dashboard created10.2.2 部署 Dashboard
# 使用最新版本的 Dashboard
[root@k8s-master ~]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml -O kubernetes-kuboard.yaml
# 镜像处理
193行:
image: kubernetesui/dashboard:v2.7.0
mirrors.harbor.com:446/kubernetesui/dashboard:v2.7.0
278行:
image: kubernetesui/metrics-scraper:v1.0.8
mirrors.harbor.com:446/kubernetesui/metrics-scraper:v1.0.8
[root@k8s-master ~]# kubectl apply -f kubernetes-kuboard.yaml10.2.3 验证部署状态
# 检查 Pod 状态
kubectl get pods -n kubernetes-dashboard
[root@k8s-master ~]# kubectl get pods -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-5ff567bc4b-llxz9 1/1 Running 0 4h58m
kubernetes-dashboard-7748c965b6-rwk9t 1/1 Running 0 4h54m
# 检查 Service 状态
kubectl get svc -n kubernetes-dashboard
[root@k8s-master ~]# kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.99.193.99 <none> 8000/TCP 5h10m
kubernetes-dashboard ClusterIP 10.102.116.50 <none> 443/TCP 5h10m
# 查看详细部署信息
kubectl describe deployment kubernetes-dashboard -n kubernetes-dashboard
[root@k8s-master ~]# kubectl describe deployment kubernetes-dashboard -n kubernetes-dashboard
Name: kubernetes-dashboard
Namespace: kubernetes-dashboard
CreationTimestamp: Sat, 22 Nov 2025 11:25:24 +0800
Labels: k8s-app=kubernetes-dashboard
Annotations: deployment.kubernetes.io/revision: 1
Selector: k8s-app=kubernetes-dashboard
Replicas: 1 desired | 1 updated | 1 total | 1 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: k8s-app=kubernetes-dashboard
Service Account: kubernetes-dashboard
Containers:
kubernetes-dashboard:
Image: mirrors.harbor.com:446/kubernetesui/dashboard:v2.7.0
Port: 8443/TCP
Host Port: 0/TCP
Args:
--auto-generate-certificates
--namespace=kubernetes-dashboard
Liveness: http-get https://:8443/ delay=30s timeout=30s period=10s #success=1 #failure=3
Environment: <none>
Mounts:
/certs from kubernetes-dashboard-certs (rw)
/tmp from tmp-volume (rw)
Volumes:
kubernetes-dashboard-certs:
Type: Secret (a volume populated by a Secret)
SecretName: kubernetes-dashboard-certs
Optional: false
tmp-volume:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: <unset>
Node-Selectors: kubernetes.io/os=linux
Tolerations: node-role.kubernetes.io/master:NoSchedule
Conditions:
Type Status Reason
---- ------ ------
Progressing True NewReplicaSetAvailable
Available True MinimumReplicasAvailable
OldReplicaSets: <none>
NewReplicaSet: kubernetes-dashboard-7748c965b6 (1/1 replicas created)
Events: <none>10.3 配置安全访问
10.3.1 创建管理员 ServiceAccount
创建 dashboard-admin.yaml 文件:
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard-admin
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: dashboard-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: dashboard-admin
namespace: kubernetes-dashboard应用配置:
kubectl apply -f dashboard-admin.yaml10.3.2 获取访问令牌
# 获取 token
# 保存输出的 token,后续访问需要使用。
kubectl -n kubernetes-dashboard create token dashboard-admin
[root@k8s-master ~]# kubectl -n kubernetes-dashboard create token dashboard-admin
eyJhbGciOiJSUzI1NiIsImtpZCI6Il9DR09yMExLUGNwZVE5bUJ6SkJPbml4QkRWdi1FQmZ3UnBLY3MtMkd2d2MifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzYzODIzODEyLCJpYXQiOjE3NjM4MjAyMTIsImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlcy5kZWZhdWx0LnN2Yy5jbHVzdGVyLmxvY2FsIiwianRpIjoiNDA2MzliOWYtNGM0MC00MjdlLWE5YjQtZGQyMjMxNTljNTcyIiwia3ViZXJuZXRlcy5pbyI6eyJuYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsInNlcnZpY2VhY2NvdW50Ijp7Im5hbWUiOiJkYXNoYm9hcmQtYWRtaW4iLCJ1aWQiOiI3NzU2ZjczMy03MjcxLTQ2NGEtOTlmNy03NDFlZjhhODJiZGEifX0sIm5iZiI6MTc2MzgyMDIxMiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.G1abBHR63pS-RdK_Rkw9g7x4TbAgSBT_aRrqigcUCi5Y3XTU90o5kOajR-KX9bIbeeM7rsG7_FItdCARkn1hRJn2RoEMgfFfYhREcHcVO2xJ253xwJ6YIriYW73hCpEwfWJNTNksaLzsniphgrbAEGsVmyHqoWSZOZUvJyKtp3kBW-tCNYbXp5l8sb-A303KkR1t16gfpssUjDDVob_QPCMWrOMgH04DHV0L5Tw4_o8-YBa0nj9ox7yq8AhkpRSjRYjCGu-Mam6ZxFHNloJE5Ai2eT842iFC6CdJtenzdYgtAtHi2GM-WR77mQGP8N1yLtUJFEitLHrL-LQcBmcOQw10.4 配置外部访问
10.4.1 修改 Service 为 NodePort 类型
kubectl patch svc kubernetes-dashboard -n kubernetes-dashboard -p '{"spec": {"type": "NodePort"}}'
[root@k8s-master ~]# kubectl patch svc kubernetes-dashboard -n kubernetes-dashboard -p '{"spec": {"type": "NodePort"}}'
service/kubernetes-dashboard patched10.4.2 获取访问端口
kubectl get svc kubernetes-dashboard -n kubernetes-dashboard
[root@k8s-master ~]# kubectl get svc kubernetes-dashboard -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.102.116.50 <none> 443:31559/TCP 10h10.4.3 创建 Ingress 资源
创建 dashboard-ingress.yaml:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: dashboard-ingress
namespace: kubernetes-dashboard
annotations:
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
nginx.ingress.kubernetes.io/ssl-passthrough: "true"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
spec:
ingressClassName: nginx
rules:
- host: dashboard.k8s.com # 替换为您的域名
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kubernetes-dashboard
port:
number: 443应用 Ingress:
kubectl apply -f dashboard-ingress.yaml
[root@k8s-master ~]# kubectl apply -f dashboard-ingress.yaml
ingress.networking.k8s.io/dashboard-ingress created10.5 安全加固配置
10.5.1 创建网络策略
创建 dashboard-network-policy.yaml:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: dashboard-network-policy
namespace: kubernetes-dashboard
spec:
podSelector:
matchLabels:
k8s-app: kubernetes-dashboard
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
name: kubernetes-dashboard
ports:
- protocol: TCP
port: 8443
- from:
- ipBlock:
cidr: 10.8.0.0/24 # 只允许内网访问
ports:
- protocol: TCP
port: 8443
[root@k8s-master ~]# kubectl apply -f dashboard-network-policy.yaml
networkpolicy.networking.k8s.io/dashboard-network-policy created10.5.2 配置资源限制
更新 Dashboard 部署的资源限制:
kubectl patch deployment kubernetes-dashboard -n kubernetes-dashboard -p '
{
"spec": {
"template": {
"spec": {
"containers": [
{
"name": "kubernetes-dashboard",
"resources": {
"limits": {
"cpu": "500m",
"memory": "512Mi"
},
"requests": {
"cpu": "100m",
"memory": "128Mi"
}
}
}
]
}
}
}
}'10.6 Windows Chrome 浏览器访问配置
10.6.1 配置本地 hosts 文件
在 Windows 的 C:\Windows\System32\drivers\etc\hosts 文件中添加:
49.235.53.189 dashboard.k8s.com10.6.2 端口转发访问
如果使用 NodePort,执行端口转发:
# 在 k8s-master 上执行
# 创建服务文件
cat > /etc/systemd/system/dashboard-portforward.service << 'EOF'
[Unit]
Description=Kubernetes Dashboard Port Forward
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usrbin/kubectl port-forward -n kubernetes-dashboard service/kubernetes-dashboard 8443:443 --address 0.0.0.0
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
EOF
# 重新加载 systemd
systemctl daemon-reload
# 启动服务
systemctl start dashboard-portforward
# 设置开机自启
systemctl enable dashboard-portforward
# 查看服务状态
systemctl status dashboard-portforward
# 查看服务日志
journalctl -u dashboard-portforward -f10.7 访问 Dashboard
# 访问地址:https://49.235.53.189:8443、https://dashboard.k8s.com
1.在 Chrome 浏览器中访问:https://dashboard.k8s.com
2. 选择 Token 认证方式
3.粘贴之前获取的管理员 token
4.点击登录
13. 监控和维护10.8 创建监控配置
# 检查 Dashboard 运行状态
kubectl get pods -n kubernetes-dashboard -w
# 查看日志
kubectl logs -n kubernetes-dashboard -l k8s-app=kubernetes-dashboard10.9 设置自动重启策略
kubectl patch deployment kubernetes-dashboard -n kubernetes-dashboard -p '
{
"spec": {
"template": {
"spec": {
"containers": [
{
"name": "kubernetes-dashboard",
"livenessProbe": {
"httpGet": {
"path": "/",
"port": 9090,
"scheme": "HTTP"
},
"initialDelaySeconds": 30,
"timeoutSeconds": 30
},
"readinessProbe": {
"httpGet": {
"path": "/",
"port": 9090,
"scheme": "HTTP"
},
"initialDelaySeconds": 5,
"timeoutSeconds": 3
}
}
]
}
}
}
}'10.11 关于登录
# 创建 ServiceAccount(如果还没有)
kubectl -n kubernetes-dashboard create serviceaccount dashboard-admin
# 创建 ClusterRoleBinding
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:dashboard-admin
# 获取 token
TOKEN=$(kubectl -n kubernetes-dashboard create token dashboard-admin --duration=87600h)
# 创建 kubeconfig 文件
cat > /root/dashboard-kubeconfig.yaml << EOF
apiVersion: v1
kind: Config
clusters:
- name: kubernetes
cluster:
certificate-authority-data: $(kubectl get secret -n kubernetes-dashboard $(kubectl get serviceaccount dashboard-admin -n kubernetes-dashboard -o jsonpath='{.secrets[0].name}') -o jsonpath='{.data.ca\.crt}')
server: https://$(kubectl get nodes -o jsonpath='{.items[0].status.addresses[0].address}'):6443
users:
- name: dashboard-admin
user:
token: $TOKEN
contexts:
- name: dashboard-admin@kubernetes
context:
cluster: kubernetes
user: dashboard-admin
current-context: dashboard-admin@kubernetes
EOF10.12 故障排查
常见问题解决:
# 1. 检查证书问题
kubectl get secrets -n kubernetes-dashboard
# 2. 检查服务发现
kubectl get endpoints -n kubernetes-dashboard
# 3. 检查节点端口分配
kubectl get nodes -o wide
netstat -tlnp | grep <node-port>
# 4. 重置 Dashboard(如果需要)
kubectl delete -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml10.13 安全建议
- 定期轮换 token
- 使用 VPN 访问而非直接暴露公网
- 启用审计日志
- 配置网络策略限制访问源
- 定期更新 Dashboard 版本
