1 微服务
把一个庞大的应用拆成几个小的独立的服务,再把独立的服务串起来的一种架构设计:内聚更强,更加敏捷
1.1 应用架构的发展
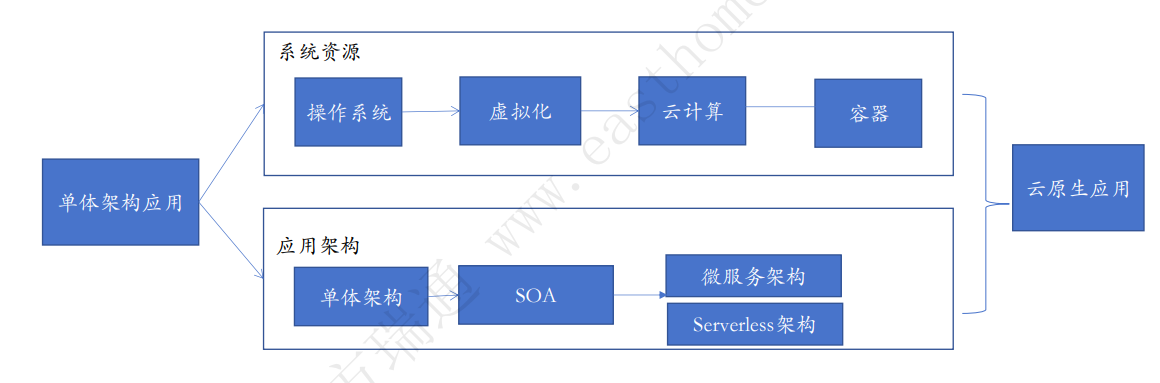
1.2 传统单体架构vs微服务软件架构
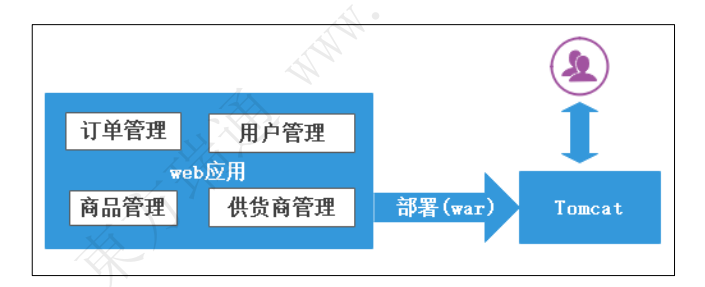
不同于微服务,传统的项目会包含很多功能,是一个大而全的“超级”工程
例如:以普通架构方式实现的电商平台包含:登录、权限、会员、商品库存、订单、收藏、关注、购物车等功能的多个单一项目。随着项目业务越来越复杂、开发人员越来越多,相应开发、编译、部署、技术扩展、水平扩展都会受到限制
1.3 基于微服务的系统架构
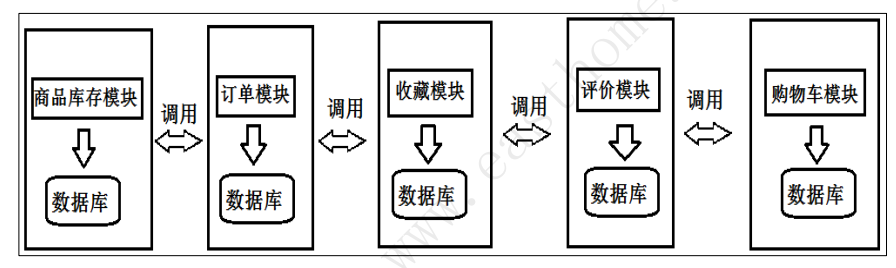
核心思路是拆分
单体项目的问题,通过把项目拆分成一个个小项目就可以解决
1.4 微服务的特征
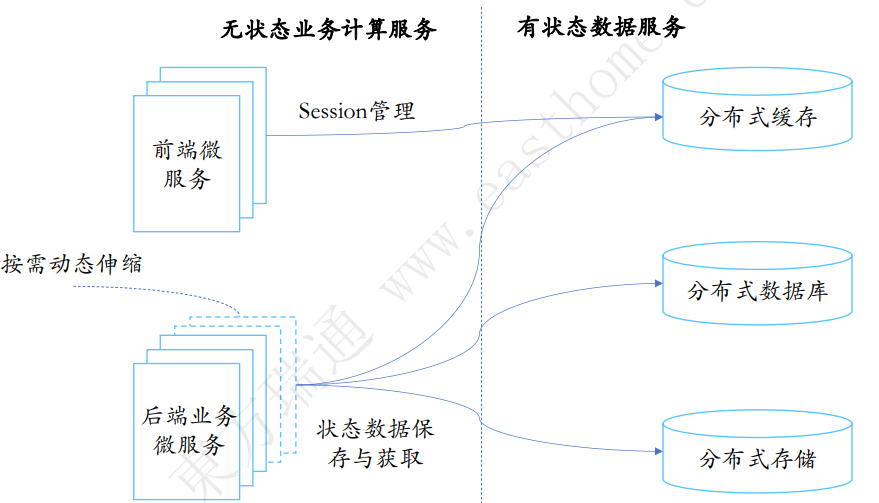
1.5 单体架构
紧耦合面临的问题:故障影响范围大、变更成本高、无法支持大规模计算
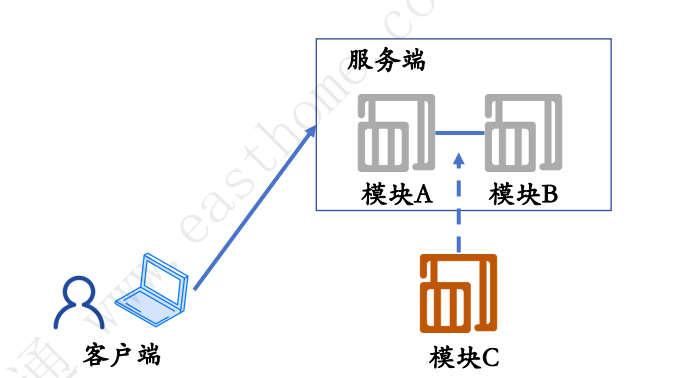
如果需要加入模块C,需要更改模块A、B的代码,需要各个系统人员协调处理
1.6 解耦架构
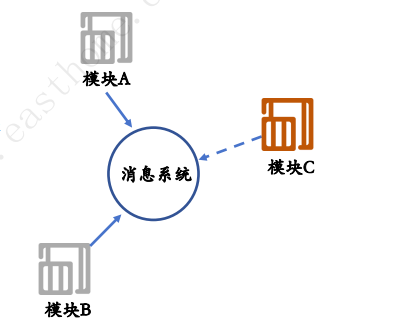
解耦架构的优势:
1.模块化,缩小故障范围
2.降低变更成本,插入新模块不影响其他模块
3.开发人员协作更简单
4.易于扩展
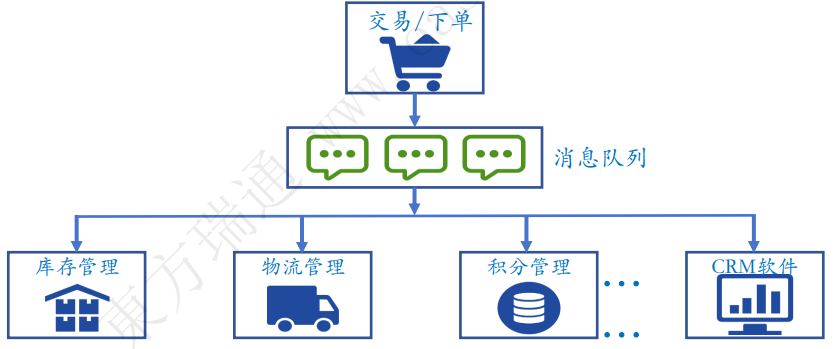
1.7 消息队列
1.7.1 传统架构

1.7.2 消息队列架构
1.8 微服务面临的挑战
| 单体架构 | 微服务架构 | |
|---|---|---|
| 迭代速度 | 较慢 | 快 |
| 部署频率 | 不经常部署 | 经常发布 |
| 系统性能 | 吞吐量小 | 吞吐量大 |
| 系统扩展性 | 扩展性差 | 扩展性好 |
| 技术栈多样性 | 单一、封闭 | 多样、开放 |
| 运维 | 简单 | 运维复杂 |
| 部署难度 | 容易部署 | 较难部署 |
| 架构复杂度 | 较小 | 复杂度高 |
| 查错 | 简单 | 定位问题较难 |
| 管理成本 | 主要在于开发成本 | 服务治理、运维 |
1.9 虚拟机与容器的比较
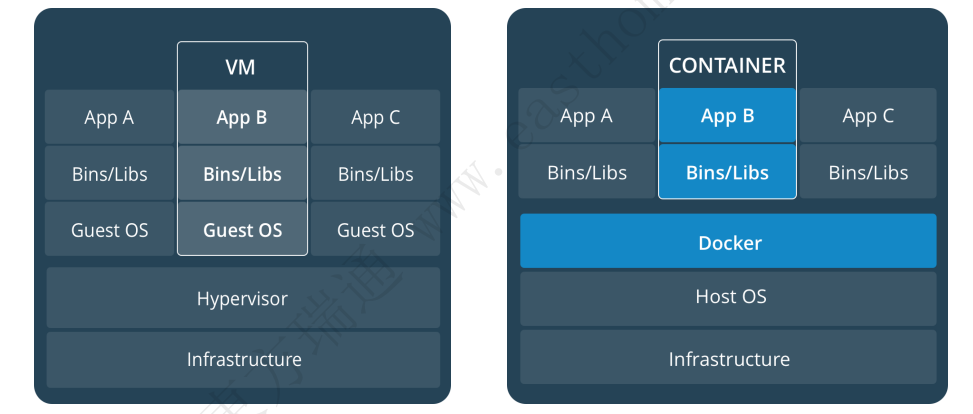
| 对比模块 | 虚拟机 | 容器 |
|---|---|---|
| 占用空间 | 非常大,GB级别 | 小,MB/KB级别 |
| 启用速度 | 慢,分钟级 | 快,秒级 |
| 运行形态 | 运行于Hypervisor | 直接运行在宿主机内核上 |
| 并发性 | 一台宿主机上十几个,最多几 十个 | 上百个,甚至数百个 |
| 性能 | 低于宿主机 | 接近于宿主机本地进程 |
| 资源利用率 | 低 | 高 |
2 容器的基本使用
2.1 容器介绍
容器是一个可以在共享的操作系统上将应用程序以指定格式打包并运行在一个与操作系统相关联的环境中的方法
和虚拟机相比,容器并不会打包整个操作系统,而只是打包应用程序所必须的库和设置,这将使得容器具备高效率、轻量化、系统隔离性,以上特性将会确保无论在何处部署,容器每次运行都会完全一致
容器工具:Rkt、Containerd、Docker、Podman
2.2 部署Docker
从南京大学开源镜像站在Ubuntu上安装docker
2.2.1 安装依赖
# 检测系统是否安装了docker
root@k8s-master:~# for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg; done
# 安装依赖
root@k8s-master:~# sudo apt-get update
root@k8s-master:~# sudo apt-get install ca-certificates curl gnupg2.2.2 安装GPG公钥
root@k8s-master:~# sudo install -m 0755 -d /etc/apt/keyrings
root@k8s-master:~# curl -fsSL https://mirror.nju.edu.cn/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
root@k8s-master:~# sudo chmod a+r /etc/apt/keyrings/docker.gpg2.2.3 添加Docker仓库
root@k8s-master:~# echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirror.nju.edu.cn/docker-ce/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null2.2.4 安装Docker
root@k8s-master:~# sudo apt-get update
root@k8s-master:~# sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 拉取失败,因此在中国需要加速器
root@k8s-master:~# sudo docker run hello-world
Unable to find image 'hello-world:latest' locally
docker: Error response from daemon: Get "https://registry-1.docker.io/v2/": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
Run 'docker run --help' for more information2.2.5 Docker镜像加速器
root@k8s-master:~# mkdir -p /etc/docker
root@k8s-master:~# cd /etc/docker
root@k8s-master:/etc/docker# vim daemon.json
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://mirror.ccs.tencentyun.com",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://mirror.gcr.io",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com"
],
"exec-opts": ["native.cgroupdriver=systemd"]
}
root@k8s-master:~# systemctl daemon-reload
root@k8s-master:~# systemctl restart docker
root@k8s-master:~# sudo docker pull hello-world
Using default tag: latest
latest: Pulling from library/hello-world
Digest: sha256:c41088499908a59aae84b0a49c70e86f4731e588a737f1637e73c8c09d995654
Status: Image is up to date for hello-world:latest
docker.io/library/hello-world:latest
root@k8s-master:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest 74cc54e27dc4 3 months ago 10.1kB2.2.6 重启Docker服务
root@k8s-master:~# systemctl restart docker
root@k8s-master:~# docker info
Client: Docker Engine - Community
Version: 28.1.1
Context: default
Debug Mode: false
Plugins:
buildx: Docker Buildx (Docker Inc.)
Version: v0.23.0
Path: /usr/libexec/docker/cli-plugins/docker-buildx
compose: Docker Compose (Docker Inc.)
Version: v2.35.1
Path: /usr/libexec/docker/cli-plugins/docker-compose
Server:
Containers: 2
Running: 1
Paused: 0
Stopped: 1
Images: 2
Server Version: 28.1.1
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Using metacopy: false
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: systemd
Cgroup Version: 2
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local splunk syslog
Swarm: inactive
Runtimes: io.containerd.runc.v2 runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 05044ec0a9a75232cad458027ca83437aae3f4da
runc version: v1.2.5-0-g59923ef
init version: de40ad0
Security Options:
apparmor
seccomp
Profile: builtin
cgroupns
Kernel Version: 6.8.0-53-generic
Operating System: Ubuntu 24.04.2 LTS
OSType: linux
Architecture: x86_64
CPUs: 2
Total Memory: 3.777GiB
Name: k8s-master
ID: 6c5b4dc6-423d-47e6-a687-e75062cf4fd9
Docker Root Dir: /var/lib/docker
Debug Mode: false
Experimental: false
Insecure Registries:
::1/128
127.0.0.0/8
Registry Mirrors:
https://docker.mirrors.ustc.edu.cn/
https://mirror.baidubce.com/
https://docker.m.daocloud.io/
https://mirror.ccs.tencentyun.com/
https://docker.nju.edu.cn/
https://docker.mirrors.sjtug.sjtu.edu.cn/
https://mirror.gcr.io/
https://docker.registry.cyou/
https://docker-cf.registry.cyou/
https://dockercf.jsdelivr.fyi/
https://docker.jsdelivr.fyi/
https://dockertest.jsdelivr.fyi/
https://mirror.aliyuncs.com/
https://dockerproxy.com/2.3 操作容器
2.3.1 创建持续运行的容器
root@k8s-master:~# docker run -d --name nginxtest nginx
root@k8s-master:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b68184fd3b9b nginx "/docker-entrypoint.…" About a minute ago Up About a minute 80/tcp nginxtest
root@k8s-master:~# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
b68184fd3b9b nginx "/docker-entrypoint.…" About a minute ago Up About a minute 80/tcp nginxtest
8ea8394296ac hello-world "/hello" 22 minutes ago Exited (0) 22 minutes ago goofy_brattain2.3.2 进入容器
root@k8s-master:~# docker exec -it nginxtest /bin/bash
root@b68184fd3b9b:/# cat /etc/nginx/nginx.conf
root@b68184fd3b9b:/# exit
exit
root@k8s-master:~#
# @后的主机名在exec后发生了变化,这就是进入容器内的标志2.3.3 删除容器
root@k8s-master:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
260028d6b4a2 httpd:v1 "httpd-foreground" 5 seconds ago Up 4 seconds 0.0.0.0:4000->80/tcp, [::]:4000->80/tcp luoyudockerfile
b68184fd3b9b nginx "/docker-entrypoint.…" 12 hours ago Up 12 hours 80/tcp nginxtest
root@k8s-master:~# docker rm -f nginxtest luoyudockerfile
nginxtest
luoyudockerfile
root@k8s-master:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES2.4 构建&使用镜像
2.4.1 镜像概述
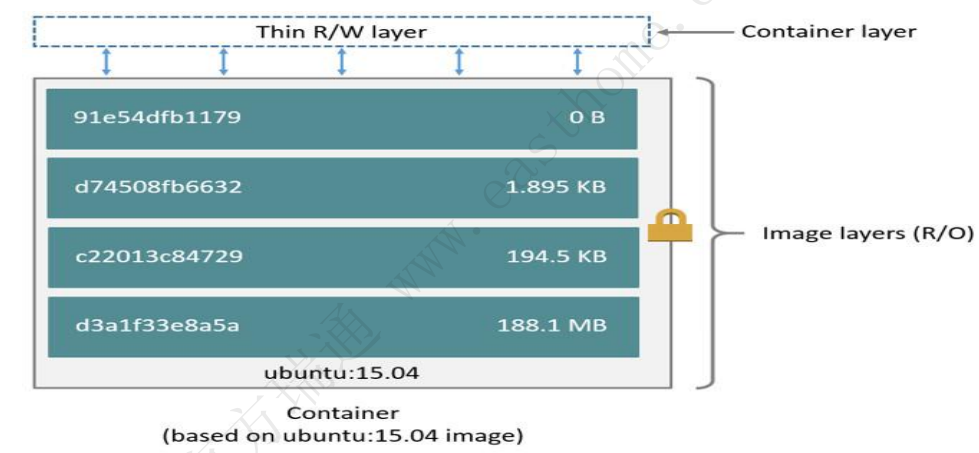
镜像是一个用于创建容器的只读模板,通常来讲,包含一些额外的自定义,比如说,可以构建一个基于centos的镜像,在镜像构建时,直接包含一些应用程序,比如Apache或者其他程序,构建完成后,可以直接基于这个镜像启动容器,快速获得期望的业务
镜像可以来自公共的仓库,也可通过Dockerfile等定义文件来构建,并且把自己的镜像推送到仓库中,以备在任何地方任何时间下载使用
2.4.2 公共镜像仓库
Docker公共镜像仓库:https://hub.docker.com
Docker Hub是一个基于云端的registry服务,这个服务允许我们连接仓库代码、建立镜像、 推送镜像等功能,提供了一个集中式的容器资源管理平台,包含了各式各样的官方镜像,例如Apache、Centos以及各种企业级应用镜像,还以星级和评分来确保镜像的可靠性和适用性

打开https://hub.docker.com,注册一个Docker ID,登陆后浏览各项功能
2.4.3 镜像分层技术
2.4.4 构建镜像的方法
1.docker commit
使用容器中发生更改的部分生成一个新的镜像,通常的使用场景为,基于普通镜像启动了容器,在容器内部署了所需的业务后,把当前的状态重新生成镜像,以便以当前状态快速部署业务所用
2.Dockerfile 创建镜像
从零开始构建自己所需的镜像,在创建镜像之初把所需的各种设置和所需要的各种应用程序包含进去,生成的镜像可直接用于业务部署
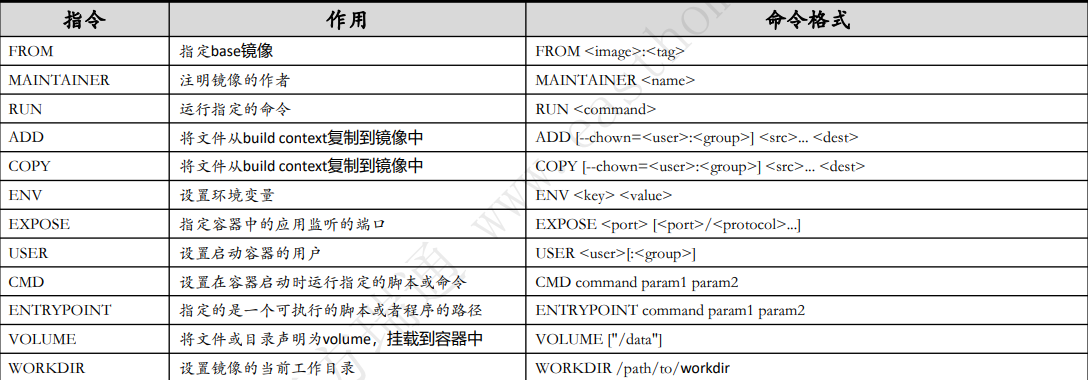
3.Dockerfile高频指令集
2.4.5 Dockerfile image
在设计Dockerfile时应考虑以下事项:
1.容器应该是暂时的
2.避免安装不必要的软件包
3.每个容器只应该有一个用途
4.避免容器有过多的层
5.多行排序
6.建立缓存
# 创建dockerfile文件
root@k8s-master:~# cat > dockerfile <<EOF
FROM httpd
MAINTAINER luovipyu@163.com
RUN echo hello luoyu dockerfile container > /usr/local/apache2/htdocs/index.html
EXPOSE 80
WORKDIR /usr/local/apache2/htdocs/
EOF
# 开始构建镜像
root@k8s-master:~# docker build -t httpd:v1 -f dockerfile .
# 查看docker镜像
root@k8s-master:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
httpd v1 d6d24a446dd4 25 seconds ago 148MB
nginx latest a830707172e8 3 weeks ago 192MB
hello-world latest 74cc54e27dc4 3 months ago 10.1kB
注明:如果文件名是Dockerfile时可不指定
docker build -t web:v1 .
# 如果用的是containerd,dockerfile方式构建容器镜像的命令就是下面这样的
nerdctl build -t httpd:v1 -f dockerfile .
nerdctl images2.4.6 使用Dockerfile镜像
# 用httpd:v1的镜像在本机4000端口上提供一个名为luoyudockerfile的容器
root@k8s-master:~# docker run -d -p 4000:80 --name luoyudockerfile httpd:v1
260028d6b4a2b11cd2cfca9ab6ae9d406cc8fa9afd33131db03c880cc235e68f
root@k8s-master:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
260028d6b4a2 httpd:v1 "httpd-foreground" 5 seconds ago Up 4 seconds 0.0.0.0:4000->80/tcp, [::]:4000->80/tcp luoyudockerfile
b68184fd3b9b nginx "/docker-entrypoint.…" 12 hours ago Up 12 hours 80/tcp nginxtest
root@k8s-master:~# curl http://127.0.0.1:4000
hello luoyu dockerfile container
# 如果用的是containerd,dockerfile方式构建容器镜像的使用命令就是下面这样的
nerdctl run -d -p 4000:80 --name luoyudockerfile httpd:v1
nerdctl ps2.4.7 关于镜像命名
1.镜像命名格式:REPOSITORY+TAG,使用版本号作为命名
root@k8s-master:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
httpd v1 d6d24a446dd4 11 hours ago 148MB
nginx latest a830707172e8 3 weeks ago 192MB
hello-world latest 74cc54e27dc4 3 months ago 10.1kB2.关于latest tag的说明
如果在建立镜像时没有指定Tag,会使用默认值latest,所以,当看到一个镜像的Tag处显示latest的时候,并不一定意味着此版本是最新版,而只意味着在建立镜像的时候,没有指定Tag
root@k8s-master:~# docker build -t web .
root@k8s-master:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
httpd v1 d6d24a446dd4 11 hours ago 148MB
web latest d6d24a446dd4 11 hours ago 148MB
nginx latest a830707172e8 3 weeks ago 192MB
hello-world latest 74cc54e27dc4 3 months ago 10.1kB2.4.8 删除镜像
删除一个特定的镜像,需要知道该镜像的ID或者标签(repository:tag)。或者,如果只记得镜像的部分ID,可以使用这个ID来删除镜像
root@k8s-master:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
httpd v1 d6d24a446dd4 11 hours ago 148MB
web latest d6d24a446dd4 11 hours ago 148MB
nginx latest a830707172e8 3 weeks ago 192MB
hello-world latest 74cc54e27dc4 3 months ago 10.1kB
root@k8s-master:~# docker rmi web:latest
Untagged: web:latest
root@k8s-master:~# docker rmi 74cc54e27dc4
Error response from daemon: conflict: unable to delete 74cc54e27dc4 (must be forced) - image is being used by stopped container 8ea8394296ac
root@k8s-master:~# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8ea8394296ac hello-world "/hello" 13 hours ago Exited (0) 13 hours ago goofy_brattain
root@k8s-master:~# docker rm 8ea8394296ac
root@k8s-master:~# docker rmi 74cc54e27dc4
root@k8s-master:~# docker images
\REPOSITORY TAG IMAGE ID CREATED SIZE
httpd v1 d6d24a446dd4 11 hours ago 148MB
nginx latest a830707172e8 3 weeks ago 192MB2.4.9 私有镜像仓库
构建私有镜像存储考虑:
1.交付时效,例如,下载并运行镜像,需要消耗带宽和时间
2.机房是否允许接入外网
3.镜像私密,不允许将数据放到外网
4.内网速率更高
什么是Registry?
1.Registry是一个无状态、高度可扩展的服务,可以存储和分发镜像
2.Registry是一个基于Apache License许可的开源服务
为什么使用Registry?
1.严格控制映像存储位置
2.拥有完全属于自己的镜像分发渠道
3.将镜像存储和分布紧密集成到内部开发工作流程中
部署Registry步骤如下:如果选用Harbor,请参考Gitee文档
1.下载Docker官方最新版的Registry镜像
2.启动Registry容器
3.下载测试镜像
4.将测试镜像上传至自己的私有仓库
5.验证从自有仓库下载并启动容器
3 部署Harbor私有仓库
在现代软件开发中,容器化应用已经成为主流,而容器镜像仓库则是确保容器镜像安全、管理和分发的重要工具。Harbor作为一款开源的企业级容器镜像仓库管理工具,不仅支持多种认证方式,还提供镜像复制、漏洞扫描和用户访问控制等功能,为企业提供了一个安全、高效的镜像管理方案
| 主机名 | 角色 | IP | VMware网络类型 | 用户名 | 密码 | 系统 |
|---|---|---|---|---|---|---|
| harbor | Harbor主机 | 192.168.8.52 | NAT | root | harbor | RHEL-9.5 |
3.1 RedHat9镜像源配置
3.1.1 国内镜像源
[root@harbor ~]# cd /etc/yum.repos.d
[root@harbor yum.repos.d]# ll
-rw-r--r--. 1 root root 358 May 14 11:25 redhat.repo
[root@harbor yum.repos.d]# vim aliyun_yum.repo
[ali_baseos]
name=ali_baseos
baseurl=https://mirrors.aliyun.com/centos-stream/9-stream/BaseOS/x86_64/os/
gpgcheck=0
[ali_appstream]
name=ali_appstream
baseurl=https://mirrors.aliyun.com/centos-stream/9-stream/AppStream/x86_64/os/
gpgcheck=0
[root@harbor yum.repos.d]# yum makecache
# 根据需要选择是否更新yum源
[root@harbor yum.repos.d]# yum -y update3.1.2 本地yum源配置
配置本地yum源可以创建一个本地的软件包存储库,以便更快地安装、更新和管理软件包
# 创建文件夹并将光盘挂载到新建的文件中
[root@harbor ~]# mkdir -p /GuaZai/Iso
[root@harbor ~]# mount /dev/sr0 /GuaZai/Iso
mount: /GuaZai/Iso: WARNING: source write-protected, mounted read-only.
[root@harbor ~]# cd /GuaZai/Iso
[root@harbor Iso]# ls
AppStream BaseOS EFI EULA extra_files.json GPL images isolinux media.repo RPM-GPG-KEY-redhat-beta RPM-GPG-KEY-redhat-release
#配置yum文件
[root@harbor ~]# vim /etc/yum.repos.d/rhel9.repo
[BaseOS]
name=rhel9-BaseOS
baseurl=file:///GuaZai/Iso/BaseOS
gpgcheck=0
[Appstream]
name=rhel9-Appstream
baseurl=file:///GuaZai/Iso/AppStream
gpgcheck=0
# 查看仓库序列
[root@harbor ~]# yum repolist
# 生成yum缓存
[root@harbor ~]# yum makecache3.2 主机名和IP地址映射
配置Harbor主机的主机名和IP地址映射,映射文件“/etc/hosts”加入如下内容
[root@harbor ~]# vim /etc/hosts
192.168.8.52 registry.luovip.cn3.3 部署Docker CE
# 检测系统是否安装了docker并卸载旧版本的容器
[root@harbor ~]# sudo dnf remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine \
podman \
runc
# 安装依赖
[root@harbor ~]# sudo yum install -y yum-utils
[root@harbor ~]# sudo dnf -y install dnf-plugins-core
[root@harbor ~]# sudo dnf config-manager --add-repo https://download.docker.com/linux/rhel/docker-ce.repo
# 安装docker
[root@harbor ~]# sudo sed -i 's+https://download.docker.com+https://mirror.nju.edu.cn/docker-ce+' /etc/yum.repos.d/docker-ce.repo
[root@harbor ~]# sudo yum install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# 查看docker状态
[root@harbor ~]# sudo systemctl enable --now docker
Created symlink /etc/systemd/system/multi-user.target.wants/docker.service → /usr/lib/systemd/system/docker.service.
[root@harbor ~]# sudo systemctl status docker
[root@harbor ~]# docker info 3.4 Docker镜像加速器
[root@harbor ~]# mkdir -p /etc/docker
[root@harbor ~]# cd /etc/docker
[root@harbor docker]# vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://mirror.ccs.tencentyun.com",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://mirror.gcr.io",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com"
],
"data-root": "/data/docker" # 自定义Docker的镜像存储路径
}
[root@harbor ~]# mkdir -p /data/docker
[root@harbor ~]# cp -a /var/lib/docker/* /data/docker/
[root@harbor ~]# systemctl daemon-reload
[root@harbor ~]# systemctl restart docker
[root@harbor ~]# docker info
# 测试
[root@harbor ~]# docker pull nginx
[root@harbor ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest a830707172e8 3 weeks ago 192MB3.5 Compose支持
添加Compose支持,并启动Docker服务
# 下载docker-compose并放在/usr/local/bin下
curl -L "https://github.com/docker/compose/releases/download/v2.36.0/docker-compose-linux-x86_64" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
systemctl daemon-reload
systemctl restart docker
[root@harbor ~]# docker-compose version
Docker Compose version v2.36.0
# 注明:github可能会访问不了,故先从github下载到本地,再上传到服务器
https://github.com/docker/compose/releases3.6 下载Harbor
[root@harbor ~]# wget https://github.com/goharbor/harbor/releases/download/v2.13.0/harbor-offline-installer-v2.13.0.tgz
[root@harbor ~]# tar xf harbor-offline-installer-v2.13.0.tgz -C /usr/local/bin
# 使用docker load命令将解压后的tar文件加载为Docker镜像
[root@harbor ~]# cd /usr/local/bin
[root@harbor bin]# ll
total 72004
-rwxr-xr-x. 1 root root 73731911 May 14 14:25 docker-compose
drwxr-xr-x. 2 root root 123 May 14 16:33 harbor
[root@harbor bin]# cd harbor
[root@harbor harbor]# docker load -i harbor.v2.13.0.tar.gz3.7 修改harbor.yml文件
mv harbor.yml.tmpl harbor.yml
# 备份harbor.yml文件
cp harbor.yml harbor.yml.bak
[root@harbor ~]# vim /usr/local/bin/harbor/harbor.yml
1.修改hostname为192.168.8.52
2.修改http的端口为82
3.修改harbor_admin_password为admin
# 如果不启用https就注释掉12行-20行3.8 安装Harbor
# 加载配置并安装
[root@harbor harbor]# ./prepare
[root@harbor harbor]# ./install.sh
...
[Step 5]: starting Harbor ...
[+] Running 10/10
✔ Network harbor_harbor Created 0.0s
✔ Container harbor-log Started 0.3s
✔ Container registryctl Started 0.8s
✔ Container harbor-db Started 1.2s
✔ Container redis Started 1.2s
✔ Container harbor-portal Started 1.2s
✔ Container registry Started 1.3s
✔ Container harbor-core Started 1.4s
✔ Container harbor-jobservice Started 2.0s
✔ Container nginx Started 2.0s
✔ ----Harbor has been installed and started successfully.----3.9 重启Harbor
[root@harbor harbor]# docker-compose down
[root@harbor harbor]# ./prepare
[root@harbor harbor]# docker-compose up -d
# 浏览器访问Harbor http://192.168.8.52:82 用户名/密码:admin/admin3.10 生成服务文件
cat > /etc/systemd/system/harbor.service <<EOF
[Unit]
Description=Harbor
After=docker.service systemd-networkd.service systemd-resolved.service
Requires=docker.service
Documentation=http://github.com/vmware/harbor
[Service]
Type=simple
Restart=on-failure
RestartSec=5
ExecStart=/usr/local/bin/docker-compose -f /usr/local/bin/harbor/docker-compose.yml up
ExecStop=/usr/local/bin/docker-compose -f /usr/local/bin/harbor/docker-compose.yml down
[Install]
WantedBy=multi-user.target
EOF
[root@harbor ~]# systemctl daemon-reload
[root@harbor ~]# systemctl enable harbor --now
[root@harbor ~]# systemctl stop harbor
[root@harbor ~]# systemctl status harbor
[root@harbor ~]# systemctl start harbor
[root@harbor ~]# systemctl restart harbor3.11 推送镜像到Harbor
将registry.luovip.cn以及其对应的IP添加到/etc/hosts,然后将上述实验中的httpd:v1镜像,改名为带上IP:PORT形式,上传的镜像到本地仓库
1.添加域名解析
[root@docker ~]# vim /etc/hosts
192.168.8.52 registry.luovip.cn2.编辑文件“/usr/lib/systemd/system/docker.service”,输入以下内容。其中,my.harbor.com是Harbor主机的主机名
[root@docker ~]# vim /usr/lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd --insecure-registry registry.luovip.cn3.编辑“/etc/docker/daemon.json”文件,在该文件中指定私有镜像仓库地址
[root@docker ~]# vim /etc/docker/daemon.json
"insecure-registries": [
"192.168.8.52:82"
]
[root@docker ~]# systemctl daemon-reload
[root@docker ~]# systemctl restart docker.service4.推送的命令
# Docker推送命令:
1.在项目中标记镜像:
docker tag SOURCE_IMAGE[:TAG] 192.168.8.52:82/library/REPOSITORY[:TAG]
2.推送镜像到当前项目:
docker push 192.168.8.52:82/library/REPOSITORY[:TAG]
Podman推送命令:
1.推送镜像到当前项目:
podman push IMAGE_ID 192.168.8.52:82/library/REPOSITORY[:TAG]5.推送镜像
[root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
tomcat latest c6c6349a7df2 47 hours ago 468MB
nginx latest a830707172e8 4 weeks ago 192MB
[root@docker ~]# docker login 192.168.8.52:82
[root@docker ~]# docker tag c6c6349a7df2 192.168.8.52:82/library/tomcat:v2
[root@docker ~]# docekr images
-bash: docekr: command not found
[root@docker ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
192.168.8.52:82/library/tomcat v2 c6c6349a7df2 47 hours ago 468MB
tomcat latest c6c6349a7df2 47 hours ago 468MB
nginx latest a830707172e8 4 weeks ago 192MB
[root@docker ~]# docker push 192.168.8.52:82/library/tomcat:v2
[root@docker ~]# docker pull 192.168.8.52:82/library/tomcat:v24 管理容器的资源
# 创建容器并观察内存量
[root@docker ~]# docker run -d --name=httpd_server httpd
[root@docker ~]# docker run -d --name=httpd_tomcat tomcat
[root@docker ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
796227a2aac7 tomcat "catalina.sh run" 2 minutes ago Up 2 minutes 8080/tcp httpd_tomcat
b025ca41d951 httpd "httpd-foreground" 3 minutes ago Up 3 minutes 80/tcp httpd_server
[root@docker ~]# docker exec -it httpd_server grep MemTotal /proc/meminfo
MemTotal: 3974748 kB
[root@docker ~]# docker exec -it httpd_tomcat grep MemTotal /proc/meminfo
MemTotal: 3974748 kB4.1 容器的内存配额
根据以上得出结论,每个容器的内存量,全部等于物理宿主机的内存总量,这意味这更好的性能,但同时也意味着一旦业务需求上升,将有可能发生资源争用,这通常在运维规划时,应当极力避免
容器可使用的内存:物理内存和交换空间(Swap)
Docker默认没有设置内存限制。可以通过相关选项限制设置:
1.-m(–memory):设置容器可用的最大内存,该值最低为4MB
2.–memory-swap:允许容器置入磁盘交换空间中的内存大小
4.1.1 用户内存限制
Docker提供4种方式设置容器的用户内存使用:
1.对容器内存使用无限制(两个选项都不使用)
2.设置内存限制并取消交换空间内存限制
#使用300内存和尽可能多的交换空间
[root@docker ~]# docker run -it -m 300M --memory-swap -1 ubuntu /bin/bash3.只设置内存限制
# 300MB的内存和300MB的交换空间
# 默认情况下虚拟内存总量将设置为内存大小的两倍,因此容器能使用300M的交换空间
[root@docker ~]# docker run -it -m 300M ubuntu /bin/bash4.同时设置内存和交换空间
# 300MB的内存和700MB的交换空间
[root@docker ~]# docker run -it -m 300M --memory-swap 700m ubuntu /bin/bash4.1.2 内核内存限制
内核内存不能交换到磁盘中,无法使用交换空间,消耗过多可能导致其阻塞系统服务
# 在500MB的内存中,可以使用最高50MB的内核内存
[root@docker ~]# docker run -it -m 500M --kernel-memory 50M ubuntu /bin/bash
# 只可以使用50MB的内核内存
[root@docker ~]# docker run -it --kernel-memory 50M ubuntu /bin/bash4.1.3 内存预留实现软限制
使用–memory-reservation选项设置内存预留,它是一种内存软限制,允许更多的内存共享。设置后,Docker将检测内存争用或内存不足,并强制容器将其内存消耗限制为预留值
内存预留值应当始终低于硬限制,作为一个软限制功能,内存预留并不能保证不会超过限制
# 限制内存为500MB,内存预留值(软限制)为200MB。
# 当容器消耗内存大于200MB、小于500MB时,下一次系统内存回收将尝试将容器内存缩减到200MB以下
[root@docker ~]# docker run -it -m 500M --memory-reservation 200M ubuntu /bin/bash
docker run –it –m 500M --memory-reservation 200M ubuntu /bin/bash
# 设置内存软限制为1GB
[root@docker ~]# docker run -it —-memory-reservation 1G ubuntu /bin/bash4.2 容器的CPU配额
默认情况下,所有容器都可以使用相同的CPU资源,并且没有任何限制,这和内存问题一样,一旦CPU需求业务上升,同样会引起CPU资源的争用,但是和内存指定绝对量的不同,CPU是通过指定相对权重值来进行的配额
使用–cpu-shares参数对CPU来进行配额分配,默认情况下,这个值为1024
当前容器中的业务空闲时,其他的容器有权利使用其空闲的CPU周期,这将确保业务的性能
CPU限额的分配,只有在物理机资源不足的时候才会生效,并且是根据不同的优先级进行的,当其他容器空闲时,忙碌的容器可以获得全部可用的CPU资源
4.2.1 CPU份额限制
-c(–cpu-shares)选项将CPU份额权重设置为指定的值
默认值为1024,如果设置为0,系统将忽略该值并使用默认值1024
4.2.2 CPU周期限制
–cpu-period选项(以μs为单位)设置CPU周期以限制容器CPU资源的使用
默认的CFS(完全公平调度器)周期为100ms(100000μs)
通常将–cpu-period与–cpu-quota这两个选项配合使用:
# 如果只有1个CPU,则容器可以每50ms(50000μs)获得50%(25000/50000)的CPU运行时间
[root@docker ~]# docker run -it --cpu-period=50000 --cpu-quota=25000 ubuntu /bin/bash
# 可用--cpus选项指定容器的可用CPU资源来达到同样的目的
# --cpus选项值是一个浮点数,默认值为0.000,表示不受限制
# 上述可改为
[root@docker ~]# docker run -it --cpus=0.5 ubuntu /bin/bash
# --cpu-period和--cpu-quota选项都是以1个CPU为基准4.2.3 CPU放置限制
–cpuset-cpus选项限制容器进程在指定的CPU上执行
# 容器中的进程可以在cpu1和cpu3上执行
[root@docker ~]# docker run -it --cpuset-cpus="1,3" ubuntu:14.04 /bin/bash
# 容器中的进程可以在cpu0、cpu1和cpu 2上执行
[root@docker ~]# docker run -it --cpuset-cpus="0-2" ubuntu:14.04 /bin/bash4.2.4 CPU配额限制
–cpu-quota选项限制容器的CPU配额,默认值为0表示容器占用100%的CPU资源个CPU
CFS用于处理进程执行的资源分配,是由内核使用的默认Linux调度程序。将此值设置50000意味着限制容器至多使用CPU资源的50%,对于多个CPU而言,调整–cpu-quota选项必要的
4.3 容器的I/O配额
默认情况下,所有容器都可以使用相同的I/O资源(500权重),并且没有任何限制,这和内存、 CPU问题一样,一旦I/O需求业务上升,硬盘读写会变得非常迟缓,所以为了更好的提供服务,也应该对容器使用硬盘方面进行调整
块I/O带宽(Block I/O Bandwidth,Blkio)是另一种可以限制容器使用的资源
块I/O指磁盘的写,Docker可通过设置权重限制每秒字节数(B/s)和每秒I/O次数(IO/s)的方式控制容器读写盘的带宽
4.3.1 设置块I/O权重
–blkio-weight选项更改比例(原默认为500),设置相对于所有其他正在运行的容器的块I/O带宽权重
# 创建两个有不同块I/O带宽权重的容器
[root@docker ~]# docker run -it --name c1 --blkio-weight 300 ubuntu /bin/bash
[root@docker ~]# docker run -it --name c2 --blkio-weight 600 ubuntu /bin/bash
在以下案例中,权重为600的容器将比300的在I/O能力方面多出两倍:
[root@docker ~]# docker run -d --name 300io --blkio-weight 300 httpd
[root@docker ~]# docker run -d --name 600io --blkio-weight 600 httpd
命令测试I/O性能:
[root@docker ~]# time dd if=/dev/zero of=test.out bs=1M count=1024
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 4.05265 s, 265 MB/s
real 0m4.055s
user 0m0.000s
sys 0m4.036s
注:此设定在I/O争用时,才会体现4.3.2 限制设备读写速率
Docker根据两类指标限制容器的设备读写速率:一类是每秒字节数,另一类是每秒I/O次数
1.限制每秒字节数
–device-read-bps选项限制指定设备的读取速率,即每秒读取的字节数
# 创建一个容器,并限制对/dev/mapper/rhel-swap设备的读取速率为每秒1MB
[root@docker ~]# docker run -it --device-read-bps /dev/mapper/rhel-swap:1mb ubuntu
docker run -it --device-read-bps /dev/sda:1mb ubuntu
# 类似地,可使用--device-write-bps选项限制指定设备的写入速率。格式: <设备>:<速率值>[单位]2.限制每秒I/O次数
–device-read-iops和–device-write-iops选项制指定设备的读取和写入速率,用每秒I/O次数表示
# 创建一个容器,限制它对/dev/mapper/rhel-swap设备的读取速率为每秒1000次
[root@docker ~]# docker run -it --device-read-iops /dev/mapper/rhel-swap:1000 ubuntu4.4 容器底层技术实现
对容器使用的内存、CPU和块I/O带宽资源的限制具体是由控制组(Cgroup)的相应子系统来实现的
1.memory子系统设置控制组中的住务所使用的内存限制
2.cpu子系统通过调度程序提供对CPU的控制组任务的访问
3.blkio子系统为块设备(如磁盘、固态硬盘、USB等)设置输入和输出限制
在docker run命令中使用–cpu-shares、–memory、–device-read-bps等选项实际上就是在配置控制组,相关的配置文件保存在/sys/fs/cgroup目录中
4.4.1 资源限制的底层实现
Linux通过cgroup来分配进程使用的CPU、memory、I/O资源的配额,可以通过/sys/fs/cgroup/下面的设定来查看容器的配额部分
# 启动一个容器,设置内存限额为300MB,CPU权重为512
[root@docker ~]# docker run --rm -d -p 8080:80 -m 300M --cpu-shares=512 httpd
1dc9a3907b6b82521addd810d52d2514c6ab5fed1e274f03a90e5a1454d16a49
# 动态更改容器的资源限制
# docker update命令可以动态地更新容器配置,其语法:docker update [选项] 容器 [容器...]
[root@docker ~]# docker update -m 500M --cpu-shares=10245 1dc9a3907b6b82521addd810d52d2514c6ab5fed1e274f03a90e5a1454d16a49
1dc9a3907b6b82521addd810d52d2514c6ab5fed1e274f03a90e5a1454d16a494.4.2 容器的隔离底层实现
每个容器貌似都有自己独立的根目录以及/etc、/var等目录,而且貌似都有自己的独立网卡,但事实上物理宿主机只有一个网卡,那么容器之间是怎么实现的“独立性”的呢?
Linux使用namespace技术来实现了容器间的资源隔离,namespace管理着宿主机中的全局唯一资源,并且可以让每个容器都会认为自己拥有且只有自己在使用资源,namespace一共有6种,分别为:mount、UTS、IPC、PID、Network、User
4.4.3 namespace
Mount namespace让容器看上去拥有整个文件系统,容器有自己的根目录
UTS namespace可以让容器有自己的主机名,默认情况下,容器的主机名是它本身的短ID,可通过-h或者–hostname设置主机名
IPC namespace可以让容器拥有自己的共享内存和信号量来实现进程间通信
PID namespace让容器拥有自己的进程树,可以在容器中执行ps命令查看
Network namespace可以让容器拥有自己独立的网卡、IP、路由等资源
User namespace 让容器能够管理自己的用户,而不是和宿主机公用/etc/passwd
5 容器原生网络与存储
5.1 容器原生网络
docker原生提供了以下几种网络,如果对原生网络不满意,还可以创建自定义网络
原生网络分为:none、bridge、host,这些网络在docker安装的时候会自动创建,可以通过以下命令来查看
[root@docker ~]# docker network ls
NETWORK ID NAME DRIVER SCOPE
f85881372579 bridge bridge local
668aba04b5b0 host host local
3fa8ef65ab94 none null local如果容器使用的是none网络,那么此容器将不具备常规理解上的网卡,只具备lo网络,如果要使用这个网络,在创建容器时,指定–network=none即可
None网络是比较封闭的网络,对一些安全要求比较高并且不需要联网的场景,可以用none网络,比如手机上接收的验证码、随机数生成等场景,就可以放在none网络中以避免被窃取
Host网络是一个共享宿主机网络栈的一个容器共享网络,可以通过–network=host在创建容器 的时候指定host网络,处于host网络模式的容器,网络配置和宿主机是完全一样的,也就是说,在容器中可以看到宿主机的所有网卡,并且主机名也是宿主机的,这最大的好处就是性能很高,传输速率特别好,但是宿主机上已经使用的端口,容器就不可以使用
5.2 容器和层
容器和镜像最大的不同在于最顶上的可写层,所有在容器中的数据写入和修改都会直接存储到这个可写层中,这就意味着,当容器被删除时,可写层中的数据就丢失了,虽然每个容器都有自己不同的可写层,但是容器底层的镜像却是可以同时共享的
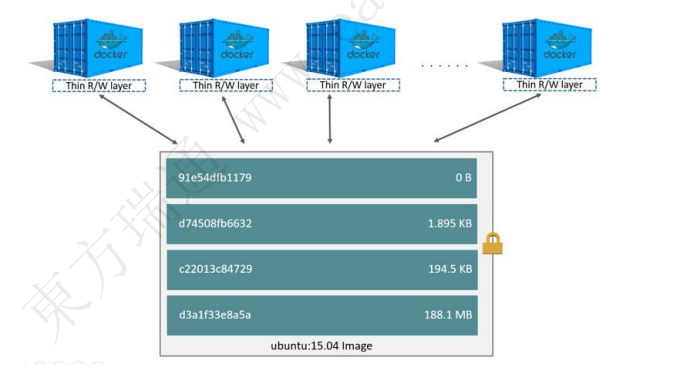
5.3 主流存储驱动
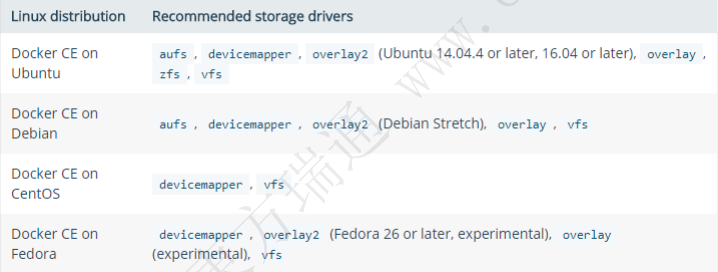
在容器设计和使用的时候,在容器的可写层中写入的数据是非常少的,但在运维中大部分数据是必须要具备持久化保存的能力,所以在容器中引入了多种的存储驱动来解决上面说的可写层数据的易失性
目前主流受支持的存储驱动有:
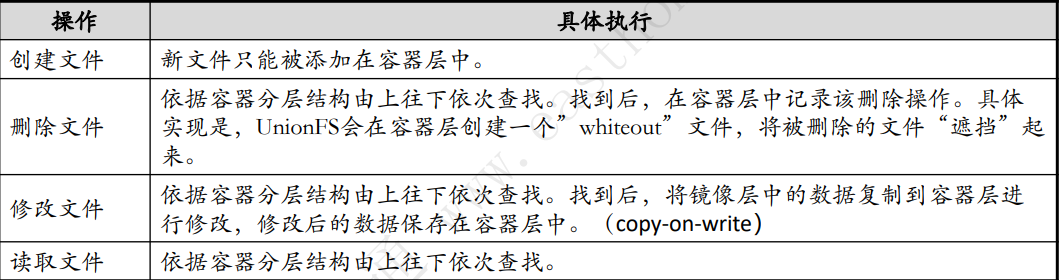
5.4 Copy-on-write策略
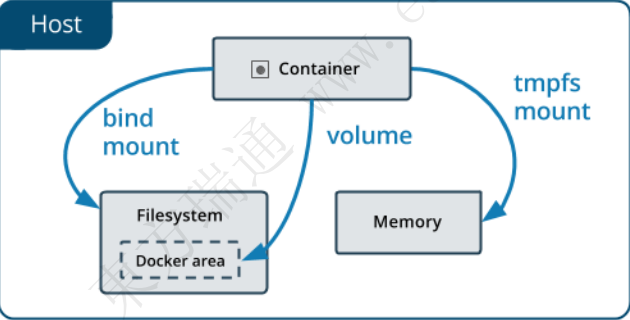
5.5 容器数据管理
容器中持久化数据一般采用两种存储方式:
1.volume
2.bind mount
6 Kubernetes
6.1 K8S的概念
Kubernetes是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化
Kubernetes拥有一个庞大且快速增长的生态系统。Kubernetes 的服务、支持和工具广泛可用

6.2 K8S的特点
Kubernetes具有以下几个特点:
1.可移植: 支持公有云、私有云、混合云、多重云(multi-cloud)
2.可扩展: 模块化、插件化、可挂载、可组合
3.自动化: 自动部署、自动重启、自动复制、自动伸缩/扩展
6.3 K8S的作用
Kubernetes的主要职责是容器编排(Container Orchestration),即在一组服务器上启动、 监控、回收容器,在满足排程的同时,保证容器可以健康的运行
6.4 K8S的整体架构
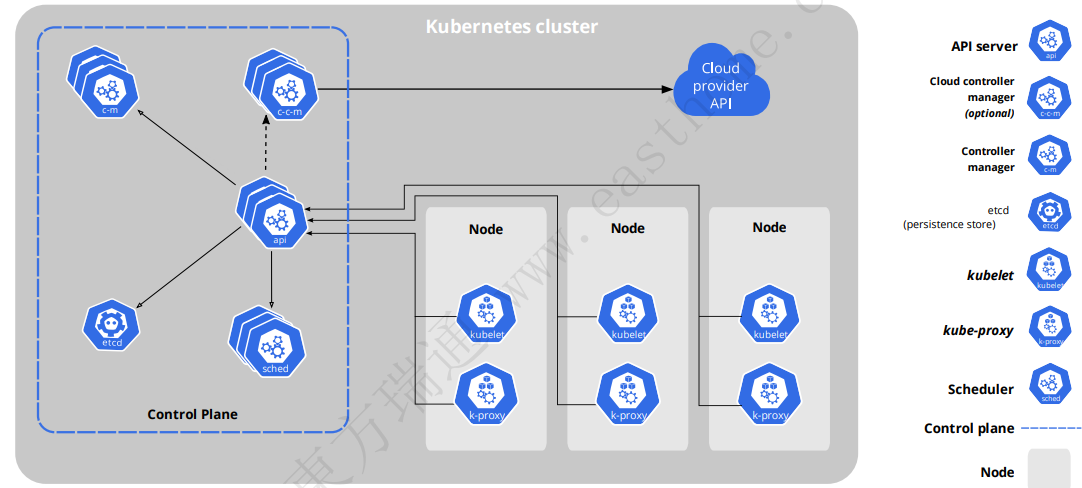
6.4.1 Master节点
1.kube-apiserver
API服务器是Kubernetes控制面的前端
Kubernetes API服务器的主要实现是kube-apiserver
kube-apiserver设计上考虑了水平伸缩,可通过部署多个实例进行伸缩。 可以运行kube-apiserver的多个实例,并在这些实例之间平衡流
2.etcd
etcd是兼具一致性和高可用性的键值数据库,可以作为保存Kubernetes所有集群数据的后台数据库
3.cloud-controller-manager
cloud-controller-manager仅运行特定于云平台的控制回路
如果在自己的环境中运行Kubernetes,或者在本地计算机中运行学习环境, 所部署的环境中不需要云控制器管理器
4.kube-scheduler
控制平面组件,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行
5.kube-controller-manager
这些控制器包括:
节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
任务控制器(Job controller): 监测代表一次性任务的Job对象,然后创建Pods来运行这些任务直至完成
端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和API访问令牌
6.4.2 Node节点
1.kubelet
一个在集群中每个节点(node)上运行的代理,保证容器(containers)都运行在Pod中
2.kube-proxy
kube-proxy是集群中每个节点上运行的网络代理, 实现Kubernetes服务(Service)概念的一部分
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与Pod进行网络通信
如果操作系统提供了数据包过滤层并可用的话,kube-proxy会通过它来实现网络规则。否则, kube-proxy仅转发流量本身
3.容器运行时(Container Runtime)
Kubernetes支持多个容器运行环境: Docker、 containerd、CRI-O以及任何实现Kubernetes CRI (容器运行环境接口)
6.4.3 插件(Addons)
插件使用Kubernetes资源(DaemonSet、 Deployment等)实现集群功能。 因为这些插件提供集群级别的功能,插件中命名空间域的资源属于kube-system命名空间
1.Core-dns:为整个集群提供DNS服务
2.Ingress Controller:为service提供外网访问入口
3.Dashboard: 提供图形化管理界面
4.Flannel/ Calico :为kubernetes提供方便的网络规划服务
7 Kubernetes集群部署
7.1 Kubernetes的安装流程
7.1.1 先决条件
1.最小配置:2G内存2核CPU
2.集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
3.节点之中不可以有重复的主机名、MAC 地址或product_uuid
4.禁用交换分区
5.开启机器上的某些端口
7.1.2 安装runtime
默认情况下,Kubernetes使用容器运行时接口(Container Runtime Interface,CRI) 与所选择的容器运行时交互
如果不指定运行时,则kubeadm会自动尝试检测到系统上已经安装的运行时, 方法是扫描一组众所周知的Unix域套接字,docker启用shim来对接K8S
运行时的域套接字:
Docker unix:///var/run/cri-dockerd.sock
containerd /run/containerd/containerd.sock
CRI-O /var/run/crio/crio.sock
7.1.3 安装kubeadm、kubelet和kubectl
需要在每台机器上安装以下软件包:
kubeadm:用来初始化集群的指令
kubelet:在集群中的每个节点上用来启动Pod和容器等
kubectl:用来与集群通信的命令行工具
确保它们与通过kubeadm安装的控制平面的版本相匹配。 不然可能会导致一些预料之外的错误和问题。 然而,控制平面与kubelet间的相差一个次要版本不一致是支持的,但kubelet的版本不可以超过API服务器的版本。 例如,1.7.0 版本的kubelet可以完全兼容1.8.0版本的API 服务器,反之则不可以
7.1.4 检查所需端口
1.控制平面
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 6443 | Kubernetes API服务器 | 所有组件 |
| TCP | 入站 | 2379-2380 | etcd服务器客户端API | kube-apiserver,etcd |
| TCP | 入站 | 10250 | Kubelet API | kubelet自身、控制平面组件 |
| TCP | 入站 | 10251 | kube-scheduler | kube-scheduler自身 |
| TCP | 入站 | 10252 | kube-controller-manager | kube-controller-manager自身 |
2.工作节点
| 协议 | 方向 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|---|
| TCP | 入站 | 10250 | Kubelet API | kubelet自身、控制平面组件 |
| TCP | 入站 | 30000-32767 | NodePort服务 | 所有组件 |
7.1.5 Iptables桥接流量
为了让Linux节点上的iptables能够正确地查看桥接流量,需要确保sysctl配置中将net.bridge.bridge-nf-call-iptables设置为1

7.1.6 环境准备
本K8S集群使用3台机器(ubuntu)进行部署,各节点信息如下表:
注明:使用的容器为Docker
| 主机名 | 角色 | IP | VMware网络类型 | 用户名 | 密码 | 互联网连接 |
|---|---|---|---|---|---|---|
| k8s-master | 控制平面 | 192.168.8.3 | NAT | vagrant root | vagrant vargrant | 是 |
| k8s-worker1 | 数据平面 | 192.168.8.4 | NAT | vagrant root | vagrant vargrant | 是 |
| k8s-worker2 | 数据平面 | 192.168.8.5 | NAT | vagrant root | vagrant vargrant | 是 |
准备DNS解析:
这一步需要在所有机器上完成
# 这一步需要在所有机器上完成
cat >> /etc/hosts <<EOF
192.168.8.3 k8s-master
192.168.8.4 k8s-worker1
192.168.8.5 k8s-worker2
192.168.30.133 registry.xiaohui.cn
EOF7.2 Docker CE 部署
7.2.1 添加Docker仓库
这一步要在所有机器上完成:
# 安装依赖
sudo apt-get update
sudo apt-get install -y ca-certificates curl gnupg lsb-release
# 添加公钥到系统
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://mirrors.nju.edu.cn/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
# 添加仓库到系统
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.nju.edu.cn/docker-ce/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 判断仓库是否已做好
sudo apt-get update7.2.2 安装Docker CE
这一步要在所有机器上完成:
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin
# 部署完Docker CE之后,还需要cri-docker shim才可以和Kubernetes集成7.2.3 CRI-Docker部署
这一步要在所有机器上完成:
# 下载cri-docker
wget http://hub.gitmirror.com/https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.17/cri-dockerd_0.3.17.3-0.ubuntu-jammy_amd64.deb
# 安装cri-docker
dpkg -i cri-dockerd_0.3.17.3-0.ubuntu-jammy_amd64.deb7.2.4 Docker镜像加速器
这一步要在所有机器上完成:
vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://mirror.ccs.tencentyun.com",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://mirror.gcr.io",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com"
],
"exec-opts": ["native.cgroupdriver=systemd"]
}
systemctl daemon-reload
systemctl restart docker7.2.5 将镜像指引到国内
这一步要在所有机器上完成:
cp /lib/systemd/system/cri-docker.service /etc/systemd/system/cri-docker.service
sed -i 's/ExecStart=.*/ExecStart=\/usr\/bin\/cri-dockerd --container-runtime-endpoint fd:\/\/ --network-plugin=cni --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com\/google_containers\/pause:3.10/' /etc/systemd/system/cri-docker.service
systemctl daemon-reload
systemctl restart cri-docker.service
systemctl enable cri-docker.service7.3 Kubernetes部署
7.3.1 关闭swap分区
这一步要在所有机器上完成:
# 实时关闭
swapoff -a
# 永久关闭
sed -i 's/.*swap.*/#&/' /etc/fstab7.3.2 允许iptables检查桥接流量
这一步要在所有机器上完成:
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system7.3.3 安装kubeadm
这一步要在所有机器上完成:
# 安装依赖
apt-get update && apt-get install -y apt-transport-https curl
# 安装K8S软件包仓库-阿里云
cat > /etc/apt/sources.list.d/k8s.list <<EOF
deb https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/deb /
EOF
# 安装软件包仓库的公钥
curl -fsSL https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.32/deb/Release.key | apt-key add -
# 更新软件包的仓库索引
apt-get update
# 开始安装
apt-get install -y kubelet kubeadm kubectl
# 操作系统所有软件包升级时将忽略kubelet、kubeadm、kubectl
apt-mark hold kubelet kubeadm kubectl7.3.4 添加命令自动补齐
这一步要在所有机器上完成:
kubectl completion bash > /etc/bash_completion.d/kubectl
kubeadm completion bash > /etc/bash_completion.d/kubeadm
source /etc/bash_completion.d/kubectl
source /etc/bash_completion.d/kubeadm7.3.5 集成CRI-Docker
这一步要在所有机器上完成:
crictl config --set runtime-endpoint unix:///run/cri-dockerd.sock
crictl images7.3.6 集群部署
kubeadm.yaml中name字段必须在网络中可被解析,也可以将解析记录添加到集群中所有机器的/etc/hosts中
初始化集群部署的操作只能在k8s-master上执行
# 初始化配置
kubeadm config print init-defaults > kubeadm.yaml
sed -i 's/.*advert.*/ advertiseAddress: 192.168.8.3/g' kubeadm.yaml
sed -i 's/.*name.*/ name: k8s-master/g' kubeadm.yaml
sed -i 's|imageRepo.*|imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers|g' kubeadm.yaml
sed -i "/^\\s*networking:/a\\ podSubnet: 172.16.0.0/16" kubeadm.yaml
# 注意下面的替换,只有在集成的是CRI-Docker时才需要执行,Containerd不需要
sed -i 's/ criSocket.*/ criSocket: unix:\/\/\/run\/cri-dockerd.sock/' kubeadm.yaml
# 模块加载
modprobe br_netfilter
# 集群初始化
kubeadm init --config kubeadm.yaml
Your Kubernetes control-plane has initialized successfully!
......
kubeadm join 192.168.8.3:6443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:c2546a856290440a8ccaf9223c14fd1c2098ac74f4a584acf5f3c5a373005207
# 授权管理权限
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 查看集群状态
root@k8s-master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master NotReady control-plane 62m v1.32.57.3.7 部署Calico网络插件
Calico网络插件部署的操作在所有节点上执行
# 使用operator安装calico组件-可能会失败
# 以下为github的地址,可能会失败
root@k8s-master:~# kubectl create -f https://raw.gitmirror.com/projectcalico/calico/refs/tags/v3.29.3/manifests/tigera-operator.yaml
# 解决办法:
# 1.获取Calico images到本地
见Calico.txt
# 2.发布本地的yaml到集群-master
kubectl create -f https://www.linuxcenter.cn/files/cka/cka-yaml/tigera-operator-calico-3.29.3.yaml
root@k8s-master:~# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-76fccbbb6b-l7jq9 0/1 Pending 0 163m
kube-system coredns-76fccbbb6b-nd68g 0/1 Pending 0 163m
kube-system etcd-k8s-master 1/1 Running 0 163m
kube-system kube-apiserver-k8s-master 1/1 Running 0 163m
kube-system kube-controller-manager-k8s-master 1/1 Running 0 163m
kube-system kube-proxy-mcwv7 1/1 Running 0 163m
kube-system kube-scheduler-k8s-master 1/1 Running 0 163m
tigera-operator tigera-operator-75b4cd596c-9hjml 1/1 Running 0 7m5s7.3.8 设置calico在集群的网段
这一步在k8s-master上执行
# 使用下面的自定义资源设置一下calico在集群中的网段
# 以下为github的地址,可能会失败
root@k8s-master:~# wget https://raw.gitmirror.com/projectcalico/calico/refs/tags/v3.29.3/manifests/custom-resources.yaml
# 3.使用下面的地址执行
root@k8s-master:~# wget https://www.linuxcenter.cn/files/cka/cka-yaml/custom-resources-calico-3.29.3.yaml
root@k8s-master:~# mv custom-resources-calico-3.29.3.yaml custom-resources.yaml7.3.9 确认资源的地址
这一步在k8s-master上执行
root@k8s-master:~# vim custom-resources.yaml
# This section includes base Calico installation configuration.
# For more information, see: https://docs.tigera.io/calico/latest/reference/installation/api#operator.tigera.io/v1.Installation
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
ipPools:
- name: default-ipv4-ippool
blockSize: 26
cidr: 172.16.0.0/16 #这里换成上面规定好的172.16.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
---
# This section configures the Calico API server.
# For more information, see: https://docs.tigera.io/calico/latest/reference/installation/api#operator.tigera.io/v1.APIServer
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}7.3.10 自定义资源发布到集群
root@k8s-master:~# kubectl apply -f custom-resources.yaml
root@k8s-master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 173m v1.32.5
root@k8s-master:~# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
calico-apiserver calico-apiserver-6499c768c8-wvrnt 1/1 Running 0 60s
calico-apiserver calico-apiserver-6499c768c8-zmvh6 1/1 Running 0 60s
calico-system calico-kube-controllers-85fb6564b7-gtsfr 1/1 Running 0 60s
calico-system calico-node-4mqfj 1/1 Running 0 60s
calico-system calico-typha-65d47d7478-ttzx6 1/1 Running 0 60s
calico-system csi-node-driver-7j8pf 2/2 Running 0 60s
kube-system coredns-76fccbbb6b-l7jq9 1/1 Running 0 172m
kube-system coredns-76fccbbb6b-nd68g 1/1 Running 0 172m
kube-system etcd-k8s-master 1/1 Running 0 172m
kube-system kube-apiserver-k8s-master 1/1 Running 0 172m
kube-system kube-controller-manager-k8s-master 1/1 Running 0 172m
kube-system kube-proxy-mcwv7 1/1 Running 0 172m
kube-system kube-scheduler-k8s-master 1/1 Running 0 172m
tigera-operator tigera-operator-75b4cd596c-9hjml 1/1 Running 0 16m7.3.11 加入Worker节点
加入节点操作需在所有的worker节点完成,这里要注意,Worker节点需要完成以下先决条件才能执行kubeadm join
1.Docker、CRI-Docker 部署
2.Swap分区关闭
3.iptables桥接流量的允许
4.安装kubeadm等软件
5.集成CRI-Docker
6.所有节点的/etc/hosts中互相添加对方的解析
如果时间长忘记了join参数,可以在master节点上用以下方法重新生成
root@k8s-master:~# kubeadm token create --print-join-command
kubeadm join 192.168.8.3:6443 --token 5mffg7.lq7ujh6vot0jzrci --discovery-token-ca-cert-hash sha256:c2546a856290440a8ccaf9223c14fd1c2098ac74f4a584acf5f3c5a373005207如果有多个CRI对象,在worker节点上执行以下命令加入节点时,指定CRI对象,案例如下:
root@k8s-worker1:~# kubeadm token create --print-join-command
kubeadm join 192.168.8.3:6443 --token 5mffg7.lq7ujh6vot0jzrci --discovery-token-ca-cert-hash sha256:c2546a856290440a8ccaf9223c14fd1c2098ac74f4a584acf5f3c5a373005207
failed to load admin kubeconfig: open /root/.kube/config: no such file or directory
To see the stack trace of this error execute with --v=5 or higher
found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the 'criSocket' field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock
To see the stack trace of this error execute with --v=5 or higher
# 加入两个节点
1.节点worker1
root@k8s-worker1:~# kubeadm join 192.168.8.3:6443 --token 5mffg7.lq7ujh6vot0jzrci --discovery-token-ca-cert-hash sha256:c2546a856290440a8ccaf9223c14fd1c2098ac74f4a584acf5f3c5a373005207 --cri-socket=unix:///var/run/cri-dockerd.sock
2.节点worker2
root@k8s-worker2:~# kubeadm join 192.168.8.3:6443 --token 5mffg7.lq7ujh6vot0jzrci --discovery-token-ca-cert-hash sha256:c2546a856290440a8ccaf9223c14fd1c2098ac74f4a584acf5f3c5a373005207 --cri-socket=unix:///var/run/cri-dockerd.sock
3.查看各节点状态
root@k8s-master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 3h28m v1.32.5
k8s-worker1 Ready <none> 2m2s v1.32.5
k8s-worker2 Ready <none> 2m2s v1.32.5
4.查看pod信息
root@k8s-master:~# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
calico-apiserver calico-apiserver-6499c768c8-wvrnt 1/1 Running 0 37m
calico-apiserver calico-apiserver-6499c768c8-zmvh6 1/1 Running 0 37m
calico-system calico-kube-controllers-85fb6564b7-gtsfr 1/1 Running 0 37m
calico-system calico-node-4mqfj 1/1 Running 0 37m
calico-system calico-node-rkd6k 1/1 Running 0 3m37s
calico-system calico-node-vxflh 1/1 Running 0 3m37s
calico-system calico-typha-65d47d7478-cmrtt 1/1 Running 0 3m28s
calico-system calico-typha-65d47d7478-ttzx6 1/1 Running 0 37m
calico-system csi-node-driver-7j8pf 2/2 Running 0 37m
calico-system csi-node-driver-nhg4c 2/2 Running 0 3m37s
calico-system csi-node-driver-z6p7p 2/2 Running 0 3m37s
kube-system coredns-76fccbbb6b-l7jq9 1/1 Running 0 3h29m
kube-system coredns-76fccbbb6b-nd68g 1/1 Running 0 3h29m
kube-system etcd-k8s-master 1/1 Running 0 3h29m
kube-system kube-apiserver-k8s-master 1/1 Running 0 3h29m
kube-system kube-controller-manager-k8s-master 1/1 Running 0 3h29m
kube-system kube-proxy-8n6x5 1/1 Running 0 3m37s
kube-system kube-proxy-mcwv7 1/1 Running 0 3h29m
kube-system kube-proxy-xk4h4 1/1 Running 0 3m37s
kube-system kube-scheduler-k8s-master 1/1 Running 0 3h29m
tigera-operator tigera-operator-75b4cd596c-9hjml 1/1 Running 0 52m注意上描述命令最后的–cri-socket参数,在系统中部署了docker和cri-docker时,必须明确指明此参数,并将此参数指向我们的cri-docker,不然命令会报告有两个重复的CRI的错误
在k8s-master机器上执行以下内容给节点打上角色标签,k8s-worker1和k8s-worker2分别打上了worker1和worker2的标签
root@k8s-master:~# kubectl label nodes k8s-worker1 node-role.kubernetes.io/worker1=
node/k8s-worker1 labeled
root@k8s-master:~# kubectl label nodes k8s-worker2 node-role.kubernetes.io/worker2=
node/k8s-worker2 labeled
root@k8s-master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 3h33m v1.32.5
k8s-worker1 Ready worker1 7m37s v1.32.5
k8s-worker2 Ready worker2 7m37s v1.32.57.3.12 重置集群
如果在安装好集群的情况下,想重复练习初始化集群,或者包括初始化集群报错在内的任何原因,想重新初始化集群时,可以用下面的方法重置集群,重置后,集群就会被删除,可以用于重新部署,一般来说,这个命令仅用于k8s-master这个节点
root@k8s-master:~# kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
# 根据提示,手工完成文件和规则的清理 清理后就可以重新部署集群了
root@k8s-master:~# rm -rf /etc/cni/net.d
root@k8s-master:~# iptables -F
root@k8s-master:~# rm -rf $HOME/.kube/config7.3.13 标签和注解
标签(Labels)和注解(Annotations)是附加到Kubernetes 对象(比如Pods)上的键值对
标签旨在用于指定对用户有意义的标识属性,但不直接对核心系统有语义含义。可以用来选择对象和查找满足某些条件的对象集合
注解不用于标识和选择对象。有效的注解键分为两部分: 可选的前缀和名称,以斜杠(/)分隔。 名称段是必需项,并且必须在63个字符以内
root@k8s-master:~# kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-master Ready control-plane 4h11m v1.32.5 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-master,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
k8s-worker1 Ready worker1 45m v1.32.5 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-worker1,kubernetes.io/os=linux,node-role.kubernetes.io/worker1=
k8s-worker2 Ready worker2 45m v1.32.5 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-worker2,kubernetes.io/os=linux,node-role.kubernetes.io/worker2=
root@k8s-master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 4h11m v1.32.5
k8s-worker1 Ready worker1 45m v1.32.5
k8s-worker2 Ready worker2 45m v1.32.58 Kubernetes的语法
kubectl [command] [TYPE] [NAME] [flags]
command:指定要对一个或多个资源执行的操作,例如create、get、describe、delete
TYPE:指定资源类型,资源类型不区分大小写,可以指定单数、复数或缩写形式
NAME:指定资源的名称,名称区分大小写
fags:指定可选的参数。例如,可以使用-s或-server参数指定Kubernetes API服务器的地址和端口

8.1 Yaml语法

注意每个层级之间的点(.),在YAML文件中,每个层级之间一般用两个空格来表
root@k8s-master:~# kubectl explain Pod.metadata
KIND: Pod
VERSION: v1
FIELD: metadata <ObjectMeta>
...8.1.1 生成YAML文件框架
通过在创建资源时加上—dry-run=client –o yaml来生成YAML文件框架,可以用重定向到文件的方式生成文件,只需要稍作修改即可
root@k8s-master:~# kubectl create deployment --image httpd deployname --dry-run=client -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: deployname
name: deployname
spec:
replicas: 1
selector:
matchLabels:
app: deployname
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: deployname
spec:
containers:
- image: httpd
name: httpd
resources: {}
status: {}
# 重定向到文件
root@k8s-master:~# kubectl create deployment --image httpd deployname --dry-run=client -o yaml > k8s.yml8.1.2 apiVersion
Alpha:
1.版本名称包含了alpha
2.可能是有缺陷的。启用该功能可能会带来问题,默认是关闭的
3.支持的功能可能在没有通知的情况下随时删除
4.API的更改可能会带来兼容性问题,但是在后续的软件发布中不会有任何通知
5.由于bugs风险的增加和缺乏长期的支持,推荐在短暂的集群测试中使用。
Beta:
1.版本名称包含了beta
2.代码已经测试过。启用该功能被 认为是安全的,功能默认已启用
3.所有已支持的功能不会被删除,细节可能会发生变化
4.对象的模式和/或语义可能会在后续的beta测试版或稳定版中以不兼容的方式进行更改。
5.建议仅用于非业务关键型用途,因为后续版本中可能存在不兼容的更改。 如果有多个可以独立升级的集群,则可以放宽此限制
Stable:
1.版本名称是 vX,其中X是整数
2.功能的稳定版本将出现在许多后续版本的发行软件中
3.有时候也会被称为GA或者毕业等词汇
root@k8s-master:~# kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints
events ev v1 true Event
limitranges limits v1 true LimitRange
namespaces ns v1 false Namespace
nodes no v1 false Node
...
# 可以使用单数、复数、缩写
root@k8s-master:~# kubectl get configmaps
NAME DATA AGE
kube-root-ca.crt 1 5h17m
root@k8s-master:~# kubectl get cm
NAME DATA AGE
kube-root-ca.crt 1 5h17m
root@k8s-master:~# kubectl get configmap
NAME DATA AGE
kube-root-ca.crt 1 5h17m8.2 Namespace
Kubernetes支持多个虚拟集群,它们底层依赖于同一个物理集群。 这些虚拟集群被称为命名空间,它适用于存在很多跨多个团队或项目的用户的场景,命名空间为名称提供了一个范围
资源的名称需要在名字空间内是唯一的,但不能跨名字空间
名字空间不能相互嵌套,每个Kubernetes资源只能在一个名字空间中
命名空间是在多个用户之间通过资源配额划分集群资源的一种方法
root@k8s-master:~# kubectl get namespace
NAME STATUS AGE
calico-apiserver Active 3h18m
calico-system Active 3h18m
default Active 6h10m
kube-node-lease Active 6h10m
kube-public Active 6h10m
kube-system Active 6h10m
tigera-operator Active 3h33m
root@k8s-master:~# kubectl get pod
No resources found in default namespace.
root@k8s-master:~# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-76fccbbb6b-l7jq9 1/1 Running 0 6h14m
coredns-76fccbbb6b-nd68g 1/1 Running 0 6h14m
etcd-k8s-master 1/1 Running 0 6h15m
kube-apiserver-k8s-master 1/1 Running 0 6h14m
kube-controller-manager-k8s-master 1/1 Running 0 6h15m
kube-proxy-8n6x5 1/1 Running 0 169m
kube-proxy-mcwv7 1/1 Running 0 6h14m
kube-proxy-xk4h4 1/1 Running 0 169m
kube-scheduler-k8s-master 1/1 Running 0 6h15m8.2.1 命令行创建
root@k8s-master:~# kubectl create namespace luovip
namespace/luovip created
root@k8s-master:~# kubectl get namespace
NAME STATUS AGE
calico-apiserver Active 3h26m
calico-system Active 3h26m
default Active 6h18m
kube-node-lease Active 6h18m
kube-public Active 6h18m
kube-system Active 6h18m
luovip Active 7s
tigera-operator Active 3h41m8.2.2 YAML文件创建
cat > namespace.yml <<EOF
apiVersion: v1
kind: Namespace
metadata:
name: luovipyu
EOF
root@k8s-master:~# kubectl create -f namespace.yml
namespace/luovipyu created
root@k8s-master:~# kubectl get namespace
NAME STATUS AGE
calico-apiserver Active 3h33m
calico-system Active 3h33m
default Active 6h25m
kube-node-lease Active 6h25m
kube-public Active 6h25m
kube-system Active 6h25m
luovip Active 6m54s
luovipyu Active 26s
tigera-operator Active 3h48m8.2.3 删除namespace
root@k8s-master:~# kubectl delete namespace luovipyu # 会删除名字空间下的所有内容
namespace "luovipyu" deleted
root@k8s-master:~# kubectl create -f namespace.yml
namespace/luovipyu created
root@k8s-master:~# cat namespace.yml
apiVersion: v1
kind: Namespace
metadata:
name: luovipyu
root@k8s-master:~# kubectl get namespace
NAME STATUS AGE
calico-apiserver Active 3h39m
calico-system Active 3h39m
default Active 6h30m
kube-node-lease Active 6h30m
kube-public Active 6h30m
kube-system Active 6h30m
luovip Active 12m
luovipyu Active 13s
tigera-operator Active 3h54m8.2.4 创建带有namespace属性的资源
root@k8s-master:~# kubectl run httpd --image=httpd --namespace=luovipyu
pod/httpd created
root@k8s-master:~# kubectl get pod -n luovipyu
NAME READY STATUS RESTARTS AGE
httpd 1/1 Running 0 18s
nginx 0/1 ImagePullBackOff 0 106s
# 每次查询和创建资源都需要带–namespace=luovipyu挺麻烦,可以设置默认值
root@k8s-master:~# kubectl config set-context --current --namespace=luovipyu
Context "kubernetes-admin@kubernetes" modified.
root@k8s-master:~# kubectl config view | grep namespace
namespace: luovipyu
root@k8s-master:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
httpd 1/1 Running 0 3m3s
nginx 0/1 ImagePullBackOff 0 4m31s
# 删除namespace会删除其下所有资源,但如果要删除已经切换为默认值的namespace时,可能会卡住,所以先把默认值切换为其他,然后再删除
root@k8s-master:~# kubectl config set-context --current --namespace=default
Context "kubernetes-admin@kubernetes" modified.
root@k8s-master:~# kubectl delete namespaces luovip luovipyu
namespace "luovip" deleted
namespace "luovipyu" deleted
root@k8s-master:~# kubectl get namespace
NAME STATUS AGE
calico-apiserver Active 3h49m
calico-system Active 3h49m
default Active 6h41m
kube-node-lease Active 6h41m
kube-public Active 6h41m
kube-system Active 6h41m
tigera-operator Active 4h4m8.3 CRD自定义资源
CRD(Custom Resource Definition,自定义资源定义)是Kubernetes提供的一种扩展机制,允许用户通过YAML文件定义自定义资源类型,并将其注册到Kubernetes API中,使其与内置资源(如Pod、 Deployment)一样被管理
本质:CRD是对自定义资源的元数据描述,定义了资源的名称、结构、版本、作用域等
作用:扩展Kubernetes API,支持用户自定义资源的管理和自动化操作
CRD核心字段:
| 字段 | 说明 | 示例 |
|---|---|---|
| apiVersion | CRD的API版本,固定为apiextensions.k8s.io/v1 | apiVersion:apiextensions.k8s.io/v1 |
| kind | 资源类型,固定为CustomResourceDefinition | kind: CustomResourceDefinition |
| metadata | 元数据,如名称、命名空间等(名称需符合DNS子域名规则) | name:crontabs.stable.example.com |
| spec | 核心配置,包括 API组、版本、资源范围 (Namespaced/Cluster)、字段验证规则等 | group: stable.example.com |
| versions | 支持的API版本列表,需指定至少一个存储版本( storage:true) | version:[v1][@ref) |
| names | 资源的复数形式、单数形式、简称等(如plural:crontabs) | plural: crontabs |
| scope | 资源作用域,Namespaced(命名空间级别)或Cluster(集群级别) | scope: Namespaced |
8.3.1 CRD介绍
K8S资源类型不止有namespace,还有很多,不过那都是系统自带的,现在我们来看看怎么自定义k8s中的资源
1.什么是CRD?
CRD(Custom Resource Definition)是 Kubernetes 提供的一种机制,允许用户定义自己的资源类型
这些自定义资源可以像 Kubernetes 原生资源(如 Pod、Service、Deployment 等)一样被管理。
2.为什么需要CRD?
扩展 Kubernetes API:Kubernetes 的原生资源可能无法满足所有用户的需求。CRD 允许用户定义自己的资源类型,从而扩展 Kubernetes 的功能。
管理复杂应用:有些应用可能需要管理一些特定的资源,这些资源不属于Kubernetes原生支持的范围。通过CRD可以将这些资源纳入 Kubernetes的管理范围,实现统一的资源管理
3.CRD的作用
定义资源结构:CRD 允许你定义资源的结构,包括其字段和数据类型
管理资源生命周期:Kubernetes 将为你管理这些自定义资源的生命周期,包括创建、更新、删除等操作
集成 Kubernetes 生态系统:CRD 可以与 Kubernetes 的其他组件(如控制器、操作符等)集成,实现更复杂的业务逻辑
在Kubernetes 的自定义资源定义(CRD)中,CRD 本身只定义了资源的结构和 API,但它不会直接执行任何创建、更新或删除操作。这些操作需要通过一个控制器(Controller)来实现。控制器是一个独立的程序,它监听 CRD 的变化,并根据这些变化执行实际的操作
8.3.2 查询CRD以及API资源
1.先看看系统中的api资源都有哪些,然后创建一个
root@k8s-master:~# kubectl api-resources
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
componentstatuses cs v1 false ComponentStatus
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints
events ev v1 true Event
limitranges limits v1 true LimitRange
namespaces ns v1 false Namespace
nodes no v1 false Node
...2.查看现在都有哪些自定义资源
# 以下资源不属于K8s,但是k8s是有的
root@k8s-master:~# kubectl get crd
NAME CREATED AT
adminnetworkpolicies.policy.networking.k8s.io 2025-05-17T03:05:26Z
apiservers.operator.tigera.io 2025-05-17T03:05:26Z
bgpconfigurations.crd.projectcalico.org 2025-05-17T03:05:26Z
bgpfilters.crd.projectcalico.org 2025-05-17T03:05:26Z
bgppeers.crd.projectcalico.org 2025-05-17T03:05:26Z
blockaffinities.crd.projectcalico.org 2025-05-17T03:05:26Z
caliconodestatuses.crd.projectcalico.org 2025-05-17T03:05:26Z
clusterinformations.crd.projectcalico.org 2025-05-17T03:05:26Z
felixconfigurations.crd.projectcalico.org 2025-05-17T03:05:26Z
globalnetworkpolicies.crd.projectcalico.org 2025-05-17T03:05:26Z
globalnetworksets.crd.projectcalico.org 2025-05-17T03:05:26Z
hostendpoints.crd.projectcalico.org 2025-05-17T03:05:26Z
imagesets.operator.tigera.io 2025-05-17T03:05:26Z
installations.operator.tigera.io 2025-05-17T03:05:26Z
ipamblocks.crd.projectcalico.org 2025-05-17T03:05:26Z
ipamconfigs.crd.projectcalico.org 2025-05-17T03:05:26Z
ipamhandles.crd.projectcalico.org 2025-05-17T03:05:26Z
ippools.crd.projectcalico.org 2025-05-17T03:05:26Z
ipreservations.crd.projectcalico.org 2025-05-17T03:05:26Z
kubecontrollersconfigurations.crd.projectcalico.org 2025-05-17T03:05:26Z
networkpolicies.crd.projectcalico.org 2025-05-17T03:05:26Z
networksets.crd.projectcalico.org 2025-05-17T03:05:26Z
tiers.crd.projectcalico.org 2025-05-17T03:05:26Z
tigerastatuses.operator.tigera.io 2025-05-17T03:05:26Z8.3.3 创建CRD以及API资源
1.创建一个自己的crd,crd将注册为api资源
cat > crd.yaml <<-'EOF'
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# 名字必需与下面的 spec 字段匹配,并且格式为 '<名称的复数形式>.<组名>'
name: crontabs.stable.example.com
spec:
# 组名称,用于 REST API:/apis/<组>/<版本>
group: stable.example.com
# 列举此 CustomResourceDefinition 所支持的版本
versions:
- name: v1
# 每个版本都可以通过 served 标志来独立启用或禁止
served: true
# 其中一个且只有一个版本必需被标记为存储版本
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
# 可以是 Namespaced 或 Cluster
scope: Namespaced
names:
# 名称的复数形式,用于 URL:/apis/<组>/<版本>/<名称的复数形式>
plural: crontabs
# 名称的单数形式,作为命令行使用时和显示时的别名
singular: crontab
# kind 通常是单数形式的驼峰命名(CamelCased)形式。你的资源清单会使用这一形式。
kind: CronTab
# shortNames 允许你在命令行使用较短的字符串来匹配资源
shortNames:
- ct
EOF
root@k8s-master:~# kubectl apply -f crd.yaml
customresourcedefinition.apiextensions.k8s.io/crontabs.stable.example.com created2.再看就会有自己的crd资源和api资源了
root@k8s-master:~# kubectl get crd
NAME CREATED AT
...
crontabs.stable.example.com 2025-05-17T06:16:04Z
...
root@k8s-master:~# kubectl api-resources | grep crontabs
NAME SHORTNAMES APIVERSION NAMESPACED KIND
crontabs ct stable.example.com/v1 true CronTab
root@k8s-master:~# kubectl describe crd crontabs.stable.example.com8.3.4 查询API资源结构与参数
既然已经注册为api资源,来看看能否explain字段?
root@k8s-master:~# kubectl explain crontabs
GROUP: stable.example.com
KIND: CronTab
VERSION: v1
DESCRIPTION:
<empty>
FIELDS:
apiVersion <string>
kind <string>
metadata <ObjectMeta>
spec <Object>
...
# 查看有哪些spec
root@k8s-master:~# kubectl explain crontabs.spec
GROUP: stable.example.com
KIND: CronTab
VERSION: v1
FIELD: spec <Object>
DESCRIPTION:
<empty>
FIELDS:
cronSpec <string>
<no description>
image <string>
<no description>
replicas <integer>
<no description>
# 一切正常,看来已经创建了自定义资源,接下来就是等开发人员通过编程等方式创建operator等控制器,来使用我们的资源了9 Pod
9.1 关于pod
Pod由一个或多个紧密耦合的容器组成
它们之间共享网络、存储等资源
pod是Kubernetes中最小的工作单元
Pod中的容器会一起启动和停止
9.2 Pod生命周期
Pod遵循一个预定义的生命周期,起始于Pending阶段,如果至少其中有一个主要容器正常启动,则进入Running,之后取决于Pod中是否有容器以失败状态结束而进入Succeeded或者Failed阶段。但有时集群节点之间出现网络故障,无法获取Pod状态时,就会出现Unknown状态
9.3 创建Pod
1.一个Pod中只有一个业务容器
# 1.yml文件创建pod
cat > pod.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: luovippod
spec:
containers:
- name: hello
image: httpd
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'echo "Hello, China!" && sleep 3600']
restartPolicy: OnFailure
EOF
root@k8s-master:~# kubectl create -f pod.yml
pod/luovippod created
root@k8s-master:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
luovippod 1/1 Running 0 5s
root@k8s-master:~# kubectl logs luovippod
Hello, China!
root@k8s-master:~# kubectl delete pod luovippod 删除pod
# 2.命令行创建pod
root@k8s-master:~# kubectl run luoyupod --image=nginx --port=80
pod/luoyupod created
root@k8s-master:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
luovippod 1/1 Running 0 7m56s
luoyupod 1/1 Running 0 3m38s
root@k8s-master:~# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
luovippod 1/1 Running 0 8m6s 172.16.194.71 k8s-worker1 <none> <none>
luoyupod 1/1 Running 0 3m48s 172.16.194.72 k8s-worker1 <none> <none>2.一个Pod中有多个业务容器
cat > multicontainer.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: pod
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'echo "Hello, luoyu!" && sleep 3600']
- name: httpd
image: httpd
imagePullPolicy: IfNotPresent
ports:
- name: web
containerPort: 80
restartPolicy: OnFailure
EOF
root@k8s-master:~# kubectl create -f multicontainer.yml
pod/pod created
root@k8s-master:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
luovippod 1/1 Running 0 18m
luoyupod 1/1 Running 0 14m
pod 2/2 Running 0 9s
root@k8s-master:~# kubectl get -f multicontainer.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod 2/2 Running 0 68s 172.16.126.3 k8s-worker2 <none> <none>
root@k8s-master:~# curl 172.16.126.39.4 修改Pod
# 直接修改yaml文件,然后执行以下命令
kubectl apply -f pod.yml
# 编辑Etcd数据
kubectl edit pod luovippod
# patch参数
kubectl get pod luovippod -o json
kubectl get pod luovippod -o json | grep cnlxh
注明:工作中的修改pod一般时k8s会创建新的pod并删除旧的pod9.5 进入pod中的容器
root@k8s-master:~# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
luovippod 1/1 Running 0 37m 172.16.194.71 k8s-worker1 <none> <none>
luoyupod 1/1 Running 0 33m 172.16.194.72 k8s-worker1 <none> <none>
pod 2/2 Running 0 19m 172.16.126.3 k8s-worker2 <none> <none>
root@k8s-master:~# kubectl exec -it pod -c httpd -- /bin/bash
root@pod:/usr/local/apache2# echo MyCity is ChengDu! > htdocs/index.html
root@pod:/usr/local/apache2# exit
exit
root@k8s-master:~# curl http://172.16.126.3
MyCity is ChengDu!
#参数说明:
1、-c 参数可以指定需要进入pod中的哪个容器
2、-- 是K8S命令和预期容器内部执行命令的连接符
3、/bin/sh是指进入容器中执行什么命令
4、退出执行exit9.6 Init类型容器
Init容器是一种特殊容器,在Pod内的应用容器启动之前运行,如果Pod的Init容器失败,kubelet会不断地重启该 Init 容器直到该容器成功为止。 然而,如果 Pod 对应的 restartPolicy 值为 “Never”,并且 Pod的 Init 容器失败, 则 Kubernetes 会将整个 Pod 状态设置为失败
Init容器与普通的容器非常像,除了如下两点:
1.正常情况下,它们最终都会处于completed状态
2.每个都必须在下一个启动之前成功完成
# 根据安排,myapp-container的容器将等待两个init结束之后才会启动,也就是40秒之后才会启动
cat > init.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: initpd
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'echo The app is running! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', "sleep 20"]
- name: init-mydb
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', "sleep 20"]
EOF
root@k8s-master:~# kubectl create -f init.yml
pod/initpd created
# -w参数可以实时查看pod的状态变化
root@k8s-master:~# kubectl get -f init.yml -w
NAME READY STATUS RESTARTS AGE
initpd 0/1 Init:0/2 0 19s
initpd 0/1 Init:1/2 0 21s
initpd 0/1 Init:1/2 0 22s
initpd 0/1 PodInitializing 0 42s
initpd 1/1 Running 0 43s
root@k8s-master:~# kubectl get pod -w
NAME READY STATUS RESTARTS AGE
initpd 0/1 Init:1/2 0 34s
luovippod 1/1 Running 0 56m
luoyupod 1/1 Running 0 51m
pod 2/2 Running 0 37m
root@k8s-master:~# kubectl get pods
NAME READY STATUS RESTARTS AGE
initpd 1/1 Running 0 104s
luovippod 1/1 Running 0 57m
luoyupod 1/1 Running 0 52m
pod 2/2 Running 0 39m9.7 Sidecar类型容器
一般来讲,Sidecar容器可以:
1.日志代理/转发,例如 fluentd
2.Service Mesh,比如 Istio,Linkerd
3.代理,比如 Docker Ambassador
4.探活:检查某些组件是不是正常工作
5.其他辅助性的工作,比如拷贝文件,下载文件等

# 两个容器挂载了同一个目录,一个容器负责写入数据,一个容器负责对外展示
cat > sidecar.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: sidecarpod
spec:
containers:
- name: httpd
image: httpd
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /usr/local/apache2/htdocs/
name: luoyuvolume
- name: busybox
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'echo "Hello sidecar" > /usr/local/apache2/htdocs/index.html && sleep 3600']
volumeMounts:
- mountPath: /usr/local/apache2/htdocs/
name: luoyuvolume
restartPolicy: OnFailure
volumes:
- name: luoyuvolume
emptyDir: {}
EOF
root@k8s-master:~# kubectl create -f sidecar.yml
pod/sidecarpod created
root@k8s-master:~# kubectl get -f sidecar.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
sidecarpod 2/2 Running 0 9s 172.16.194.74 k8s-worker1 <none> <none>
root@k8s-master:~# curl http://172.16.194.74
Hello sidecar9.8 静态Pod
静态 Pod 在指定的节点上由 kubelet 守护进程直接管理,不需要 API 服务器监管。 与由控制面管理的Pod(例如,Deployment) 不同;kubelet 监视每个静态 Pod(在它崩溃之后重新启动)
静态 Pod 永远都会绑定到一个指定节点上的 Kubelet
kubelet 会尝试通过 Kubernetes API 服务器为每个静态 Pod 自动创建一个 mirror Pod。 这意味着节点上运行的静态 Pod 对 API 服务来说是可见的,但是不能通过 API 服务器来控制。 Pod 名称将把以连字符开头的节点主机名作为后缀
运行中的 kubelet 会定期扫描配置的目录中的变化, 并且根据文件中出现/消失的 Pod 来添加/删除Pod
1.查找静态pod的编写路径
root@k8s-master:~# systemctl status kubelet
...
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
...
root@k8s-master:~# tail /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf
[Service]
...
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
...
root@k8s-master:~# grep -i static /var/lib/kubelet/config.yaml
staticPodPath: /etc/kubernetes/manifests2.编写静态pod
cat > static.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: staticpod
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'echo "Hello, lixiaohui!" && sleep 3600']
restartPolicy: OnFailure
EOF
# 把这个yaml文件复制到/etc/kubernetes/manifests,然后观察pod列表,然后把yaml文件移出此文件夹,再观察pod列表
root@k8s-master:~# cp static.yml /etc/kubernetes/manifests/
root@k8s-master:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
initpd 1/1 Running 0 40m
luovippod 0/1 Completed 0 95m
luoyupod 1/1 Running 0 91m
pod 1/2 NotReady 0 77m
sidecarpod 2/2 Running 0 31m
staticpod-k8s-master 1/1 Running 0 12s
# 删除/etc/kubernetes/manifests文件中的yml文件,再观察pod列表
root@k8s-master:~# rm -rf /etc/kubernetes/manifests/static.yml
root@k8s-master:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
initpd 1/1 Running 0 41m
luovippod 0/1 Completed 0 97m
luoyupod 1/1 Running 0 92m
pod 1/2 NotReady 0 78m
sidecarpod 2/2 Running 0 32m
# 维持集群运行的文件如下:
root@k8s-master:/etc/kubernetes/manifests# ls
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml static.yml9.9 Pod删除
kubectl delete pod –all会删除所有pod
kubectl delete pod pod名称—删除指定的pod
root@k8s-master:~# kubectl get pods
NAME READY STATUS RESTARTS AGE
initpd 1/1 Running 0 13m
luovippod 1/1 Running 0 9m23s
luoyupod 1/1 Running 0 169m
pod 2/2 Running 0 7m51s
sidecarpod 2/2 Running 0 27s
staticpod-k8s-master 1/1 Running 0 2s
root@k8s-master:~# kubectl delete pod luovippod
root@k8s-master:~# kubectl delete pod -all
root@k8s-master:~# kubectl get pods
No resources found in default namespace.
root@k8s-master:~# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-76fccbbb6b-l7jq9 1/1 Running 0 35h
coredns-76fccbbb6b-nd68g 1/1 Running 0 35h
etcd-k8s-master 1/1 Running 0 35h
kube-apiserver-k8s-master 1/1 Running 0 35h
kube-controller-manager-k8s-master 1/1 Running 0 35h
kube-proxy-8n6x5 1/1 Running 0 32h
kube-proxy-mcwv7 1/1 Running 0 35h
kube-proxy-xk4h4 1/1 Running 0 32h
kube-scheduler-k8s-master 1/1 Running 0 35h10 Kubernetes控制器
10.1 什么是控制器
当你设置了温度,告诉了空调遥控器你的期望状态(Desired State)。 房间的实际温度是当前状态(Current State)。 通过对遥控器的开关控制,遥控器让其当前状态接近期望状态
在 Kubernetes 中,控制器通过监控集群的公共状态,并致力于将当前状态转变为期望的状态
作为设计原则之一,Kubernetes 使用了很多控制器,每个控制器管理集群状态的一个特定方面。 最常见的一个特定的控制器使用一种类型的资源作为它的期望状态, 控制器管理控制另外一种类型的资源向它的期望状态演化
10.2 Replica Set概念
ReplicationController确保在任何时候都有特定数量的Pod副本处于运行状态。 换句话说,ReplicationController 确保一个 Pod 或一组同类的 Pod 总是可用的
ReplicaSet的目的是维护一组在任何时候都处于运行状态的 Pod 副本的稳定集合。 因此,它通常用来保证给定数量的、完全相同的 Pod 的可用性。
说明: 现在推荐使用配置ReplicaSet的Deployment来建立副本管理机制
10.3 Replica Set 工作原理
RepicaSet是通过一组字段来定义的,包括一个用来识别可获得的 Pod 的集合的选择算符、一个用来标明应该维护的副本个数的数值、一个用来指定应该创建新 Pod 以满足副本个数条件时要使用的 Pod 模板等等。 每个 ReplicaSet 都通过根据需要创建和 删除 Pod 以使得副本个数达到期望值, 进而实现其存在价值。当 ReplicaSet 需要创建新的 Pod 时,会使用所提供的 Pod 模板
1.ReplicaSet也需要apiVersion、kind和metadata字段
2.Pod 选择算符:.spec.selector 字段是一个标签选择算符。在 ReplicaSet 中,.spec.template.metadata.labels 的值必须与 spec.selector 值 相匹配,否则该配置会被API拒绝
3.可以通过设置 .spec.replicas 来指定要同时运行的 Pod个数。 ReplicaSet 创建、删除 Pods 以与此值匹配
10.4 ReplicaSet使用
使用nginx镜像创建具有3个pod的RS,并分配合适的标签
10.4.1 创建yml文件
cat > rs.yml <<EOF
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginxrstest
labels:
app: nginxrstest
spec:
replicas: 3
selector:
matchLabels:
app: nginxrstest
template:
metadata:
labels:
app: nginxrstest
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
imagePullPolicy: IfNotPresent
EOF10.4.2 操作ReplicaSet
root@k8s-master:~# kubectl create -f rs.yml
root@k8s-master:~# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginxrstest 3 3 3 3m45s
root@k8s-master:~# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginxrstest-5bvpr 1/1 Running 0 7m1s app=nginxrstest
nginxrstest-9d86s 1/1 Running 0 7m1s app=nginxrstest
nginxrstest-k79cw 1/1 Running 0 7m1s app=nginxrstest
# 被动高可用
root@k8s-master:~# kubectl delete pod --all
pod "nginxrstest-5bvpr" deleted
pod "nginxrstest-9d86s" deleted
pod "nginxrstest-k79cw" deleted
root@k8s-master:~# kubectl get replicasets.apps,pods
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginxrstest 3 3 3 12m
NAME READY STATUS RESTARTS AGE
pod/nginxrstest-86dd7 1/1 Running 0 3m6s
pod/nginxrstest-bbzxd 1/1 Running 0 3m6s
pod/nginxrstest-ndgxg 1/1 Running 0 3m6s
# 扩容
root@k8s-master:~# kubectl scale replicaset nginxrstest --replicas 4
replicaset.apps/nginxrstest scaled
root@k8s-master:~# kubectl get replicasets.apps nginxrstest
NAME DESIRED CURRENT READY AGE
nginxrstest 4 4 4 16m
root@k8s-master:~# kubectl get replicasets.apps,pods -o wide
# 删除
root@k8s-master:~# kubectl delete replicasets.apps nginxrstest
replicaset.apps "nginxrstest" deleted
root@k8s-master:~# kubectl get pod
No resources found in default namespace.10.5 Deployment
ReplicaSet确保任何时间都有指定数量的Pod副本在运行。 然而,Deployment是一个更高级的概念,它管理ReplicaSet,并向Pod提供声明式的更新以及许多其他有用的功能。 因此,建议使用 Deployment 而不是直接使用 ReplicaSet,除非需要自定义更新业务流程或根本不需要更新
这实际上意味着,可能永远不需要操作ReplicaSet对象:而是使用Deployment,并在spec部分定义应用

10.5.1 创建yml文件
cat > deployment.yml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
EOF10.5.2 创建Deployment
# 使用nginx镜像创建具有3个副本的Deployment,并分配合适的属性
# 发现deployment管理了一个RS,而RS又实现了3个pod
root@k8s-master:~# kubectl create -f deployment.yml
deployment.apps/nginx-deployment created
root@k8s-master:~# kubectl get deployment.apps
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 20s
# kubectl get pods --show-labels(可选)
Deployment控制器将pod-template-hash标签添加到Deployment所创建或收留的每个ReplicaSet,此标签可确保Deployment的子 ReplicaSets不重叠
root@k8s-master:~# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-8d94c585f-ngm9d 1/1 Running 0 51s app=nginx,pod-template-hash=8d94c585f
nginx-deployment-8d94c585f-wf4mc 1/1 Running 0 51s app=nginx,pod-template-hash=8d94c585f
nginx-deployment-8d94c585f-wjzkw 1/1 Running 0 51s app=nginx,pod-template-hash=8d94c585f
root@k8s-master:~# kubectl get deployments.apps,replicasets.apps,pods -l app=nginx
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deployment 3/3 3 3 2m20s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-deployment-8d94c585f 3 3 3 2m20s
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-8d94c585f-ngm9d 1/1 Running 0 2m20s
pod/nginx-deployment-8d94c585f-wf4mc 1/1 Running 0 2m20s
pod/nginx-deployment-8d94c585f-wjzkw 1/1 Running 0 2m20s10.5.3 更新Deployment
1.将deployment的镜像更改一次
# Deployment的更新策略
root@k8s-master:~# kubectl get deployments.apps nginx-deployment -o yaml
apiVersion: apps/v1
kind: Deployment
...
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
...
root@k8s-master:~# kubectl set image deployments/nginx-deployment nginx=nginx:1.17.1 --record
Flag --record has been deprecated, --record will be removed in the future
deployment.apps/nginx-deployment image updated
# 查看更新的进度---更新过程是多了一个replicaset
root@k8s-master:~# kubectl rollout status deployment/nginx-deployment
Waiting for deployment "nginx-deployment" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 1 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 2 out of 3 new replicas have been updated...
Waiting for deployment "nginx-deployment" rollout to finish: 1 old replicas are pending termination...
Waiting for deployment "nginx-deployment" rollout to finish: 1 old replicas are pending termination...
deployment "nginx-deployment" successfully rolled out
root@k8s-master:~# kubectl get deployments.apps,replicasets.apps,pods -l app=nginx
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deployment 3/3 3 3 5m43s
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-deployment-5d457cdfc8 3 3 3 84s
replicaset.apps/nginx-deployment-8d94c585f 0 0 0 5m43s
NAME READY STATUS RESTARTS AGE
pod/nginx-deployment-5d457cdfc8-7whnx 1/1 Running 0 66s
pod/nginx-deployment-5d457cdfc8-b7njk 1/1 Running 0 84s
pod/nginx-deployment-5d457cdfc8-x4zv8 1/1 Running 0 55s2.更新的策略
# 首先创建了一个新的Pod,然后删除了一些旧的Pods, 并创建了新的Pods。不会杀死老Pods,直到有足够的数量新的Pods已经出现
# 在足够数量的旧Pods被杀死前并没有创建新Pods。确保至少2个Pod可用,同时最多总共4个pod可用
# Deployment可确保在更新时仅关闭一定数量的Pod。默认情况下确保至少所需Pods 75%处于运行状态(最大不可用比例为 25%)
root@k8s-master:~# kubectl describe deployments.apps nginx-deployment10.5.4 回滚Deployment
假设在更新时犯错误了,将镜像名称命名设置为nginx:1.172,而不是nginx:1.17.2,发现永远无法更新成功,此时就需要回退
root@k8s-master:~# kubectl set image deployments/nginx-deployment nginx=nginx:1.172 --record
Flag --record has been deprecated, --record will be removed in the future
deployment.apps/nginx-deployment image updated
root@k8s-master:~# kubectl rollout status deployment/nginx-deployment
Waiting for deployment "nginx-deployment" rollout to finish: 1 out of 3 new replicas have been updated...
# 镜像拉取失败
root@k8s-master:~# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-5d457cdfc8-7whnx 1/1 Running 0 7m50s
nginx-deployment-5d457cdfc8-b7njk 1/1 Running 0 8m8s
nginx-deployment-5d457cdfc8-x4zv8 1/1 Running 0 7m39s
nginx-deployment-6b7d6c469c-zcjps 0/1 ImagePullBackOff 0 92s
# 开始回滚
1.查看历史版本
root@k8s-master:~# kubectl rollout history deployments/nginx-deployment
deployment.apps/nginx-deployment
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image deployments/nginx-deployment nginx=nginx:1.17.1 --record=true
3 kubectl set image deployments/nginx-deployment nginx=nginx:1.172 --record=true
2.查看某个版本
root@k8s-master:~# kubectl rollout history deployment.v1.apps/nginx-deployment --revision=2
deployment.apps/nginx-deployment with revision #2
Pod Template:
Labels: app=nginx
pod-template-hash=5d457cdfc8
Annotations: kubernetes.io/change-cause: kubectl set image deployments/nginx-deployment nginx=nginx:1.17.1 --record=true
Containers:
nginx:
Image: nginx:1.17.1
Port: 80/TCP
Host Port: 0/TCP
Environment: <none>
Mounts: <none>
Volumes: <none>
Node-Selectors: <none>
Tolerations: <none>
3.回滚到某个版本
root@k8s-master:~# kubectl rollout undo deployments/nginx-deployment --to-revision=2
deployment.apps/nginx-deployment rolled back
root@k8s-master:~# kubectl rollout status deployment/nginx-deployment
deployment "nginx-deployment" successfully rolled out
root@k8s-master:~# kubectl get deployment.apps
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 3/3 3 3 23m10.5.5 伸缩Deployment
将指定的deployment副本更改为10
root@k8s-master:~# kubectl scale deployments/nginx-deployment --replicas=10
deployment.apps/nginx-deployment scaled
root@k8s-master:~# kubectl get deployments.apps,replicasets.apps -l app=nginx
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deployment 10/10 10 10 25m
NAME DESIRED CURRENT READY AGE
replicaset.apps/nginx-deployment-5d457cdfc8 10 10 10 21m
replicaset.apps/nginx-deployment-6b7d6c469c 0 0 0 14m
replicaset.apps/nginx-deployment-8d94c585f 0 0 0 25m
root@k8s-master:~# kubectl delete deployments.apps nginx-deployment10.6 DaemonSet
DaemonSet确保全部(或某些)节点上运行一个 Pod 的副本。 当有节点加入集群时, 也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除DaemonSet将会删除它创建的所有Pod
DaemonSet 的一些典型用法:
1.在每个节点上运行集群守护进程
2.在每个节点上运行日志收集守护进程
3.在每个节点上运行监控守护进程

使用busybox镜像,在每一个节点上都运行一个pod:
cat > daemonset.yml <<EOF
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: luovip
labels:
daemonset: test
spec:
selector:
matchLabels:
name: testpod
template:
metadata:
labels:
name: testpod
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command: ['sh', '-c', 'sleep 3600']
EOF
root@k8s-master:~# kubectl create -f daemonset.yml
daemonset.apps/luovip created
root@k8s-master:~# kubectl get daemonsets.apps
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
luovip 2 2 2 2 2 <none> 19s
root@k8s-master:~# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
luovip-bxkmh 1/1 Running 0 95s 172.16.126.33 k8s-worker2 <none> <none>
luovip-fj5mz 1/1 Running 0 95s 172.16.194.105 k8s-worker1 <none> <none>
...
root@k8s-master:~# kubectl delete -f daemonset.ymlDaemonSet总结:
1.默认情况下, DaemonSet会在所有Node上创建一个Pod
2.如果将运行的pod删除,DaemonSet会自动启动一个新的
3.当有新节点加入集群时,会自动向其部署Pod
4.当节点离开集群时,其上的节点会销毁,而不会跑到其他节点上
10.7 StatefulSet
StatefulSet管理基于相同容器规约的一组 Pod。但和Deployment不同的是, StatefulSet为它们的每个Pod维护了一个有粘性的 ID。这些 Pod 是基于相同的规约来创建的, 但是不能相互替换:无论怎么调度,每个 Pod 都有一个永久不变的 ID
StatefulSets 对于需要满足以下一个或多个需求的应用程序很有价值:
1.稳定的、唯一的网络标识符
2.稳定的、持久的存储
3.有序的、优雅的部署和缩放
4.有序的、自动的滚动更新

10.7.1 创建yml文件
使用nginx镜像,创建一个副本数为3的有状态应用,并挂载本地目录到容器中
cat > statefulset.yml <<EOF
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.17.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumes:
- name: www
emptyDir: {}
EOF10.7.2 操作StatefulSet
# 发现创建的过程是有次序的,这也验证了有状态应用的启动顺序
root@k8s-master:~# kubectl create -f statefulset.yml
statefulset.apps/web created
root@k8s-master:~# kubectl get pods -w
NAME READY STATUS RESTARTS AGE
web-0 0/1 Pending 0 0s
web-0 0/1 Pending 0 0s
web-0 0/1 ContainerCreating 0 1s
web-0 0/1 ContainerCreating 0 1s
web-0 0/1 ErrImagePull 0 82s
web-0 0/1 ImagePullBackOff 0 96s
web-0 1/1 Running 0 108s
web-1 0/1 Pending 0 0s
web-1 0/1 Pending 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 0/1 ContainerCreating 0 0s
web-1 1/1 Running 0 11s
web-2 0/1 Pending 0 0s
web-2 0/1 Pending 0 0s
web-2 0/1 ContainerCreating 0 0s
web-2 0/1 ContainerCreating 0 0s
web-2 1/1 Running 0 1s
root@k8s-master:~# kubectl get pods
NAME READY STATUS RESTARTS AGE
web-0 1/1 Running 0 3m36s
web-1 1/1 Running 0 108s
web-2 1/1 Running 0 97s
root@k8s-master:~# kubectl delete -f statefulset.yml
statefulset.apps "web" deleted10.8 Job
不断打印CKA JOB字符串,失败最多重试4次
cat > job.yml <<EOF
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "while true;do echo CKA JOB;done"]
restartPolicy: Never
backoffLimit: 4
EOF
root@k8s-master:~# kubectl create -f job.yml
job.batch/pi created
root@k8s-master:~# kubectl get jobs,pods
NAME STATUS COMPLETIONS DURATION AGE
job.batch/pi Running 0/1 10s 10s
NAME READY STATUS RESTARTS AGE
pod/pi-rglzp 1/1 Running 0 10s
root@k8s-master:~# kubectl logs pi-rglzp
CKA JOB
CKA JOB
CKA JOB
...
root@k8s-master:~# kubectl delete -f job.yml
job.batch "pi" deleted10.9 CronJob
每分钟打印一次指定字符串
cat > cronjob.yml <<EOF
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjobtest
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
EOF
root@k8s-master:~# kubectl create -f cronjob.yml
cronjob.batch/cronjobtest created
root@k8s-master:~# kubectl get cronjobs,pod
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/cronjobtest */1 * * * * <none> False 0 34s 35s
NAME READY STATUS RESTARTS AGE
pod/cronjobtest-29127403-mb9qx 0/1 Completed 0 34s
root@k8s-master:~# kubectl logs cronjobtest-29127403-mb9qx
Mon May 19 08:43:01 UTC 2025
Hello from the Kubernetes cluster
root@k8s-master:~# kubectl get cronjobs,pod
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob.batch/cronjobtest */1 * * * * <none> False 0 9s 2m10s
NAME READY STATUS RESTARTS AGE
pod/cronjobtest-29127403-mb9qx 0/1 Completed 0 2m9s
pod/cronjobtest-29127404-9jmbj 0/1 Completed 0 69s
pod/cronjobtest-29127405-h5cc7 0/1 Completed 0 9s
# 关于展示的任务次数的显示等的修改
root@k8s-master:~# kubectl explain cronjob.spec
root@k8s-master:~# kubectl delete -f cronjob.yml
cronjob.batch "cronjobtest" deleted11 Service 服务发现
11.1 Service
Pod是非永久性资源,每个Pod都有自己的IP地址
如果一组Pod(称为“后端”)为集群内的其他Pod(称为“前端”)提供功能, 那么前端如何找出并跟踪要连接的IP地址,以便前端可以使用提供工作负载的后端部分
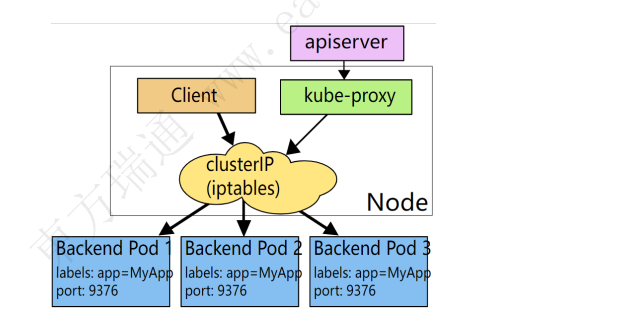
11.2 Service类型
ClusterIP:通过集群的内部IP暴露服务,选择该值时服务只能够在集群内部访问。 这也是默认的ServiceType
NodePort:通过每个节点上的IP和静态端口(NodePort)暴露服务。 NodePort服务会路由到自动创建的ClusterIP服务。 通过请求 <节点 IP>:<节点端口>,可以从集群的外部访问一个NodePort服务
LoadBalancer:使用云提供商的负载均衡器向外部暴露服务。 外部负载均衡器可以将流量路由到自动创建的NodePort服务和ClusterIP 服务上
ExternalName:通过返回CNAME和对应值,可以将服务映射到externalName字段的内容(例如,foo.bar.example.com)。 无需创建任何类型代理
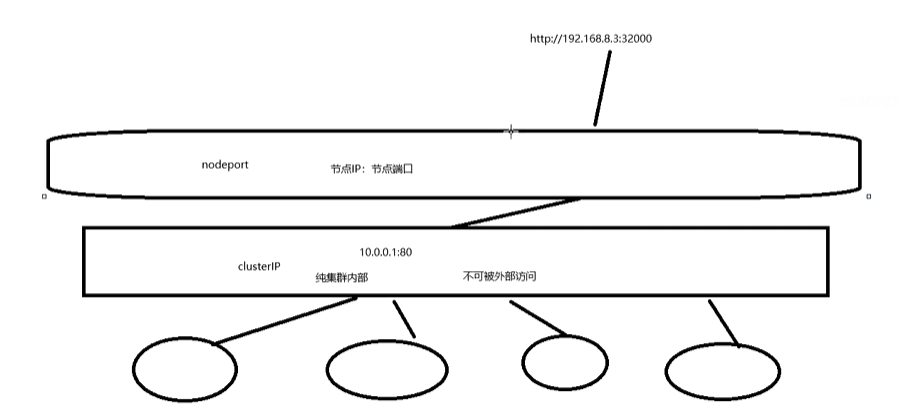
11.3 iptables代理模式的Service
kube-proxy会监视Kubernetes 控制节点对Service对象和Endpoints对象的添加和移除。 对每个Service,它会配置iptables规则,从而捕获到达该Service的clusterIP和端口的请求,进而将请求重定向到 Service 的一组后端中的某个Pod上面。 对于每个Endpoints对象,它也会配置iptables规则,这个规则会选择一个后端组合
默认的策略是,kube-proxy在iptables模式下随机选择一个后端
使用iptables处理流量具有较低的系统开销,因为流量由Linux netfilter处理, 而无需在用户空间和内核空间之间切换。 这种方法也可能更可靠
11.4 IPVS代理模式的Service
在ipvs模式下,kube-proxy监视Kubernetes服务和端点,调用netlink接口相应地创建IPVS规则, 并定期将IPVS规则与Kubernetes服务和端点同步。 该控制循环可确保IPVS 状态与所需状态匹配。访问服务时,IPVS将流量定向到后端Pod之一
IPVS代理模式基于类似于iptables模式的netfilter挂钩函数, 但是使用哈希表作为基础数据结构,并且在内核空间中工作。 这意味着,与 iptables模式下的kube-proxy相比,IPVS模式下的kube-proxy重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。 与其他代理模式相比,IPVS模式还支持更高的网络流量吞吐量
11.5 生成Service
11.5.1 准备后端Pod
用nginx镜像准备一个3副本的deployment作为后端,并开放80端口
cat > deployment-service.yml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment-servicetest
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
EOF
root@k8s-master:~# kubectl create -f deployment-service.yml
deployment.apps/nginx-deployment-servicetest created
root@k8s-master:~# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-servicetest-8d94c585f-6ktj9 1/1 Running 0 13s 172.16.126.35 k8s-worker2 <none> <none>
nginx-deployment-servicetest-8d94c585f-jclrr 1/1 Running 0 13s 172.16.194.117 k8s-worker1 <none> <none>
nginx-deployment-servicetest-8d94c585f-wgztv 1/1 Running 0 13s 172.16.194.116 k8s-worker1 <none> <none>
root@k8s-master:~# curl 172.16.126.3511.5.2 命令行生成Service
# 用kubectl expose的命令创建一个针对deployment的服务,并查询endpoint是否准备就绪
root@k8s-master:~# kubectl expose deployment nginx-deployment-servicetest --port=9000 --name=luoyuservice --target-port=80 --type=NodePort
service/luoyuservice exposed
root@k8s-master:~# kubectl get service,endpoints
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d13h
service/luoyuservice NodePort 10.105.8.223 <none> 9000:32646/TCP 26s
NAME ENDPOINTS AGE
endpoints/kubernetes 192.168.8.3:6443 2d13h
endpoints/luoyuservice 172.16.126.35:80,172.16.194.116:80,172.16.194.117:80 26s
root@k8s-master:~# curl http://192.168.8.3:32646
...
<title>Welcome to nginx!</title>
root@k8s-master:~# kubectl delete service luoyuservice
service "luoyuservice" deleted11.6 ClusterIP类型的Service
ClusterIP是默认的Service类型,对外提供8000端口,并把流量引流到具有app: nginx的后端80端口上
cat > clusterip.yml <<EOF
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 8000
targetPort: 80
EOF
root@k8s-master:~# kubectl create -f clusterip.yml
service/my-service created
root@k8s-master:~# kubectl get service,endpoints
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d2h
service/my-service ClusterIP 10.101.56.206 <none> 8000/TCP 2m35s
NAME ENDPOINTS AGE
endpoints/kubernetes 192.168.8.3:6443 3d2h
endpoints/my-service 172.16.126.35:80,172.16.194.116:80,172.16.194.117:80 2m35s
root@k8s-master:~# curl 10.101.56.206:8000
...
<title>Welcome to nginx!</title>
root@k8s-master:~# kubectl delete -f clusterip.yml
service "my-service" deleted11.7 NodePort类型的Service
Type: NodePort将会在节点的特定端口上开通服务,指定了端口为31788
cat > nodeport.yml <<EOF
apiVersion: v1
kind: Service
metadata:
name: nodeservice
spec:
type: NodePort
selector:
app: nginx
ports:
- protocol: TCP
port: 8000
targetPort: 80
nodePort: 31788
EOF
root@k8s-master:~# kubectl create -f nodeport.yml
service/nodeservice created
root@k8s-master:~# kubectl get service,endpoints
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d3h
service/nodeservice NodePort 10.102.124.139 <none> 8000:31788/TCP 27s
NAME ENDPOINTS AGE
endpoints/kubernetes 192.168.8.3:6443 3d3h
endpoints/nodeservice 172.16.126.35:80,172.16.194.116:80,172.16.194.117:80 27s
# 因为是nodeport,所以用节点IP
root@k8s-master:~# curl 192.168.8.4:31788
...
<title>Welcome to nginx!</title>
root@k8s-master:~# kubectl delete -f nodeport.yml
service "nodeservice" deleted11.8 Headless类型的Service
11.8.1 服务实现
在此类型的Service中,将不会只返回Service IP,会直接返回众多Pod 的IP地址,所以需要进入pod中用集群内DNS进行测试
cat > headless.yml <<EOF
apiVersion: v1
kind: Service
metadata:
name: headless
spec:
clusterIP: None
selector:
app: nginx
ports:
- protocol: TCP
port: 8000
targetPort: 80
EOF
root@k8s-master:~# kubectl create -f headless.yml
service/headless created
root@k8s-master:~# kubectl get service,endpoints
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/headless ClusterIP None <none> 8000/TCP 25s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d3h
NAME ENDPOINTS AGE
endpoints/headless 172.16.126.35:80,172.16.194.116:80,172.16.194.117:80 25s
endpoints/kubernetes 192.168.8.3:6443 3d3h11.8.2 测试Headless服务发现
root@k8s-master:~# kubectl run --rm --image=busybox:1.28 -it testpod
If you don't see a command prompt, try pressing enter.
/ # nslookup headless
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: headless
Address 1: 172.16.194.117 172-16-194-117.headless.default.svc.cluster.local
Address 2: 172.16.194.116 172-16-194-116.headless.default.svc.cluster.local
Address 3: 172.16.126.35 172-16-126-35.headless.default.svc.cluster.local
/ # exit
Session ended, resume using 'kubectl attach testpod -c testpod -i -t' command when the pod is running
pod "testpod" deleted
root@k8s-master:~# kubectl delete -f headless.yml
service "headless" deleted服务的DNS记录名称为:
servicename.namespace.svc.cluster.local
deployment中Pod的DNS记录名称为:
podIP.servicename.namespace.svc.cluster.local
Client访问服务时,可以使用DNS记录便捷抵达服务,甚至与服务在同一namespace时,直接用 servicename进行访问
11.9 LoadBalancer类型的Service
11.9.1 部署metallb负载均衡
1.先部署一个metallb controller和Speaker:
1.metallb controller用于负责监听Kubernetes Service的变化,当服务类型被设置为LoadBalancer时,Controller会从一个预先配置的IP地址池中分配一个 IP地址给该服务,并管理这个IP地址的生命周期
2.Speaker负责将服务的 IP 地址通过标准的路由协议广播到网络中,确保外部流量能够正确路由到集群中的服务
root@k8s-master:~# kubectl apply -f https://www.linuxcenter.cn/files/cka/cka-yaml/metallb-native.yaml2.定义一组由负载均衡对外分配的IP地址范围
cat > ippool.yml <<-EOF
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: lxh-ip-pool-192-168-8-10-100
namespace: metallb-system
spec:
addresses:
- 192.168.8.10-192.168.8.100
EOF
root@k8s-master:~# kubectl apply -f ippool.yml
ipaddresspool.metallb.io/lxh-ip-pool-192-168-8-10-100 created3.在 Layer 2 模式下用于控制如何通过 ARP(Address Resolution Protocol)或 NDP(Neighbor Discovery Protocol)协议宣告服务的 IP 地址,使得这些 IP 地址在本地网络中可解析
cat > l2Advertisement.yml <<-EOF
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: l2-myippool
namespace: metallb-system
spec:
ipAddressPools:
- lxh-ip-pool-192-168-8-10-100
EOF
root@k8s-master:~# kubectl apply -f l2Advertisement.yml
l2advertisement.metallb.io/l2-myippool created11.9.2 部署LoadBalancer服务
负载均衡准备好之后,创建LoadBalancer类型的服务
cat > loadbalancer.yml <<-EOF
apiVersion: v1
kind: Service
metadata:
name: loadbalance-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
type: LoadBalancer
EOF
root@k8s-master:~# kubectl apply -f loadbalancer.yml
service/loadbalance-service created
# 获取服务看看是否分配到了负载均衡IP 从输出上看,分配到了192.168.8.10
root@k8s-master:~# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d4h
loadbalance-service LoadBalancer 10.99.147.16 192.168.8.10 80:30972/TCP 10s
# 用负载均衡IP访问
root@k8s-master:~# curl 192.168.8.10
...
<title>Welcome to nginx!</title>
# 删除service资源
root@k8s-master:~# kubectl delete -f loadbalancer.yml
service "loadbalance-service" deleted11.10 Ingress
Ingress公开了从集群外部到集群内服务的HTTP和HTTPS路由
流量路由由Ingress资源上定义的规则控制
Ingress可以提供负载均衡、SSL卸载和基于名称的虚拟托管,为了让Ingress资源工作,集群必须有一个正在运行的Ingress控制器

11.10.1 Ingress控制器部署
Ingress需要Ingress控制器支持,先部署控制器
# 拉取v1.1.0版本的yaml文件
# 使用如下路径下载-可能会失败
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.1.0/deploy/static/provider/baremetal/deploy.yaml
root@k8s-master:~# wget https://www.linuxcenter.cn/files/cka/cka-yaml/ingressdeploy.yaml
# 从阿里云的镜像仓库上面拉取镜像
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/nginx-ingress-controller:v1.12.1
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhook-certgen:v1.5.2
# 在Kubernetes Ingress 的使用场景中,尤其是使用Ingress-Nginx作为 Ingress Controller 时,kube-webhook-certgen工具被用来创建和更新用于TLS认证的证书。这些证书被用于确保 Webhook 与 Kubernetes API 服务器之间的通信是安全的
# 修改ingressdeploy.yaml文件
440行改为 image: registry.cn-hangzhou.aliyuncs.com/google_containers/nginx-ingress-controller:v1.12.1
542行改为image: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhook-certgen:v1.5.2
596行改为 image: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhook-certgen:v1.5.2
root@k8s-master:~# kubectl apply -f ingressdeploy.yaml
root@k8s-master:~# kubectl get pod -n ingress-nginx
NAME READY STATUS RESTARTS AGE
ingress-nginx-admission-create-k9smq 0/1 Completed 0 17m
ingress-nginx-admission-patch-46hk7 0/1 Completed 2 17m
ingress-nginx-controller-47nzv 1/1 Running 0 17m
ingress-nginx-controller-svcpx 1/1 Running 0 17m
# admission相关pod状态为Completed为正常11.10.2 Ingress路径类型
Ingress中的每个路径都需要有对应的路径类型,未明确设置pathType的路径无法通过合法性检查。当前支持的路径类型有三种:
1.ImplementationSpecific:对于这种路径类型,匹配方法取决于IngressClass。 具体实现可以将其作为单独的pathType处理或者与Prefix或 Exact类型作相同处理
2.Exact:精确匹配URL路径,且区分大小写
3.Prefix:基于以 / 分隔的URL路径前缀匹配。匹配区分大小写,并且对路径中的元素逐个完成。 路径元素指的是由/分隔符分隔的路径中的标签列表。 如果每个p都是请求路径p的元素前缀,则请求与路径p匹配
11.10.3 Ingress的使用
用nginx镜像生成一个3副本的Pod,并通过Service提供服务,然后再用ingress,以特定域名的方式对外暴露
cat > ingress.yml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment-ingress
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: ingressservice
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: luovip
spec:
ingressClassName: nginx
rules:
- host: www.luovip.com
http:
paths:
- pathType: Prefix
path: "/"
backend:
service:
name: ingressservice
port:
number: 80
EOF
root@k8s-master:~# kubectl create -f ingress.yml
deployment.apps/nginx-deployment-ingress created
service/ingressservice created
ingress.networking.k8s.io/luovip created
root@k8s-master:~# kubectl get deployments,service,ingress
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/nginx-deployment-ingress 3/3 3 3 38s
deployment.apps/nginx-deployment-servicetest 3/3 3 3 24h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingressservice ClusterIP 10.98.162.124 <none> 80/TCP 38s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d13h
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/luovip nginx www.luovip.com 192.168.8.4,192.168.8.5 80 38s
# 把上述ADDRESS部分的IP和域名绑定解析
root@k8s-master:~# echo 192.168.8.4 www.luovip.com >> /etc/hosts
root@k8s-master:~# curl http://www.luovip.com
root@k8s-master:~# kubectl delete -f ingress.yml11.11 Gateway API
11.11.1 Gateway API 基本介绍
Kubernetes Gateway API 是一种新的 API 规范,旨在提供一种在 Kubernetes 中管理网关和负载均衡器的标准方法。它被设计为 Ingress API 的替代方案,提供更丰富的功能和更好的扩展性,Gateway API 的核心思想是通过使用可扩展的、角色导向的、协议感知的配置机制来提供网络服务。
Gateway API 包括几个核心组件:
1.GatewayClass:定义一组具有配置相同的网关,由实现该类的控制器管理。
2.Gateway:定义流量处理基础设施(例如云负载均衡器)的一个实例。
3.Route:描述了特定协议的规则,用于将请求从 Gateway 映射到 Kubernetes 服务。目前,HTTPRoute 是比较稳定的版本,而 TCPRoute、UDPRoute、GRPCRoute、TLSRoute 等也在开发中。
GatewayClass
定义:类似于Ingress 中的 IngressClass,定义了一组共享通用配置和行为的 Gateway 集合,类似于选择一种负载均衡的实现类型
作用:每个 GatewayClass 必须关联一个控制器(Controller),控制器负责处理 GatewayClass 和 Gateway 对象的变动,并创建或更新对应的网关和路由配置
特点:一般由第三方网关组件安装时自动创建,不需要人工手动创建
类似于阿里云负载均衡中的负载均衡实例类型选择。在阿里云中,用户可以选择应用型负载均衡(ALB)、网络型负载均衡(NLB)或传统型负载均衡(CLB),每种类型都有其特定的配置和功能
Gateway
定义:描述了流量被分配到集群中服务的方式,是 GatewayClass 的具体实现。
作用:负责流量接入以及往后转发。创建 Gateway 资源时,会根据 GatewayClass 生成对应的 Pod
特点:可以由管理员直接创建,也可以由控制 GatewayClass 的 Controller 创建
类似于阿里云负载均衡中的具体负载均衡实例。在阿里云中,用户创建一个负载均衡实例后,可以配置监听端口、协议等
Route
定义:描述了通过网关的流量如何映射到服务,例如 HTTPRoute 可以基于请求路径、主机名等条件将流量转发到不同的后端服务
作用:定义了流量的路由规则,将流量根据特定条件(如路径、请求头等)转发到不同的后端服务
类型:目前 Gateway API 提供了五种不同协议的 Route,分别是 HTTPRoute、TLSRoute、TCPRoute、UDPRoute 和 GRPCRoute
类似于阿里云负载均衡中的转发规则。在阿里云中,用户可以配置基于域名、路径、HTTP Header 等条件的转发规则
以下是使用 Gateway 和 HTTPRoute 将 HTTP 流量路由到服务的简单示例:

在此示例中,实现为反向代理的 Gateway 的请求数据流如下:
1.客户端开始准备 URL 为 http://test.lixiaohui.com 的 HTTP 请求
2.客户端的 DNS 解析器查询目标名称并了解与 Gateway 关联的一个或多个 IP 地址的映射。
3.客户端向 Gateway IP 地址发送请求;反向代理接收 HTTP 请求并使用 Host: 标头来匹配基于 Gateway 和附加的 HTTPRoute 所获得的配置。
4.可选的,反向代理可以根据 HTTPRoute 的匹配规则进行请求头和(或)路径匹配。
5.可选地,反向代理可以修改请求;例如,根据 HTTPRoute 的过滤规则添加或删除标头。
6.最后,反向代理将请求转发到一个或多个后端。
安装网址:https://docs.nginx.com/nginx-gateway-fabric/installation/installing-ngf/manifests/
11.1.2 Gateway API实验
实验步骤:
1.需要先做metallb,由metalb给service提供外部负载均衡IP
2.部署nginx Fabric,为GatewayAPI做后端流量处理组件
3.创建一个基于Fabric的gatewayClass
4.创建一个gateway,并监听在80端口,并关联刚创建的gatewayClass
5.创建一个httpRoute,此处定义客户端访问的域名和路径
实验效果:外部客户端可以用浏览器打开http://test.luovip.com 并返回我们的nginx业务网站内容
1.部署 Gateway API CRD
这一步用于扩展K8S功能,以便于支持Gateway API
# 方法1:
root@k8s-master:~# kubectl apply -f https://www.linuxcenter.cn/files/cka/gatewayapi/experimental-install.yaml
# 方法2:
root@k8s-master:~# wget https://www.linuxcenter.cn/files/cka/gatewayapi/experimental-install.yaml
root@k8s-master:~# kubectl apply -f experimental-install.yaml2.部署Fabric自定义资源
# 方法1:
root@k8s-master:~# kubectl apply -f https://www.linuxcenter.cn/files/cka/gatewayapi/nginx-fabric-crds.yaml
# 方法2:
root@k8s-master:~# wget https://www.linuxcenter.cn/files/cka/gatewayapi/nginx-fabric-crds.yaml
root@k8s-master:~# kubectl apply -f nginx-fabric-crds.yaml3.部署Fabric
这一步部署的Fabric用于处理后端流量处理
# 方法1:
root@k8s-master:~# kubectl apply -f https://www.linuxcenter.cn/files/cka/gatewayapi/nginx-fabric-deploy.yaml
# 方法2:
root@k8s-master:~# wget https://www.linuxcenter.cn/files/cka/gatewayapi/nginx-fabric-deploy.yaml
root@k8s-master:~# kubectl apply -f nginx-fabric-deploy.yaml
# 镜像使用:
ghcr.io/nginx/nginx-gateway-fabric:1.6.2
ghcr.io/nginx/nginx-gateway-fabric/nginx:1.6.2
可以使用国内南京大学的加速站点进行(在此感谢南京大学镜像站点团队提供的帮助),具体为将上述镜像替换为下面:
ghcr.nju.edu.cn/nginx/nginx-gateway-fabric:1.6.2
ghcr.nju.edu.cn/nginx/nginx-gateway-fabric/nginx:1.6.2
# 参考:
NGINX Gateway Fabric离线部署笔记
https://blog.51cto.com/huanghai/13946410
#等它部署好之后,看看pod起来没
root@k8s-master:~# kubectl get pod -n nginx-gateway -o wide
root@k8s-master:~# kubectl get pods -n nginx-gateway
NAME READY STATUS RESTARTS AGE
nginx-gateway-9cbb9b466-85ktc 2/2 Running 1 (56s ago) 72s
# 这里将会自动创建基于nginx的GatewayClass
root@k8s-master:~# kubectl get gatewayclasses.gateway.networking.k8s.io
NAME CONTROLLER ACCEPTED AGE
nginx gateway.nginx.org/nginx-gateway-controller True 17m4.部署应用
这里的应用是模拟公司的常规业务,稍后用于对外提供服务
cat > deployment-service.yml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: k8sgateway-luoviptest
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
EOF5.为了稳定pod的访问,用service的方式做了一个内部暴露
root@k8s-master:~# kubectl create -f deployment-service.yml
deployment.apps/k8sgateway-luoviptest created
root@k8s-master:~# kubectl expose deployment k8sgateway-lxhtest --port=9000 --name=lxhservice --target-port=80
service/lxhservice exposed6.业务应用
1.创建一个名为luovip-gateway的gateway并关联了一个名为nginx的gatewayClass,这个gateway提供了一个监听在80端口的http协议的监听器,这个监听器接收来自任何namespace以luovip.com为后缀的所有请求
2.创建一个名为luovip-http的httpRoute,并关联我们的gateway,本次httpRoute提供了test.luovip.com的域名根目录的请求入口,并将流量导入到一个名为luovipservice的9000端口
cat > gatewayandhttproute.yml <<-EOF
apiVersion: gateway.networking.k8s.io/v1
kind: Gateway
metadata:
name: luovip-gateway
spec:
gatewayClassName: nginx
listeners:
- name: default
hostname: "*.luovip.com"
port: 80
protocol: HTTP
allowedRoutes:
namespaces:
from: All
---
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: luovip-http
spec:
parentRefs:
- name: luovip-gateway
hostnames: ["test.luovip.com"]
rules:
- matches:
- path:
type: PathPrefix
value: /
backendRefs:
- name: lxhservice
port: 9000
EOF
root@k8s-master:~# kubectl apply -f gatewayandhttproute.yml
# gateway已经从负载均衡中,拿到了外部IP地址---192.168.8.10
root@k8s-master:~# kubectl get service -n nginx-gateway
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-gateway LoadBalancer 10.108.91.177 192.168.8.10 80:31093/TCP,443:30287/TCP 35m
# 服务后端也有endpoint
root@k8s-master:~# kubectl get endpoints -n nginx-gateway
NAME ENDPOINTS AGE
nginx-gateway 172.16.126.3:443,172.16.126.3:80 37m
# 查看gateway和httproute
root@k8s-master:~# kubectl get gateways
NAME CLASS ADDRESS PROGRAMMED AGE
luovip-gateway nginx 192.168.8.10 True 9m14s
root@k8s-master:~# kubectl get httproute
NAME HOSTNAMES AGE
luovip-http ["test.luovip.com"] 9m29s
# 访问测试
root@k8s-master:~# echo 192.168.8.10 test.luovip.com >> /etc/hosts
root@k8s-master:~# curl http://test.luovip.com12 健康检查
12.1 探测器概述
kubelet使用存活探测器(liveness probes)来知道什么时候要重启容器。 例如,存活探测器可以捕捉到死锁(应用程序在运行,但是无法继续执行后面的步骤)。 这样的情况下重启容器有助于让应用程序在有问题的情况下更可用。
kubelet使用就绪探测器(readiness probes)可以知道容器什么时候准备好了并可以开始接受请求流量, 当一个 Pod 内的所有容器都准备好了,才能把这个 Pod 看作就绪了。 在 Pod 还没有准备好的时候,会从 Service 的负载均衡器中被剔除的。
kubelet 使用启动探测器(startup probes)可以知道应用程序容器什么时候启动了。 可以控制容器在启动成功后再进行存活性和就绪检查, 确保这些存活、就绪探测器不会影响应用程序的启动。 这可以用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉。
顺序:1.启动探针工作完成—如果启动探针没完成,存活和就绪是不会开始的
2.存活、就绪探针开始工作
12.2 Liveness Probes
12.2.1 文件存活检测
创建一个名为liveness的容器,并在其中执行文件的创建,休眠,然后再删除文件的操作,然后用livenessProbe来检测
cat > liveness.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
EOF参数解释:
1.periodSeconds 字段指定了 kubelet 应该每 5 秒执行一次存活探测。
2.initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 5 秒。
3.kubelet 在容器内执行命令 cat /tmp/healthy 来进行探测。
4.如果命令执行成功并且返回值为 0,kubelet 就会认为这个容器是健康存活的。
5.如果这个命令返回非 0 值,kubelet 会杀死这个容器并重新启动它。
这个容器生命周期的前 30 秒, /tmp/healthy 文件是存在的。 所以在这最开始的 30 秒内,执行命令 cat /tmp/healthy 会返回成功代码。 30 秒之后,执行命令 cat /tmp/healthy 就会返回失败代码。
root@k8s-master:~# kubectl create -f liveness.yml
pod/liveness-exec created
# 每30秒在pod事件中就会显示存活探测器失败了,下方信息显示这个容器被杀死并且被重建了5次
root@k8s-master:~# kubectl get -f liveness.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
liveness-exec 1/1 Running 5 (26s ago) 6m41s 172.16.194.68 k8s-worker1 <none> <none>
root@k8s-master:~# kubectl describe pod liveness-exec
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 9m10s default-scheduler Successfully assigned default/liveness-exec to k8s-worker1
Normal Pulling 9m9s kubelet Pulling image "busybox"
Normal Pulled 9m6s kubelet Successfully pulled image "busybox" in 3.226s (3.226s including waiting). Image size: 4277910 bytes.
Normal Created 2m55s (x6 over 9m6s) kubelet Created container: liveness
Normal Started 2m55s (x6 over 9m6s) kubelet Started container liveness
Warning Unhealthy 2m10s (x18 over 8m35s) kubelet Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Normal Killing 2m10s (x6 over 8m25s) kubelet Container liveness failed liveness probe, will be restarted
Warning BackOff 21s (x8 over 100s) kubelet Back-off restarting failed container liveness in pod liveness-exec_default(b092160d-80d5-4edb-a593-726922c425e4)
Normal Pulled 6s (x6 over 7m55s) kubelet Container image "busybox" already present on machine
root@k8s-master:~# kubectl delete -f liveness.yml12.2.2 HTTP存活检测
以httpget的形式访问容器中的/luovip页面,根据返回代码来判断是否正常
cat > httpget.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: http
spec:
containers:
- name: httpd
image: httpd:2.2
imagePullPolicy: IfNotPresent
livenessProbe:
httpGet:
path: /luovip
port: 80
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
restartPolicy: OnFailure
EOF参数解释:
1.periodSeconds 字段指定了 kubelet 每隔 3 秒执行一次存活探测。
2.initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 3 秒。
3.kubelet 会向容器内运行的服务发送一个 HTTP GET 请求来执行探测。 如果服务器上 /PATH 路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。
4.如果处理程序返回失败代码,则 kubelet 会杀死这个容器并且重新启动它。
5.任何大于或等于 200 并且小于 400 的返回代码标示成功,其它返回代码都标示失败。
root@k8s-master:~# kubectl create -f httpget.yml
pod/http created
root@k8s-master:~# kubectl get -f httpget.yml
NAME READY STATUS RESTARTS AGE
http 1/1 Running 0 17s
root@k8s-master:~# kubectl get pods
NAME READY STATUS RESTARTS AGE
http 0/1 Completed 2 4m40s
root@k8s-master:~# kubectl describe pod http
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m22s default-scheduler Successfully assigned default/http to k8s-worker1
Normal Pulling 2m22s kubelet Pulling image "httpd:2.2"
Normal Pulled 2m7s kubelet Successfully pulled image "httpd:2.2" in 14.839s (14.839s including waiting). Image size: 171293537 bytes.
Normal Created 109s (x3 over 2m7s) kubelet Created container: httpd
Normal Started 109s (x3 over 2m7s) kubelet Started container httpd
Normal Pulled 109s (x2 over 118s) kubelet Container image "httpd:2.2" already present on machine
Warning Unhealthy 100s (x9 over 2m4s) kubelet Liveness probe failed: HTTP probe failed with statuscode: 404
Normal Killing 100s (x3 over 118s) kubelet Container httpd failed liveness probe, will be restarted
Warning BackOff 100s kubelet Back-off restarting failed container httpd in pod http_default(8d1f374c-ba01-4a4b-a8b1-dbba11736ccf)
root@k8s-master:~# kubectl delete -f httpget.yml12.3 ReadinessProbe
12.3.1 TCP存活检测
1.TCP 检测的配置和 HTTP 检测非常相似,同时使用就绪和存活探测器。
2.kubelet 会在容器启动 5 秒后发送第一个就绪探测。 这会尝试连接容器的800端口。如果探测成功,这个Pod会被标记为就绪状态,kubelet将继续每隔 10 秒运行一次检测。
3.除了就绪探测,这个配置包括了一个存活探测。 kubelet 会在容器启动 15 秒后进行第一次存活探测。 与就绪探测类似,会尝试连接器的800端口。 如果存活探测失败,这个容器会被重新启动。
cat > readiness.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: tcpcheck
spec:
containers:
- name: httpd
image: httpd:2.2
imagePullPolicy: IfNotPresent
ports:
- name: webport
protocol: TCP
containerPort: 80
readinessProbe:
tcpSocket:
port: 800
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 800
initialDelaySeconds: 15
periodSeconds: 20
restartPolicy: OnFailure
EOF
root@k8s-master:~# kubectl create -f readiness.yml
root@k8s-master:~# kubectl get pods
NAME READY STATUS RESTARTS AGE
tcpcheck 0/1 Running 1 (3s ago) 64s
root@k8s-master:~# kubectl describe pod tcpcheck
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m23s default-scheduler Successfully assigned default/tcpcheck to k8s-worker1
Normal Pulled 22s (x3 over 2m22s) kubelet Container image "httpd:2.2" already present on machine
Normal Created 22s (x3 over 2m22s) kubelet Created container: httpd
Normal Started 22s (x3 over 2m22s) kubelet Started container httpd
Normal Killing 22s (x2 over 82s) kubelet Container httpd failed liveness probe, will be restarted
Warning Unhealthy 2s (x7 over 2m2s) kubelet Liveness probe failed: dial tcp 172.16.194.70:800: connect: connection refused
Warning Unhealthy 1s (x14 over 2m10s) kubelet Readiness probe failed: dial tcp 172.16.194.70:800: connect: connection refused
# 可以看到,pod对外提供了80端口,但是我们一直在检测800端口,所以这个pod的检测是失败的
root@k8s-master:~# kubectl delete -f readiness.yml
pod "tcpcheck" deleted12.4 StartupProbe
1.有时候,会有一些现有的应用程序在启动时需要较多的初始化时间。 要不影响对引起探测死锁的快速响应,这种情况下,设置存活探测参数是要技巧的。 技巧就是使用一个命令来设置启动探测,针对HTTP 或者 TCP 检测,可以通过设置 failureThreshold * periodSeconds 参数来保证有足够长的时间应对糟糕情况下的启动时间。
2.应用程序将会有最多 30秒(3 * 10 = 30s) 的时间来完成它的启动。 一旦启动探测成功一次,存活探测任务就会接管对容器的探测,对容器死锁可以快速响应。 如果启动探测一直没有成功,容器会在 30 秒后被杀死,并且根据 restartPolicy 来设置 Pod 状态。
cat > startup.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: startprobe
spec:
containers:
- name: httpd
image: httpd:2.2
imagePullPolicy: IfNotPresent
ports:
- name: webport
protocol: TCP
containerPort: 80
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 10
startupProbe:
httpGet:
path: /
port: 800
initialDelaySeconds: 5
failureThreshold: 3
periodSeconds: 10
restartPolicy: OnFailure
EOFProbe参数:
Probe 有很多配置字段,可以使用这些字段精确的控制存活和就绪检测的行为:
1.initialDelaySeconds:容器启动后要等待多少秒后存活和就绪探测器才被初始化,默认是 0 秒,最小值是 0
2.periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1
3.timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1
4.successThreshold:探测器在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1
5.failureThreshold:当探测失败时,Kubernetes 的重试次数。 存活探测情况下的放弃就意味着重新启动容器。 就绪探测情况下的放弃 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1
root@k8s-master:~# kubectl create -f startup.yml
pod/startprobe created
root@k8s-master:~# kubectl get -f startup.yml
NAME READY STATUS RESTARTS AGE
startprobe 0/1 Running 0 7s
root@k8s-master:~# kubectl describe -f startup.yml
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 52s default-scheduler Successfully assigned default/startprobe to k8s-worker1
Normal Pulled 22s (x2 over 52s) kubelet Container image "httpd:2.2" already present on machine
Normal Created 22s (x2 over 52s) kubelet Created container: httpd
Normal Started 22s (x2 over 52s) kubelet Started container httpd
Normal Killing 22s kubelet Container httpd failed startup probe, will be restarted
Warning Unhealthy 2s (x5 over 42s) kubelet Startup probe failed: Get "http://172.16.194.71:800/": dial tcp 172.16.194.71:800: connect: connection refused
# 可以发现由于故意写成了800端口,检测失败,容器一直无法就绪
root@k8s-master:~# kubectl delete -f startup.yml12.5 探针检测顺序与优先级
在 Kubernetes 中,startupProbe、livenessProbe 和 readinessProbe是用于监控和管理容器健康状况的探针,每种探针在容器生命周期中的不同阶段发挥不同的作用。以下是这三种探针的检测顺序和优先级:
12.5.1 startupProbe
检测顺序:startupProbe是在容器启动时首先执行的探针。它用于判断应用是否已成功启动,并且只在启动期间运行。
优先级:如果配置了 startupProbe,Kubernetes会忽略 livenessProbe和readinessProbe直到 startupProbe成功。startupProbe成功
后,livenessProbe和 readinessProbe才会开始运行。
目的:用于处理启动时间较长的应用程序,确保应用在完全启动之前不会因 livenessProbe 的失败而被重启。
12.5.2 livenessProbe
检测顺序:在 startupProbe成功之后,livenessProbe 开始执行。它定期检查容器是否处于健康状态。
优先级:如果配置了 startupProbe,livenessProbe只有在startupProbe成功之后才开始运行。如果未配置 startupProbe,
livenessProbe在容器启动后立即开始运行。
目的:用于检测容器是否仍然处于健康状态。如果 livenessProbe失败,Kubernetes 会重启该容器。
12.5.3 readinessProbe
检测顺序:在 startupProbe成readinessProbe开始执行。它定期检查容器是否已准备好接收流量。
优先级:如果配置了startupProbe,readinessProbe只有在 startupProbe成功之后才开始运行。如果未配置 startupProbe,
readinessProbe在容器启动后立即开始运行。
目的:用于判断容器是否可以接收请求。如果 readinessProbe 失败,容器将从服务的端点列表中移除,不再接收新的流量。
12.5.4 总结
顺序:startupProbe-> livenessProbe-> readinessProbe
优先级:
startupProbe优先于其他两个探针。如果配置了 startupProbe,必须先通过 startupProbe检测,livenessProbe和 readinessProbe才会启动。
livenessProbe和readinessProbe在startupProbe成功后同时开始运行,没有严格的优先级区分,但它们的作用不同,livenessProbe用于重启失败的容器,readinessProbe 用于控制流量。
12.6 优雅关闭
从 Kubernetes 1.22 开始,terminationGracePeriodSeconds 特性被开启,在杀死容器时,Pod停止获得新的流量。但在Pod中运行的容器不会受到影响。直到超时发生。可以在Pod级别或者容器下具体的探针级别设定,探针会优先和覆盖Pod级别
下面的例子中,容器将在收到结束需求是沉睡2分钟来代表业务的正常关闭,然后整个pod最多等待200秒,超过200秒,就会强制删除
cat > grace.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: httpgrace
spec:
terminationGracePeriodSeconds: 200
containers:
- name: httpd
image: httpd:2.2
imagePullPolicy: IfNotPresent
ports:
- name: webport
protocol: TCP
containerPort: 80
lifecycle:
preStop:
exec:
command: ["/bin/sh","-c","sleep 2m"]
restartPolicy: OnFailure
EOFroot@k8s-master:~# kubectl create -f grace.yml
root@k8s-master:~# kubectl get -f grace.yml
NAME READY STATUS RESTARTS AGE
httpgrace 1/1 Running 0 9s
root@k8s-master:~# kubectl delete pod httpgrace &
[1] 34690
root@k8s-master:~# pod "httpgrace" deleted
root@k8s-master:~# jobs
[1]+ Running kubectl delete pod httpgrace &
# Terminating表示终结中
root@k8s-master:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
httpgrace 1/1 Terminating 0 2m21s
root@k8s-master:~# kubectl describe pod httpgrace
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m51s default-scheduler Successfully assigned default/httpgrace to k8s-worker1
Normal Pulled 2m50s kubelet Container image "httpd:2.2" already present on machine
Normal Created 2m50s kubelet Created container: httpd
Normal Started 2m50s kubelet Started container httpd
Normal Killing 81s kubelet Stopping container httpd
root@k8s-master:~# kubectl get pod
No resources found in default namespace.13 Kubernetes持久存储
Container 中的文件在磁盘上是临时存放的,这给 Container 中运行的较重要的应用 程序带来一些问题:
1.当容器崩溃时文件丢失。kubelet 会重新启动容器, 但容器会以干净的状态重启
2.会在同一 Pod中运行多个容器并共享文件时出现
Kubernetes 卷(Volume) 这一抽象概念能够解决这两个问题
13.1 数据卷
Kubernetes 支持很多类型的卷
Pod 可以同时使用任意数目的卷类型
临时卷类型的生命周期与 Pod 相同,但持久卷可以比 Pod 的存活期长
当 Pod 不再存在时,Kubernetes 也会销毁临时卷;不过 Kubernetes 不会销毁 持久卷。对于给定 Pod 中任何类型的卷,在容器重启期间数据都不会丢失。
使用卷时, 在 .spec.volumes 字段中设置为 Pod 提供的卷,并在 .spec.containers[*].volumeMounts 字段中声明卷在容器中的挂载位置
13.2 配置存储卷
13.2.1 emptyDir
当 Pod 分派到某个 Node 上时,emptyDir 卷会被创建,并且Pod 在该节点上运行期间,卷一直存在。 就像其名称表示的那样,卷最初是空的。
尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会被永久删除。
容器崩溃并不会导致 Pod 被从节点上移除,因此容器崩溃期间 emptyDir 卷中的数据是安全的
cat > emptydir.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: emptydir
spec:
containers:
- image: httpd:2.4
imagePullPolicy: IfNotPresent
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 2G
EOFsizeLimit的单位是M,那就是以1000为进制,如果是Mi就是1024进制
root@k8s-master:~# kubectl create -f emptydir.yml
pod/emptydir created
root@k8s-master:~# kubectl get -f emptydir.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
emptydir 1/1 Running 0 2m51s 172.16.194.74 k8s-worker1 <none> <none>
# 根据上面的提示,在指定的机器上完成这个步骤
root@k8s-worker1:~# crictl ps | grep -i test-container
0bc0e8e536435 httpd@sha256:f84fe51ff5d35124e024f51215b443b16c939b24eae747025a515200e71c7d07 2 minutes ago Running test-container 0 865537d0e7a95 emptydir default
root@k8s-worker1:~# crictl inspect 0bc0e8e536435 | grep cache
"containerPath": "/cache",
"hostPath": "/var/lib/kubelet/pods/87730463-f04a-402b-9275-b58a18295ce6/volumes/kubernetes.io~empty-dir/cache-volume",
// 可以看到数据卷被创建到了:
/var/lib/kubelet/pods/87730463-f04a-402b-9275-b58a18295ce6/volumes/kubernetes.io~empty-dir/cache-volume
root@k8s-master:~# kubectl describe pod emptydir
Name: emptydir
......
Volumes:
cache-volume:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit: 2G
......
root@k8s-master:~# kubectl delete -f emptydir.yml
pod "emptydir" deleted13.2.2 HostPath
hostPath 卷能将主机节点文件系统上的文件或目录挂载到Pod 中,但要注意的是要尽可能避免使用这个类型的卷,会限制pod的迁移性
挂载了一个目录到容器中,并通过nginx对外展示其中的index.html:
cat > hostpath.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: hostpathtest
spec:
containers:
- image: nginx:1.29.0
imagePullPolicy: IfNotPresent
name: hostpathpod
ports:
- name: web
containerPort: 80
volumeMounts:
- mountPath: /usr/share/nginx/html
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /data
type: DirectoryOrCreate
EOF除了必需的path属性之外,用户可以选择性的为hostPath卷指定type,支持的type值如下表格:
| 取值 | 行为 |
|---|---|
| 空字符串(默认)用于向后兼容,这意味着在安装hostPath卷之前不会执行任何检查 | |
| DirectoryOrCreate | 如果在给定路径上什么都不存在,将根据需要创建空目录,权限设置为0755,具有与kubelet相同的组和属主信息 |
| Directory | 在给定路径上必须设置存在的目录 |
| FileOrCreate | 如果在给定路径上什么都不存在,将根据需要创建空文件,权限设置为0644,具有与kubelet相同的组和所有权 |
| File | 在给定路径上必须设置存在的文件 |
| Socket | 在给定路径上必须设置存在的UNIX套接字 |
| CharDevice | 在给定路径上必须设置存在的字符设备 |
| BlockDevice | 在给定路径上必须设置存在的块设备 |
root@k8s-master:~# kubectl create -f hostpath.yml
pod/hostpathtest created
root@k8s-master:~# kubectl get -f hostpath.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
hostpathtest 1/1 Running 0 13s 172.16.194.76 k8s-worker1 <none> <none>
// 根据提示,在work1上完成以下步骤
root@k8s-worker1:~# echo hostwrite > /data/index.html
root@k8s-worker1:~# curl http://172.16.194.76
hostwrite
root@k8s-master:~# kubectl delete -f hostpath.yml
pod "hostpathtest" deleted13.2.3 持久卷概述
持久卷(PersistentVolume,PV)是集群中的一块存储,可以由管理员事先供应,也可以使用存储类(Storage Class)来动态供应
持久卷是集群资源,就像节点也是集群资源一样。PV 持久卷和普通的Volume一样,也是使用卷插件来实现的,只是它们拥有独立于任何使用 PV 的 Pod 的生命周期
持久卷申请(PersistentVolumeClaim,PVC)表达的是用户对存储的请求。概念上与 Pod 类似,Pod 会耗用节点资源,而 PVC 申领会耗用 PV 资源
构建简易NFS服务器:
在master上模拟一个nfs服务器,将本地的/nfsshare共享出来给所有人使用:
root@k8s-master:~# apt install nfs-kernel-server -y // 安装nfs服务器
root@k8s-master:~# mkdir /nfsshare // 创建文件夹
root@k8s-master:~# chmod 777 /nfsshare -R
root@k8s-master:~# echo /nfsshare *(rw) >> /etc/exports // 把文件夹共享出去
root@k8s-master:~# systemctl enable nfs-server --now // 启动服务
root@k8s-master:~# exportfs -rav // 查看共享情况
exportfs: /etc/exports [1]: Neither 'subtree_check' or 'no_subtree_check' specified for export "*:/nfsshare".
Assuming default behaviour ('no_subtree_check').
NOTE: this default has changed since nfs-utils version 1.0.x
exporting *:/nfsshare
root@k8s-master:~# showmount -e localhost
Export list for localhost:
/nfsshare *13.2.4 PV
创建一个名为nfspv、大小为5Gi卷,并以ReadWriteOnce的方式申明,且策略为Recycle
cat > pv.yml <<EOF
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfspv
labels:
pvname: nfspv
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle
storageClassName: slow
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfsshare
server: 192.168.8.3
EOFKubernetes 支持两种卷模式(volumeModes):Filesystem(文件系统) 和 Block(块)
volumeMode 属性设置为 Filesystem 的卷会被 Pod 挂载(Mount) 到某个目录。 如果卷的存储来自某块设备而该设备目前为空,Kuberneretes 会在第一次挂载卷之前在设备上创建文件系统。
| 访问模式 | 描述 |
|---|---|
| ReadWriteOnce | 卷可以被一个节点以读写方式挂载, ReadWriteOnce访问模式也允许运行在同一节点上的多个 Pod 访问卷 |
| ReadOnlyMany | 卷可以被多个节点以只读方式挂载 |
| ReadWriteMany | 卷可以被多个节点以读写方式挂载 |
| ReadWriteOncePod | 卷可以被单个 Pod 以读写方式挂载,如果想确保整个集群中只有一个 Pod 可以读取或写入该 PVC, 请使用ReadWriteOncePod 访问模式 |
在创建pv前,需要确保在3个节点上都安装了nfs客户端:
root@k8s-master:~# apt install nfs-common -y
root@k8s-worker1:~# apt install nfs-common -y
root@k8s-worker2:~# apt install nfs-common -y创建pv:
root@k8s-master:~# kubectl create -f pv.yml
persistentvolume/nfspv created
root@k8s-master:~# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
nfspv 5Gi RWO Recycle Available slow <unset> 13s
root@k8s-master:~# kubectl describe pv nfspv
Name: nfspv
Labels: pvname=nfspv
Annotations: pv.kubernetes.io/bound-by-controller: yes
Finalizers: [kubernetes.io/pv-protection]
StorageClass: slow
Status: Bound
Claim: default/myclaim
Reclaim Policy: Recycle
Access Modes: RWO
VolumeMode: Filesystem
Capacity: 5Gi
Node Affinity: <none>
Message:
Source:
Type: NFS (an NFS mount that lasts the lifetime of a pod)
Server: 192.168.8.3
Path: /nfsshare
ReadOnly: false
Events: <none>PV回收策略与状态:
| 回收策略 | 描述 |
|---|---|
| Retain | 手动回收 |
| Recycle | 基本擦除 (rm -rf /thevolume/*) |
| Delete | 诸如 AWS EBS、GCE PD、Azure Disk 或 OpenStack Cinder 卷这类关联存储资产也被删除 目前,仅NFS和HostPath支持回收(Recycle), AWS EBS、GCE PD、Azure Disk 和 Cinder 卷都支持删除(Delete) |
每个卷会处于以下阶段(Phase)之一:
| PV卷状态 | 描述 |
|---|---|
| Available(可用) | 卷是一个空闲资源,尚未绑定到任何申领; |
| Bound(已绑定) | 该卷已经绑定到某申领; |
| Released(已释放) | 所绑定的申领已被删除,但是资源尚未被集群回收; |
| Failed(失败) | 卷的自动回收操作失败。 |
13.2.5 PVC
cat > pvc.yml <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: myclaim
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 1Gi
storageClassName: slow
selector:
matchLabels:
pvname: "nfspv"
EOF| 参数 | 说明 | 描述 |
|---|---|---|
| accessModes | 访问模式 | 申领在请求具有特定访问模式的存储时,使用与卷相同的访问模式约定 |
| volumeMode | 卷模式 | 申领使用与卷相同的约定来表明是将卷作为文件系统还是块设备来使用 |
| resources | 资源 | 申领和 Pod 一样,也可以请求特定数量的资源 |
| selector | 选择算符 | 申领可以设置标签选择算符来进一步过滤卷集合,只有标签与选择算符相匹配的卷能够绑定到申领上。 |
selector(选择算符)参数选择:
1.matchLabels - 卷必须包含带有此值的标签
2.matchExpressions - 通过设定键(key)、值列表和操作符(operator) 来构造的需求,合法的操作符有 In、NotIn、Exists 和 DoesNotExist
来自 matchLabels 和 matchExpressions 的所有需求都按逻辑与的方式组合在一起,这些需求都必须被满足才被视为匹配。
root@k8s-master:~# kubectl create -f pvc.yml
persistentvolumeclaim/myclaim created
root@k8s-master:~# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
nfspv 5Gi RWO Recycle Bound default/myclaim slow <unset> 24h
root@k8s-master:~# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
myclaim Bound nfspv 5Gi RWO slow <unset> 8s
root@k8s-master:~# kubectl describe pvc myclaim
Name: myclaim
Namespace: default
StorageClass: slow
Status: Bound
Volume: nfspv
Labels: <none>
Annotations: pv.kubernetes.io/bind-completed: yes
pv.kubernetes.io/bound-by-controller: yes
Finalizers: [kubernetes.io/pvc-protection]
Capacity: 5Gi
Access Modes: RWO
VolumeMode: Filesystem
Used By: <none>
Events: <none>13.2.6 使用PVC
创建一个pod并尝试使用PVC
apt install nfs-common -y
cat > pvcuse.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: myfrontend
image: httpd:2.4
imagePullPolicy: IfNotPresent
ports:
- name: web
containerPort: 80
volumeMounts:
- mountPath: "/usr/local/apache2/htdocs"
name: mypd
volumes:
- name: mypd
persistentVolumeClaim:
claimName: myclaim
EOFroot@k8s-master:~# kubectl create -f pvcuse.yml
pod/mypod created
root@k8s-master:~# kubectl get -f pvcuse.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mypod 1/1 Running 0 15s 172.16.194.77 k8s-worker1 <none> <none>
// 在NFS服务器上(192.168.8.3)创建出index.html网页
root@k8s-master:~# echo pvtest > /nfsshare/index.html
root@k8s-master:~# kubectl get pod -o wide
// 这里要看一下调度到那个机器,被调度到的机器必须执行apt install nfs-common -y
root@k8s-master:~# curl http://172.16.194.77
pvtest
root@k8s-master:~# kubectl delete -f pvcuse.yml
pod "mypod" deleted13.3 配置存储类
StorageClass 是 Kubernetes 中用于动态供应持久化存储卷(PV)的核心资源对象,其核心作用包括:
**自动化PV创建:**根据 PersistentVolumeClaim(PVC)的请求,自动触发存储插件(Provisioner)生成匹配的 PV,无需管理员手动预配置
**存储资源抽象:**定义存储的类型(如 SSD/HDD)、性能参数(如IOPS)、回收策略等属性,为不同应用提供差异化的存储服务
**策略分级管理:**通过命名(如 gold、silver)区分存储等级,使用户能按需选择存储类型(例如高性能存储 vs 低成本存储)
13.3.1 StorageClass 的必要性
在大规模 Kubernetes 集群中,StorageClass 的引入解决了关键问题:动态资源分配
传统痛点:手动创建PV需提前预估容量,易导致资源浪费(如分配过大)或不足(如突发需求无法满足)
动态优势:根据PVC实时请求自动创建PV,按需分配存储资源,提升集群利用率
13.3.2 存储类特性
| 特性 | 说明 | 典型配置实例 |
|---|---|---|
| 动态供应 | 按需创建PV,避免预分配资源浪费 | provisioner: kubernetes.io/aws-ebs |
| 存储策略定制 | 定义存储类型(SSD/HDD)、访问模式(ReadWriteOnce)、压缩算法等 | parameters: type=gp3, compression=none |
| 资源回收策略 | 控制PV释放后的处理方式(Delete自动删除/Retain保留数据) | reclaimPolicy: Delete |
| 卷扩展支持 | 允许在线扩容PV容量(需存储后端支持) | allowVolumeExpansion: true |
| 绑定模式 | 控制PV绑定时机(Immediate立即绑定/WaiForFirstConsumer延迟至Pod调度时绑定) | volumeBindingMode: waitForFirstConsumer |
| 存储类优先级 | 定义多个StorageClass的优先级(通过priorityClassName实现资源调度策略) | priorityClassName: high-performance |
| 注解与标签 | 为StorageClass添加元数据,用于监控或自动化运维 | annotations: {“storage-type”: “ssd”} |
| 允许卷快照 | 支持通过CSI插件创建卷快照(需存储后端支持快照功能) | volumeSnapshotClassName: csi-snapshot |
13.3.3 NFS外部供应
1.下载外部供应代码:
root@k8s-master:~# git clone https://gitee.com/cnlxh/nfs-subdir-external-provisioner.git
root@k8s-master:~# cd nfs-subdir-external-provisioner
root@k8s-master:~/nfs-subdir-external-provisioner# ls
CHANGELOG.md cmd deploy Dockerfile.multiarch LICENSE OWNERS_ALIASES release-tools
charts code-of-conduct.md docker go.mod Makefile README.md SECURITY_CONTACTS
cloudbuild.yaml CONTRIBUTING.md Dockerfile go.sum OWNERS RELEASE.md vendor
本次采用default命名空间,如果需要别的命名空间,请执行以下替换:
root@k8s-master:~/nfs-subdir-external-provisioner# NS=$(kubectl config get-contexts|grep -e "^\*" |awk '{print $5}')
root@k8s-master:~/nfs-subdir-external-provisioner# NAMESPACE=${NS:-default}
root@k8s-master:~/nfs-subdir-external-provisioner# sed -i'' "s/namespace:.*/namespace: $NAMESPACE/g" ./deploy/rbac.yaml ./deploy/deployment.yaml
// 三条命令如下:
NS=$(kubectl config get-contexts|grep -e "^\*" |awk '{print $5}')
NAMESPACE=${NS:-default}
sed -i'' "s/namespace:.*/namespace: $NAMESPACE/g" ./deploy/rbac.yaml ./deploy/deployment.yaml 如果集群采用了RBAC,请授权一下:
root@k8s-master:~/nfs-subdir-external-provisioner# kubectl create -f deploy/rbac.yaml
serviceaccount/nfs-client-provisioner created
clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner created
role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created2.配置NFS外部供应:
根据实际情况在deploy/deployment中修改镜像、名称、nfs地址和挂载:
root@k8s-master:~/nfs-subdir-external-provisioner# kubectl create -f deploy/deployment.yaml
deployment.apps/nfs-client-provisioner created13.3.4 部署存储类
要支持nfs挂载,所有节点都需要安装nfs-common安装包
apt install nfs-common -ycat > storageclassdeploy.yml <<'EOF'
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: cnlxh/nfs-storage
allowVolumeExpansion: true
volumeBindingMode: WaitForFirstConsumer
parameters:
pathPattern: "${.PVC.namespace}-${.PVC.name}"
onDelete: delete
EOF指定存储卷的绑定模式为 WaitForFirstConsumer,这意味着 PV 的创建和绑定会在 PVC 被 Pod 引用时才进行,而不是在 PVC 创建时立即绑定。这种模式特别适用于需要考虑 Pod 调度约束的场景,例如确保 PV 创建在与 Pod 同一节点上(对于本地存储)或同一可用区(对于云存储)
root@k8s-master:~# kubectl create -f storageclassdeploy.yml
storageclass.storage.k8s.io/nfs-client created13.3.5 标记默认存储类
root@k8s-master:~# kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-client cnlxh/nfs-storage Delete WaitForFirstConsumer true 80s
root@k8s-master:~# kubectl patch storageclass nfs-client -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
storageclass.storage.k8s.io/nfs-client patched13.3.6 使用存储类
只需要在pvc.spec中执行storageClassName: nfs-client就可以了
root@k8s-master:~# cd nfs-subdir-external-provisioner/
root@k8s-master:~/nfs-subdir-external-provisioner# kubectl create -f deploy/test-claim.yaml -f deploy/test-pod.yaml
persistentvolumeclaim/test-claim created
pod/test-pod created打开test-pod.yaml就会发现,它向我们的pvc也就是nfs服务器写入了名为SUCCESS文件,在nfs服务器上执行:
root@k8s-master:~/nfs-subdir-external-provisioner/deploy# ls /nfsshare/default-test-claim/
SUCCESS删除pod和pvc,会删除我们的资源,测试一下,执行后,会删除pod、pvc、pv,再去nfs服务器查看,数据就没了
root@k8s-master:~/nfs-subdir-external-provisioner# kubectl delete -f deploy/test-pod.yaml -f deploy/test-claim.yaml
pod "test-pod" deleted
persistentvolumeclaim "test-claim" deleted14 Pod调度
14.1 nodeSelector
需求:
将Pod调度到具有SSD磁盘的节点运行步骤:
1.给节点打SSD标签
2.创建Pod时带上nodeSelector条件
3.检查Pod调度结果
给k8s-worker2节点打一个标签name=lixiaohui
root@k8s-master:~# kubectl label nodes k8s-worker2 name=lixiaohui
node/k8s-worker2 labeled
root@k8s-master:~# kubectl describe nodes k8s-worker2
Name: k8s-worker2
Roles: worker
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
disktype=ssd
kubernetes.io/arch=amd64
kubernetes.io/hostname=k8s-worker2
kubernetes.io/os=linux
name=lixiaohui
node-role.kubernetes.io/worker=
......如果需要删除标签可以用:
root@k8s-master:~# kubectl label nodes k8s-worker2 name-将pod仅调度到具有name=lixiaohui标签的节点上:
cat > assignpod.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: cnlxhtest
spec:
containers:
- name: nginx
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
nodeSelector:
name: lixiaohui
EOFroot@k8s-master:~# kubectl create -f assignpod.yml
pod/cnlxhtest created
root@k8s-master:~# kubectl get pod cnlxhtest -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cnlxhtest 1/1 Running 0 3m20s 172.16.126.9 k8s-worker2 <none> <none>
root@k8s-master:~# kubectl delete -f assignpod.yml14.2 nodeName
将Pod仅调度到具有特定名称的节点上,例如仅调度到k8s-worker1上
cat > nodename.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: lxhnodename
spec:
containers:
- name: nginx
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
nodeName:
k8s-worker1
EOFroot@k8s-master:~# kubectl create -f nodename.yml
root@k8s-master:~# kubectl get pod lxhnodename -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
lxhnodename 1/1 Running 0 108s 172.16.194.82 k8s-worker1 <none> <none>
root@k8s-master:~# kubectl delete -f nodename.yml14.3 节点亲和性
节点亲和性概念上类似于 nodeSelector,可以根据节点上的标签来约束 Pod 可以调度到哪些节点。
目前有两种类型的节点亲和性,分别为:
1.requiredDuringSchedulingIgnoredDuringExecution
2.preferredDuringSchedulingIgnoredDuringExecution
以上两种亲和性可理解为“硬需求”和“软需求”,前者指定了将 Pod 调度到一个节点上必须满足的规则,后者指定调度器将尝试执行但不能保证的偏好

affinity(亲和性):
本实验展示在 Kubernetes 集群中,如何使用节点亲和性把 Kubernetes Pod 分配到特定节点
首先需要给节点打上一个合适的标签:
root@k8s-master:~# kubectl label nodes k8s-worker2 disktype=ssd
node/k8s-worker2 labeled查看节点是否具有标签:
root@k8s-master:~# kubectl get nodes --show-labels | grep -i disktype
k8s-worker2 Ready worker 101d v1.32.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-worker2,kubernetes.io/os=linux,name=lixiaohui,node-role.kubernetes.io/worker=
删除k8s-worker2上的污点,避免干扰:
root@k8s-master:~# kubectl taint node k8s-worker2 disktype-
node/k8s-worker2 untainted强制调度到具有特定标签的节点上:
cat > required.yml <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: require
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
EOF可以看到的确调度到了k8s-worker2:
root@k8s-master:~# kubectl create -f required.yml
pod/require created
root@k8s-master:~# kubectl get -f required.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
require 1/1 Running 0 48s 172.16.126.11 k8s-worker2 <none> <none>优先但不强制的调度:
cat > preferred.yml <<'EOF'
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
EOF依旧被调度到k8s-worker2上:
root@k8s-master:~# kubectl create -f preferred.yml
pod/nginx created
root@k8s-master:~# kubectl get -f preferred.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 19s 172.16.126.12 k8s-worker2 <none> <none>14.4 污点和容忍度
节点亲和性是 Pod 的一种属性,它使 Pod 被吸引到一类特定的节点 ,污点(Taint)则相反——它使节点能够排斥一类特定的 Pod
容忍度(Toleration)是应用于 Pod 上的,允许(但并不要求)Pod 调度到带有与之匹配的污点的节点上。
污点和容忍度(Toleration)相互配合,可以用来避免 Pod 被分配到不合适的节点上。 每个节点上都可以应用一个或多个污点,这表示对于那些不能容忍这些污点的 Pod,是不会被该节点接受的。
一旦某个节点打上了污点,Pod如果不容忍此污点,就不会被调度过来
[root@host1 ~]# taint nodes node1 disktype=ssd:NoSchedule
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "disktype"
operator: "Exists"
effect: "NoSchedule"operator 的默认值是 Equal
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:如果 operator 是 Exists (此时容忍度不能指定 value),或者如果 operator 是 Equal ,则它们的 value 应该相等
如果一个容忍度的 key 为空且 operator 为 Exists, 表示这个容忍度与任意的 key 、value 和 effect 都匹配,即这个容忍度能容忍任意 taint
如果 effect 为空,则可以与所有键名 key的效果相匹配
effect使用的值:
1.NoSchedule,不允许调度
2.PreferNoSchedule,系统会尽量避免将 Pod 调度到存在其不能容忍污点的节点上, 但这不是强制的
3.NoExecute,不会将新Pod 分配到该节点, 或者将 Pod 从该节点驱逐
如果 Pod 存在一个 effect 值为 NoExecute 的容忍度指定了可选属性 tolerationSeconds 的值,则表示在给节点添加了上述污点之后, Pod 还能继续在节点上运行的时间
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600tolerations(容忍度):
master节点默认不参与调度的原因就是因为其上有taint(污点),而toleration就是容忍度
root@k8s-master:~# kubectl describe nodes k8s-master | grep -i taint
Taints: node-role.kubernetes.io/control-plane:NoSchedule添加一个磁盘类型为hdd就不调度的污点:
root@k8s-master:~# kubectl taint node k8s-worker2 disktype=hdd:NoSchedule
node/k8s-worker2 tainted如需删除以上污点,可用以下命令实现:
root@k8s-master:~# kubectl taint node k8s-worker2 disktype-创建一个可以容忍具有master taint的pod:
cat > tolerations.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: tolerations
spec:
containers:
- name: nginx
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
EOFroot@k8s-master:~# kubectl create -f tolerations.yml
pod/tolerations created
root@k8s-master:~# kubectl get pod tolerations -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tolerations 1/1 Running 0 15s 172.16.194.83 k8s-worker1 <none> <none>
root@k8s-master:~# kubectl delete -f tolerations.yml上述示例表明:并没有调度到k8s-master上,由此得出一个结果,容忍不代表必须,如果必须要调度到k8s-master,需要用以下例子:
cat > mustassign.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: tolerationsmust
spec:
containers:
- name: nginx
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
tolerations:
- key: "node-role.kubernetes.io/control-plane"
operator: "Exists"
effect: "NoSchedule"
nodeSelector:
node-role.kubernetes.io/control-plane: ""
EOFroot@k8s-master:~# kubectl create -f mustassign.yml
pod/tolerationsmust created
root@k8s-master:~# kubectl get -f mustassign.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tolerationsmust 1/1 Running 0 8s 172.16.235.229 k8s-master <none> <none>
root@k8s-master:~# kubectl delete -f mustassign.yml14.5 PriorityClass
PriorityClass 是 Kubernetes 中用于 定义 Pod 调度优先级 的集群级资源对象,其核心作用包括:
优先级分层:通过数值(0-10亿)划分 Pod 优先级,数值越大优先级越高
抢占机制:高优先级 Pod 在资源不足时可触发低优先级 Pod 的驱逐(Preemption)
资源分配控制:确保关键业务(如数据库、监控组件)优先获取计算资源
本实验主要是学习如何查询和创建PriorityClass,具有更高数字的PriorityClass在资源紧张时会优先获得资源,具有更低数字的PriorityClass在资源紧张时会被驱逐
在 Kubernetes 中,PriorityClass 的优先级范围是一个整数值,用于定义 Pod 的相对优先级。优先级值越高,表示 Pod 的优先级越高。Kubernetes 使用这些优先级值来决定在资源紧张时哪些 Pod 可以被抢占,以及在调度时哪些 Pod 应该优先调度。
优先级范围的意义:
1.调度优先级:
当多个 Pod 等待调度时,调度器会优先调度优先级更高的 Pod
如果资源不足,调度器会尝试抢占优先级较低的 Pod,以满足高优先级 Pod 的资源需求
2.抢占行为:
如果高优先级的 Pod 无法找到足够的资源,调度器会尝试抢占优先级较低的 Pod
被抢占的 Pod 会被终止,并重新调度到其他节点(如果资源允许)。
PriorityClass 还有两个可选字段:
globalDefault 字段表示这个 PriorityClass 的值应该用于没有 priorityClassName 的 Pod。 系统中只能存在一个 globalDefault 设置为 true 的 PriorityClass。 如果不存在设置了 globalDefault 的 PriorityClass, 则没有 priorityClassName 的 Pod 的优先级为零
description 字段是一个任意字符串。 它用来告诉集群用户何时应该使用此 PriorityClass
查询系统中现有的PriorityClass:
root@k8s-master:~# kubectl get priorityclasses
NAME VALUE GLOBAL-DEFAULT AGE PREEMPTIONPOLICY
system-cluster-critical 2000000000 false 101d PreemptLowerPriority
system-node-critical 2000001000 false 101d PreemptLowerPrioritycat > pc.yml <<-'EOF'
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "此优先级类应仅用于 XYZ 服务 Pod。"
EOF创建并再次查看:
root@k8s-master:~# kubectl apply -f pc.yml
priorityclass.scheduling.k8s.io/high-priority created
root@k8s-master:~# kubectl get priorityclasses.scheduling.k8s.io
NAME VALUE GLOBAL-DEFAULT AGE PREEMPTIONPOLICY
high-priority 1000000 false 63s PreemptLowerPriority
system-cluster-critical 2000000000 false 101d PreemptLowerPriority
system-node-critical 2000001000 false 101d PreemptLowerPriority创建后可以将其应用到pod或deployment上其作用:
cat > deployment-pc.yml <<-'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: high-priority-test
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
priorityClassName: high-priority
containers:
- name: nginx
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
EOF创建此deployment,并观察deployment产生的pod是否具有特定的值:
root@k8s-master:~# kubectl apply -f deployment-pc.yml
deployment.apps/high-priority-test created
root@k8s-master:~# kubectl get deployments.apps high-priority-test -o yaml | grep priorityClassName:
priorityClassName: high-priority
root@k8s-master:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
cnlxhtest 1/1 Running 0 67m
emptydir 1/1 Running 1 (17h ago) 2d21h
high-priority-test-7dc84c65ff-2wx7q 1/1 Running 0 49s
high-priority-test-7dc84c65ff-cltdl 1/1 Running 0 49s
high-priority-test-7dc84c65ff-hmplw 1/1 Running 0 49s
lxhnodename 1/1 Running 0 56m
nfs-client-provisioner-5998cfc9bc-zh2fv 1/1 Running 1 (17h ago) 43h
nginx 1/1 Running 0 14m
require 1/1 Running 0 17m
tolerations 1/1 Running 0 31m
tolerationsmust 1/1 Running 0 28m
root@k8s-master:~# kubectl get pod high-priority-test-7dc84c65ff-2wx7q -o yaml | grep priorityClassName:
priorityClassName: high-priority15 ConfigMap和Secret
15.1 ConfigMap
假设正在开发一个应用,它可以在你自己的电脑上(用于开发)和在云上 (用于实际流量) 运行。 代码里有一段是用于查看环境变量 DATABASE_HOST,在本地运行时, 将这个 变量设置为 localhost,在云上,将其设置为引用 Kubernetes 集群中的 公开数据库组件的服务。
这可以获取在云中运行的容器镜像,并且如果有需要的话,在本地调试完全相同的代码。
ConfigMap 在设计上不是用来保存大量数据的,在 ConfigMap 中保存的数据不可超过 1 MiB。如果需要保存超出此尺寸限制的数据,可能希望考虑挂载存储卷 或者使用独立的数据库或者文件服务。

15.1.1 YAML文件创建
在Data节点创建了一些键值:
cat > cmyaml.yml <<EOF
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
player_initial_lives: "3"
ui_properties_file_name: "lixiaohui"
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
EOFroot@k8s-master:~# kubectl create -f cmyaml.yml
configmap/game-demo created
root@k8s-master:~# kubectl get configmaps
NAME DATA AGE
game-demo 3 16s
kube-root-ca.crt 1 102d
root@k8s-master:~# kubectl describe configmaps game-demo
Name: game-demo
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
player_initial_lives:
----
3
ui_properties_file_name:
----
lixiaohui
game.properties:
----
enemy.types=aliens,monsters
player.maximum-lives=5
BinaryData
====
Events: <none>15.1.2 命令行创建
创建了一个名为lixiaohui的键值:
root@k8s-master:~# kubectl create configmap lixiaohui --from-literal=username=lixiaohui --from-literal=age=18
configmap/lixiaohui created
root@k8s-master:~# kubectl describe configmaps lixiaohui
Name: lixiaohui
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
age:
----
18
username:
----
lixiaohui
BinaryData
====
Events: <none>创建了一个index.html文件,然后用–from-file来引用:
root@k8s-master:~# echo hello world > index.html
root@k8s-master:~# kubectl create configmap indexcontent --from-file=index.html
configmap/indexcontent created
root@k8s-master:~# kubectl describe configmaps indexcontent
Name: indexcontent
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
index.html:
----
hello world
BinaryData
====
Events: <none>15.1.3 Volume 挂载ConfigMap
创建一个Pod,其挂载的内容,将来自于我们的configmap:
cat > cmvolume.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: configmapvolume
labels:
app: configmaptest
spec:
containers:
- name: test
image: httpd:2.4
imagePullPolicy: IfNotPresent
volumeMounts:
- name: index
mountPath: /usr/local/apache2/htdocs
volumes:
- name: index
configMap:
name: indexcontent
EOFroot@k8s-master:~# kubectl create -f cmvolume.yml
pod/configmapvolume created
root@k8s-master:~# kubectl get -f cmvolume.yml -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
configmapvolume 1/1 Running 0 9s 172.16.194.86 k8s-worker1 <none> <none>
root@k8s-master:~# curl http://172.16.194.86
hello world
root@k8s-master:~# kubectl delete -f cmvolume.yml15.1.4 环境变量ConfigMap
创建一个名为mysqlpass且包含password=ABCabc123的configmap:
root@k8s-master:~# kubectl create configmap mysqlpass --from-literal=password=ABCabc123
configmap/mysqlpass createdcat > cmenv.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: mysql
spec:
containers:
- name: mysqlname
image: mysql:8.0
imagePullPolicy: IfNotPresent
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
configMapKeyRef:
name: mysqlpass
key: password
EOF用环境变量的方法引用了configmap:
root@k8s-master:~# kubectl create -f cmenv.yml
pod/mysql created
root@k8s-master:~# kubectl get -f cmenv.yml
NAME READY STATUS RESTARTS AGE
mysql 1/1 Running 0 44s
root@k8s-master:~# kubectl exec -it mysql -- mysql -uroot -pABCabc123
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 8
Server version: 8.0.42 MySQL Community Server - GPL
Copyright (c) 2000, 2025, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> exit
Bye用configMap来引用密码是不太靠谱的,通常用于配置文件等明文场景,密文应该使用下一个实验的secret,因为configMap是明文的,见如下示例:
root@k8s-master:~# kubectl describe configmaps mysqlpass
Name: mysqlpass
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
password:
----
ABCabc123
BinaryData
====
Events: <none>
root@k8s-master:~# kubectl delete -f cmenv.yml15.2 Secret
Secret 是一种包含少量敏感信息例如密码、令牌或密钥的对象,这样的信息可能会被放在 Pod 规约中或者镜像中。
使用 Secret 意味着不需要在应用程序代码中包含机密数据。
要使用 Secret,Pod 需要引用 Secret,Pod 可以用三种方式之一来使用 Secret:
1.作为挂载到一个或多个容器上的 卷 中的文件
2.作为容器的环境变量
3.由 kubelet 在为 Pod 拉取镜像时使用
15.2.1 命令行创建
root@k8s-master:~# kubectl create secret generic mysqlpass --from-literal=password=ABCabc123
secret/mysqlpass created
# 查看时,会发现已经加密
root@k8s-master:~# kubectl describe secrets mysqlpass
Name: mysqlpass
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 9 bytes15.2.2 环境变量Secret
使用刚才创建的密码,创建Pod并进行尝试:
cat > stenv.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: mysql-secret
spec:
containers:
- name: mysqlname
image: mysql:5.7
imagePullPolicy: IfNotPresent
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysqlpass
key: password
EOFroot@k8s-master:~# kubectl create -f stenv.yml
pod/mysql-secret created
root@k8s-master:~# kubectl get -f stenv.yml
NAME READY STATUS RESTARTS AGE
mysql-secret 1/1 Running 0 24s
root@k8s-master:~# kubectl exec -it mysql-secret -- mysql -uroot -pABCabc123
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.44 MySQL Community Server (GPL)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> exit
Bye
root@k8s-master:~# kubectl get secrets mysqlpass -o yaml
apiVersion: v1
data:
password: QUJDYWJjMTIz
kind: Secret
metadata:
creationTimestamp: "2025-07-19T11:12:38Z"
name: mysqlpass
namespace: default
resourceVersion: "530239"
uid: da97c0e1-23e3-48e8-b720-3090373b157a
type: Opaque
root@k8s-master:~# echo QUJDYWJjMTIz | base64 -d
ABCabc123root@k8s-master:~#
root@k8s-master:~# kubectl delete -f stenv.yml16 资源配额

16.1 Pod 资源配额
内存申请64Mi,CPU申请100m,上限为内存128Mi,CPU100m
cat > quota.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: frontend
labels:
name: frontend
spec:
containers:
- name: app
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "64Mi"
cpu: "100m"
limits:
memory: "128Mi"
cpu: "100m"
EOFroot@k8s-master:~# kubectl create -f quota.yml
pod/frontend created
root@k8s-master:~# kubectl get -f quota.yml
NAME READY STATUS RESTARTS AGE
frontend 1/1 Running 0 69s
root@k8s-master:~# kubectl describe -f quota.yml | grep -A 5 Limits
Limits:
cpu: 100m
memory: 128Mi
Requests:
cpu: 100m
memory: 64Mi
root@k8s-master:~# kubectl delete -f quota.yml16.2 NameSpace 资源配额
新建namespace:
root@k8s-master:~# kubectl create namespace test
namespace/test created在ResourceQuota中,requests.cpu: “1” 就代表1000m,requests.memory后面,如果只是一个数字,没有Mi等单位时,默认使用的是字节单位
cat > nmquota.yml <<EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: lixiaohuiquota
namespace: test
spec:
hard:
pods: "1"
requests.cpu: "1"
requests.memory: "1"
limits.cpu: "2"
limits.memory: "2Gi"
EOF
root@k8s-master:~# kubectl create -f nmquota.yml
resourcequota/lixiaohuiquota created
root@k8s-master:~# kubectl get -f nmquota.yml
NAME AGE REQUEST LIMIT
lixiaohuiquota 7s pods: 0/1, requests.cpu: 0/1, requests.memory: 0/1 limits.cpu: 0/2, limits.memory: 0/2Gi
root@k8s-master:~# kubectl get resourcequotas -n test
NAME AGE REQUEST LIMIT
lixiaohuiquota 32m pods: 0/1, requests.cpu: 0/1, requests.memory: 0/1 limits.cpu: 0/2, limits.memory: 0/2Gi新建一个Pod尝试申请资源:
cat > nmpod.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: frontend
namespace: test
spec:
containers:
- name: app
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "64Mi"
cpu: "15000m"
limits:
memory: "128Mi"
cpu: "15000m"
EOF由于限制无法申请成功:
root@k8s-master:~# kubectl create -f nmpod.yml
Error from server (Forbidden): error when creating "nmpod.yml": pods "frontend" is forbidden: exceeded quota: lixiaohuiquota, requested: limits.cpu=15,requests.cpu=15,requests.memory=64Mi, used: limits.cpu=0,requests.cpu=0,requests.memory=0, limited: limits.cpu=2,requests.cpu=1,requests.memory=1修改Pod申请资源的参数:
cat > nmpod.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: frontend
namespace: test
spec:
containers:
- name: app
image: nginx:1.26.1
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "1"
cpu: "100m"
limits:
memory: "128Mi"
cpu: "100m"
EOFroot@k8s-master:~# kubectl create -f nmpod.yml
pod/frontend created
root@k8s-master:~# kubectl get resourcequotas -n test
NAME AGE REQUEST LIMIT
lixiaohuiquota 46m pods: 1/1, requests.cpu: 100m/1, requests.memory: 1/1 limits.cpu: 100m/2, limits.memory: 128Mi/2Gi
root@k8s-master:~# kubectl get -f nmpod.yml
NAME READY STATUS RESTARTS AGE
frontend 1/1 Running 0 2m45s
# 修改资源配额
root@k8s-master:~# kubectl edit resourcequotas -n test lixiaohuiquota
resourcequota/lixiaohuiquota edited
root@k8s-master:~# kubectl get resourcequotas -n test
NAME AGE REQUEST LIMIT
lixiaohuiquota 56m pods: 1/2, requests.cpu: 100m/1, requests.memory: 1/200Mi limits.cpu: 100m/2, limits.memory: 128Mi/2Gi17 访问控制
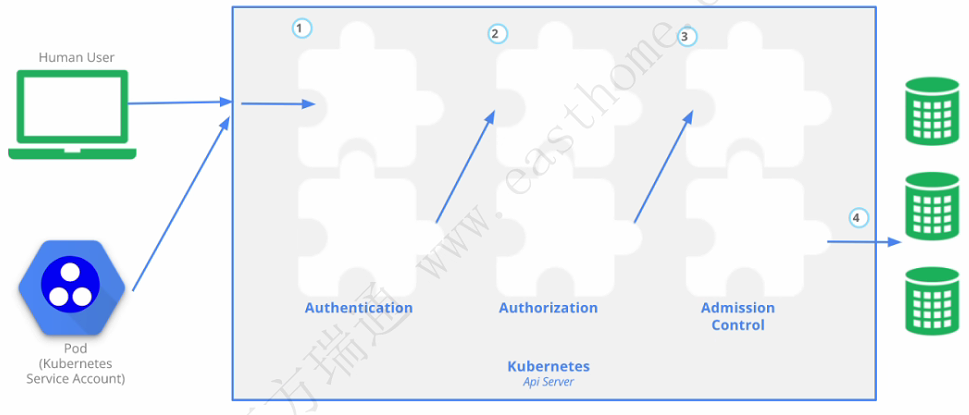
17.1 访问控制的概念和模块
17.1.1 鉴权模块
Node: 一个专用鉴权组件,根据调度到 kubelet 上运行的 Pod 为 kubelet 授予权限
**ABAC:**基于属性的访问控制(用户属性、资源属性、 对象,环境属性等)
**RBAC:**基于角色的访问控制
**Webhook:**基于http回调的访问控制
17.1.2 User、Permission和Role
用户(User)是可以独立访问计算机系统中的数据或者用数据表示的其它资源的主体(Subject)
许可(Permission)就是允许对一个或多个客体(object)执行的操作(action)
角色(Role)代表了一种权利、资格,可由多种许可构成
17.1.3 Kubernetes中的用户和用户组
User Account(用户账号):一般是指由独立于Kubernetes之外的其它服务管理的用户账号, Kubernetes中不存在表示此类用户账号的对象,作用于系统全局,名称必须全局唯一。
Service Account(服务账号):为Pod中的进程调用Kubernetes API设计,通常需要绑定于特定的名称空间,作用仅局限在他们所在的Namespace,他们由API Server创建,或者通过API调用手动创建,附带着一组存储为Secret的用于访问API Server的凭据。
这两类账号都可以隶属于一个或多个用户组,用户组本身没有操作权限,但是附加在组上 的权限可由其内部的所有用户继承,实现高效的授权管理机制。
17.1.4 相关的名词解释
serviceaccount
每个Pod都必须有一个serviceaccount,因为serviceaccount决定了pod对集群内部的权限范围,没有指定时会强制分配default账号
serviceaccount中会关联具体的角色或集群角色,所以,serviceaccount有什么权限要看其关联的角色中有哪些权限
角色
对特定namespace有效
关联上具体的资源,关联上具体的动作,例如,abc角色,对pod拥有delete
集群角色
对特定namespace有效
关联上具体的资源,关联上具体的动作,例如,abc角色,对pod拥有delete
角色绑定
对特定namespace有效
在特定的namespace中,将namespace中的某个角色绑定到某个serviceaccount,也就是说,将角色拥有的权限,分配给serviceaccount
集群角色绑定
对所有namespace有效
将某个集群角色绑定到某个serviceaccount,也就是说,将集群角色拥有的权限,分配给serviceaccount
17.2 UserAccount
创建一个存在于kubernetes组中名为lixiaohui的用户
root@k8s-master:~# cd /etc/kubernetes/pki
root@k8s-master:/etc/kubernetes/pki# openssl genrsa -out lixiaohui.key 2048
root@k8s-master:/etc/kubernetes/pki# openssl req -new -key lixiaohui.key -out lixiaohui.csr -subj "/O=kubeusers/CN=lixiaohui"
root@k8s-master:/etc/kubernetes/pki# openssl x509 -req -in lixiaohui.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out lixiaohui.crt -days 365
Certificate request self-signature ok
subject=O = kubeusers, CN = lixiaohui\0A向系统中添加lixiaohui用户
root@k8s-master:/etc/kubernetes/pki# kubectl config set-credentials lixiaohui --client-certificate=lixiaohui.crt --client-key=lixiaohui.key --embed-certs=true
User "lixiaohui" set.允许lixiaohui可以访问kubernetes集群
root@k8s-master:~# kubectl config set-context lixiaohui@kubernetes --cluster=kubernetes --user=lixiaohui
Context "lixiaohui@kubernetes" created.切换到lixiaohui用户以及切换回超级管理员
root@k8s-master:~# kubectl config use-context lixiaohui@kubernetes
Switched to context "lixiaohui@kubernetes".
root@k8s-master:~# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".17.3 ServiceAaccount
17.3.1 ServiceAaccount的概念
Service account是为了方便Pod里面的进程调用Kubernetes API或 其他外部服务而设计的
每个namespace都会自动创建一个default service account
Token controller检测service account的创建,并为它们创建secret(token),与APIServer进行交互
root@k8s-master:~# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 104d
nfs-client-provisioner 0 3d23h
root@k8s-master:~# kubectl get serviceaccounts -n test
NAME SECRETS AGE
default 0 151m
root@k8s-master:~# kubectl get secrets
NAME TYPE DATA AGE
mysqlpass Opaque 1 45h
root@k8s-master:~# kubectl get secrets -n test
No resources found in test namespace.当创建 Pod 时,如果没有指定服务账户,Pod 会被指定给命名空间中的 default 服务账户。
container启动后都会挂载该service account的token和ca.crt到如下位置:/var/run/secrets/kubernetes.io/serviceaccount/
pod 和 apiserver 之 间 进 行 通 信 的 账 号 , 称 为 serviceAccountName
root@k8s-master:~# kubectl get pod -o yaml | grep -i serviceaccount
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
serviceAccount: default
serviceAccountName: default
- serviceAccountToken:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
serviceAccount: default
serviceAccountName: default
......17.3.2 创建ServiceAaccount
在一个名为test的namespace中,创建一个名为lixiaohui的ServiceAccount
root@k8s-master:~# kubectl create namespace test
namespace/test created
root@k8s-master:~# kubectl create serviceaccount lixiaohui -n test
serviceaccount/lixiaohui created
root@k8s-master:~# kubectl get serviceaccounts lixiaohui -n test
NAME SECRETS AGE
lixiaohui 0 26s
root@k8s-master:~# kubectl -n test describe serviceaccounts lixiaohui
Name: lixiaohui
Namespace: test
Labels: <none>
Annotations: <none>
Image pull secrets: <none>
Mountable secrets: <none>
Tokens: <none>
Events: <none>创建了seviceaccount之后,会发现用于和apiserver交互的secret也创建好了
root@k8s-master:~# kubectl get secrets -n test17.4 Role和ClusterRole
RBAC API 声明了四种 Kubernetes 对象:Role、ClusterRole、RoleBinding 和 ClusterRoleBinding
RBAC 的 Role 或 ClusterRole 中包含一组代表相关权限的规则,这些权限是纯粹累加的(不存在拒绝某操作的规则)
Role 总是用来在某个名字空间内设置访问权限;在创建 Role 时,必须指定该 Role 所属的名字空间
ClusterRole 是一个集群作用域的资源。这两种资源的名字不同(Role 和 ClusterRole)是因为 Kubernetes 对象要么是名字空间作用域的,要么是集群作用域的, 不可两者兼具。
如果希望在名字空间内定义角色,应该使用 Role, 如果希望定义集群范围的角色,应该使用ClusterRole
17.4.1 Role
在名为test的namespace中创建一个名为test-role的角色,以及创建一个名为test-clusterrole的集群角色
创建一个名为test-role仅有查看pod的角色
命令行方法:
root@k8s-master:~# kubectl -n test create role --resource=pod --verb=get test-role
role.rbac.authorization.k8s.io/test-role created
root@k8s-master:~# kubectl -n test delete role test-role
role.rbac.authorization.k8s.io "test-role" deletedYAML方法:
cat > role.yml <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: test-role
namespace: test
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
EOFroot@k8s-master:~# kubectl create -f role.yml
role.rbac.authorization.k8s.io/test-role created
root@k8s-master:~# kubectl get -f role.yml
NAME CREATED AT
test-role 2025-07-21T08:43:08Z
root@k8s-master:~# kubectl describe role -n test test-role
Name: test-role
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
pods [] [] [get]17.4.2 RoleBinding
角色绑定(Role Binding)是将角色中定义的权限赋予一个或者一组用户。 它包含若干 主体(用户、组或服务账户)的列表和对这些主体所获得的角色的引用。
RoleBinding 在指定的名字空间中执行授权,而 ClusterRoleBinding 在集群范围执行授权
一个 RoleBinding 可以引用同一的名字空间中的任何 Role。 或者,一个 RoleBinding 可以引用某ClusterRole 并将该 ClusterRole 绑定到 RoleBinding 所在的名字空间。
如果希望将某ClusterRole绑定到集群中所有名字空间,要使用ClusterRoleBinding
将上述创建的lixiaohui服务账号和本role绑定:
root@k8s-master:~# kubectl -n test create rolebinding --role=test-role --serviceaccount=test:lixiaohui lixiaohui-binding
rolebinding.rbac.authorization.k8s.io/lixiaohui-binding created
root@k8s-master:~# kubectl -n test describe rolebinding lixiaohui-binding
Name: lixiaohui-binding
Labels: <none>
Annotations: <none>
Role:
Kind: Role
Name: test-role
Subjects:
Kind Name Namespace
---- ---- ---------
ServiceAccount lixiaohui test测试权限:
root@k8s-master:~# kubectl -n test auth can-i create pods --as=system:serviceaccount:test:lixiaohui
no
root@k8s-master:~# kubectl -n test auth can-i get pods --as=system:serviceaccount:test:lixiaohui
yes17.4.3 ClusterRole
Kubernetes还提供了四个内置的ClusterRole来供用户直接使用
1.cluster-admin:整个kubernetes中权限最高的角色,请谨慎使用
2.admin:规定了大部分资源(不包括node)的权限
3.edit:规定了大部分资源的修改权限的角色
4.view:规定了大部分资源只读权限的角色
创建一个名为test-clusterrole仅有创建pod和deployment的角色:
命令行创建:
root@k8s-master:~# kubectl create clusterrole --resource=pod,deployment --verb=create test-clusterrole
clusterrole.rbac.authorization.k8s.io/test-clusterrole created
root@k8s-master:~# kubectl describe clusterrole test-clusterrole
Name: test-clusterrole
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
pods [] [] [create]
deployments.apps [] [] [create]
root@k8s-master:~# kubectl delete clusterrole test-clusterrole
clusterrole.rbac.authorization.k8s.io "test-clusterrole" deletedYAML文件创建:
cat > clusterrole.yml <<EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: test-clusterrole
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- create
- get
- apiGroups:
- apps
resources:
- deployments
verbs:
- create
- get
EOFroot@k8s-master:~# kubectl create -f clusterrole.yml
clusterrole.rbac.authorization.k8s.io/test-clusterrole created
root@k8s-master:~# kubectl describe clusterrole test-clusterrole
Name: test-clusterrole
Labels: <none>
Annotations: <none>
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
pods [] [] [create get]
deployments.apps [] [] [create get]17.4.4 ClusterRoleBinding
将lixiaohui用户和clusterrole绑定,并测试权限:
root@k8s-master:~# kubectl create clusterrolebinding --clusterrole=test-clusterrole --serviceaccount=test:lixiaohui lixiaohui-clusterbind
clusterrolebinding.rbac.authorization.k8s.io/lixiaohui-clusterbind created
root@k8s-master:~# kubectl describe clusterrolebinding lixiaohui-clusterbind
Name: lixiaohui-clusterbind
Labels: <none>
Annotations: <none>
Role:
Kind: ClusterRole
Name: test-clusterrole
Subjects:
Kind Name Namespace
---- ---- ---------
ServiceAccount lixiaohui test
root@k8s-master:~# kubectl auth can-i get pods --as=system:serviceaccount:test:lixiaohui
yes
root@k8s-master:~# kubectl auth can-i create pods --as=system:serviceaccount:test:lixiaohui
yes
root@k8s-master:~# kubectl auth can-i create deployments --as=system:serviceaccount:test:lixiaohui
yes
root@k8s-master:~# kubectl auth can-i create secret --as=system:serviceaccount:test:lixiaohui
no
root@k8s-master:~# kubectl auth can-i create service --as=system:serviceaccount:test:lixiaohui
no17.5 网略策略(Network Plocy)
Pod 可以通信的 Pod 是通过如下三个标识符的组合来辩识的:
1.其他被允许的 Pods(例外:Pod 无法阻塞对自身的访问)
2.被允许的名字空间
3.IP 组块(与 Pod 运行所在的节点的通信总是被允许的, 无论 Pod 或节点的 IP 地址)
在定义基于 Pod 或名字空间的 NetworkPolicy 时,使用选择算符来设定哪些流量 可以进入或离开与该算符匹配的Pod,
同时,当基于 IP 的 NetworkPolicy 被创建时,我们基于 IP 组块(CIDR 范围) 来定义策略
Pod隔离:
默认情况下,Pod 是非隔离的,它们接受任何来源的流量。
Pod 在被某 NetworkPolicy 选中时进入被隔离状态, 一旦名字空间中有 NetworkPolicy 选择了特定的Pod,该 Pod 会拒绝该 NetworkPolicy 所不允许的连接。
网络策略不会冲突,它们是累积的。 如果任何一个或多个策略选择了一个 Pod, 则该 Pod 受限于这些策略的 入站(Ingress)/出站(Egress)规则的并集,因此评估的顺序并不会影响策略的结果。
为了允许两个 Pods 之间的网络数据流,源端 Pod 上的出站(Egress)规则和目标端 Pod 上的入站(Ingress)规则都需要允许该流量。 如果源端的出站(Egress)规则或目标端的入站(Ingress)规则拒绝该流量, 则流量将被拒绝
创建NetworkPolicy:
在名为zhangsan的namespace中,创建一个仅允许来自名为lixiaohui的namespace连接的网络策略
创建两个namesapce
root@k8s-master:~# kubectl create namespace zhangsan
namespace/zhangsan created
root@k8s-master:~# kubectl create namespace lixiaohui
namespace/lixiaohui created
root@k8s-master:~# kubectl get ns
NAME STATUS AGE
calico-apiserver Active 104d
calico-system Active 104d
default Active 104d
kube-node-lease Active 104d
kube-public Active 104d
kube-system Active 104d
lixiaohui Active 11s
test Active 5h21m
tigera-operator Active 104d
zhangsan Active 19s在zhangsan的namespace中,新建一个pod
cat > nppod.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: pod
namespace: zhangsan
labels:
app: httpd
spec:
containers:
- name: httpd
image: httpd:2.4
imagePullPolicy: IfNotPresent
ports:
- name: web
containerPort: 80
restartPolicy: OnFailure
EOFroot@k8s-master:~# kubectl create -f nppod.yml
pod/pod created
root@k8s-master:~# kubectl get pod -n zhangsan -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod 1/1 Running 0 18s 172.16.194.96 k8s-worker1 <none> <none>在lixiaohui的namespace中,新建一个pod
cat > nppod1.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: pod1
namespace: lixiaohui
labels:
app: nginx
spec:
containers:
- name: httpd
image: httpd:2.4
imagePullPolicy: IfNotPresent
ports:
- name: web
containerPort: 80
restartPolicy: OnFailure
EOFroot@k8s-master:~# kubectl create -f nppod1.yml
pod/pod1 created
root@k8s-master:~# kubectl get pod -n lixiaohui -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod1 1/1 Running 0 19s 172.16.194.97 k8s-worker1 <none> <none>新建网络策略:
cat > np.yml <<EOF
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-namesapce-lixiaohui
namespace: zhangsan
spec:
podSelector: {}
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: lixiaohui
ports:
- protocol: TCP
port: 80
EOFroot@k8s-master:~# kubectl create -f np.yml
networkpolicy.networking.k8s.io/allow-from-namesapce-lixiaohui created
root@k8s-master:~# kubectl get -f np.yml
NAME POD-SELECTOR AGE
allow-from-namesapce-lixiaohui <none> 9s
root@k8s-master:~# kubectl describe networkpolicies -n zhangsan
Name: allow-from-namesapce-lixiaohui
Namespace: zhangsan
Created on: 2025-07-21 21:52:17 +0800 CST
Labels: <none>
Annotations: <none>
Spec:
PodSelector: <none> (Allowing the specific traffic to all pods in this namespace)
Allowing ingress traffic:
To Port: 80/TCP
From:
NamespaceSelector: kubernetes.io/metadata.name=lixiaohui
Not affecting egress traffic
Policy Types: Ingress测试效果:
cat > nptest.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: pod-default
spec:
containers:
- name: busybox
image: busybox:1.32.1
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- "sleep 10m"
restartPolicy: OnFailure
EOF
root@k8s-master:~# kubectl create -f nptest.yml
pod/pod-default created
root@k8s-master:~# kubectl get -f nptest.yml
NAME READY STATUS RESTARTS AGE
pod-default 1/1 Running 0 19s从default namespace中访问没有被网络策略选中的pod,发现成功访问:
root@k8s-master:~# kubectl exec -it pod-default -- wget 172.16.194.97
Connecting to 172.16.194.97 (172.16.194.97:80)
saving to 'index.html'
index.html 100% |********************************| 45 0:00:00 ETA
'index.html' saved从default namespace中访问被网络策略选中的pod,发现无法访问:
root@k8s-master:~# kubectl exec -it pod-default -- wget 172.16.194.96
Connecting to 172.16.194.96 (172.16.194.96:80)新建一个lixiaohui namespace的pod,测试是否可以访问被隔离的pod,由于网络策略的原因,一定是可以访问的
cat > nplixiaohuitest.yml <<EOF
apiVersion: v1
kind: Pod
metadata:
name: pod-lixiaohui-test
namespace: lixiaohui
spec:
containers:
- name: busybox
image: busybox:1.32.1
imagePullPolicy: IfNotPresent
command:
- /bin/sh
- -c
- "sleep 10m"
restartPolicy: OnFailure
EOF
root@k8s-master:~# kubectl create -f nplixiaohuitest.yml
pod/pod-lixiaohui-test created
root@k8s-master:~# kubectl get -f nplixiaohuitest.yml
NAME READY STATUS RESTARTS AGE
pod-lixiaohui-test 1/1 Running 0 11s以下测试中,发现可以正常访问zhangsan namesapce中的pod:
root@k8s-master:~# kubectl -n lixiaohui exec -it pod-lixiaohui-test -- wget 172.16.194.96
Connecting to 172.16.194.96 (172.16.194.96:80)
saving to 'index.html'
index.html 100% |********************************| 45 0:00:00 ETA
'index.html' saved18 Helm 概念与实践
18.1 Helm基本概念
Helm 是 Kubernetes 的官方包管理工具,类似于Linux系统的APT/YUM或Python的PIP,它能够简化 Kubernetes 应用程序的部署和管理。
在 Kubernetes 中,一个应用程序可能由多个资源组成,比如 Deployment、Service、ConfigMap、Ingress 等。Helm 可以将这些资源打包成一个 Helm Chart(包),方便用户进行安装、升级、回滚和删除等操作,实现应用的声明式部署、版本控制和配置管理。
核心价值:
1.简化复杂应用部署:将微服务拆分的数十个 YAML 文件打包为单一 Chart,降低运维复杂度。
2.标准化交付流程:支持跨环境(开发/测试/生产)的一致性部署。
3.生态协同:通过公共仓库(如 Artifact Hub)共享开源应用,企业可搭建私有仓库管理内部应用。
18.2 Helm核心概念

18.3 主要组件
Helm Client
这是用户与 Helm 交互的客户端工具。用户通过在本地机器上运行 Helm 命令来操作 Helm Chart,例如安装、升级、查询等操作。它会直接与 Kubernetes API 服务器交互,客户端可以直接从它的官方GitHub下载,地址是:https://github.com/helm/helm/releases
Helm Chart
Helm Chart 是一个打包的 Kubernetes 应用程序,包含所有必要的资源定义和配置文件。它类似于软件包管理工具中的“包”,用于简化 Kubernetes 应用的部署和管理。一个 Helm Chart 包含以下部分:
1.Chart.yaml
定义:这是 Helm Chart 的元数据文件,包含 Chart 的基本信息。大概内容:
name:Chart 的名称
version:Chart 的版本号(遵循语义化版本规范)
description:Chart 的简要描述
dependencies:依赖的其他 Chart(可选)
2.values.yaml
它是 Chart 的默认配置文件。用户可以通过修改这个文件或者在安装时覆盖其中的值来定制 Chart 的行为。比如,它可能包含应用的副本数量、镜像版本、资源限制等配置项。
3.templates
包含 Kubernetes 资源的模板文件,这些模板文件在安装或升级时会被渲染成实际的 Kubernetes 资源,渲染的时候,将用values.yaml里的值替换掉templates模板里的变量,例如,一个 Deployment 的模板文件可以根据 values.yaml 中定义的副本数量和镜像版本来生成对应的 Deployment 资源,具体渲染的命令是:helm template,可以用–help等方式获取语法,不过需要注意的是,这会渲染出实际的 Kubernetes 资源文件,但不会实际部署到集群中。
4.charts
如果当前 Chart 依赖其他 Chart,这些依赖的 Chart 会存放在这个目录下。这样可以实现 Chart 之间的组合和复用。
Helm Repository(仓库)
它是一个存储 Helm Chart 的仓库,可以是本地的,也可以是远程的。远程仓库通常是一个 HTTP 服务器,用户可以从仓库中搜索、下载和更新 Helm Chart。例如,Helm 官方维护了一个默认的公共仓库,里面包含了许多常用的 Helm Chart,用户可以通过 Helm 命令将这些 Chart 添加到本地的 Chart 仓库列表中,然后进行安装等操作。
官方网址 http://helm.sh
18.4 Helm安装
用二进制版本安装:
每个Helm版本都提供了各种操作系统的二进制版本,这些版本可以手动下载和安装
1.下载需要的版本
root@k8s-master:~# wget https://get.helm.sh/helm-v3.17.4-linux-amd64.tar.gz
2.解压
root@k8s-master:~# tar xf helm-v3.17.4-linux-amd64.tar.gz
3.在解压目录中找到helm程序,移动到需要的目录中
root@k8s-master:~# mv linux-amd64/helm /usr/local/bin/helm
root@k8s-master:~# helm version
version.BuildInfo{Version:"v3.17.4", GitCommit:"595a05da6166037d0abebaa27ac8a498fa4d7ed2", GitTreeState:"clean", GoVersion:"go1.23.10"}
root@k8s-master:~# helm completion bash > /etc/bash_completion.d/helm默认情况下,helm内置了一个hub,用于软件搜索和安装,搜索软件是否可被安装,用以下格式命令:
root@k8s-master:~# helm search hub packages
URL CHART VERSION APP VERSION DESCRIPTION
https://artifacthub.io/packages/helm/ygdrassil/... 0.1.0 4.0.1 AeneaBot is a Telegram Chat Bot which includes ...
https://artifacthub.io/packages/helm/zerotest/a... 1.1.0 1.1.0 Artifact Hub is a web-based application that en...
https://artifacthub.io/packages/helm/artifact-h... 1.21.0 1.21.0 Artifact Hub is a web-based application that en...
https://artifacthub.io/packages/helm/softonic/a... 1.19.0 1.19.0 Artifact Hub is a web-based application that en...
https://artifacthub.io/packages/helm/angelnu/ch... 3.0.0 latest Multiplexer for lorawan gateway packages
https://artifacthub.io/packages/helm/obeone/olv... 0.2.0 1.5.0 Olvid bot-daemon — a bridge service that lets y...
https://artifacthub.io/packages/helm/ygdrassil/... 0.4.0 0.3.0 Raponchi is a silly bot which posts in Twitter ...
https://artifacthub.io/packages/helm/szpadel-ch... 3.52.17 1.4.0 Repman - PHP Repository Manager: packagist prox...
https://artifacthub.io/packages/helm/victoriame... 0.0.8 v1.25.1 The VictoriaLogs cluster chart packages everyth...
https://artifacthub.io/packages/helm/ygdrassil/... 0.4.0 0.4.0 Metapackage to deploy Ygdrassil Project monitor...命令行显示有点奇怪,也不够丰富,可以考虑用浏览器打开搜索:https://hub.helm.sh
18.5 添加仓库
官方仓库网速慢,可以考虑一下以下仓库或自己部署仓库
root@k8s-master:~# helm repo add azurerepo http://mirror.azure.cn/kubernetes/charts/
"azurerepo" has been added to your repositories添加的仓库地址:http://mirror.azure.cn/kubernetes/charts/
18.6 wordpress安装
18.6.1 手工定制安装
root@k8s-master:~# helm search repo wordpress
NAME CHART VERSION APP VERSION DESCRIPTION
azurerepo/wordpress 9.0.3 5.3.2 DEPRECATED Web publishing platform for building...
// 下载安装包并解压
root@k8s-master:~# helm pull azurerepo/wordpress
root@k8s-master:~# ls
wordpress-9.0.3.tgz
root@k8s-master:~# tar xf wordpress-9.0.3.tgz
root@k8s-master:~# ls
wordpresswordpress-9.0.3.tgz
root@k8s-master:~# cd wordpress/
// 看到了Chart.yaml templates values.yaml
root@k8s-master:~/wordpress# ls
charts Chart.yaml README.md requirements.lock requirements.yaml templates values.schema.json values.yaml
root@k8s-master:~/wordpress# ls templates/
deployment.yaml _helpers.tpl NOTES.txt secrets.yaml svc.yaml tls-secrets.yaml
externaldb-secrets.yaml ingress.yaml pvc.yaml servicemonitor.yaml tests模板里面都是各种变量,稍后需要用values.yml来填充:
root@k8s-master:~/wordpress# head templates/deployment.yaml
apiVersion: {{ template "wordpress.deployment.apiVersion" . }}
kind: Deployment
metadata:
name: {{ template "wordpress.fullname" . }}
labels: {{- include "wordpress.labels" . | nindent 4 }}
spec:
selector:
matchLabels: {{- include "wordpress.matchLabels" . | nindent 6 }}
{{- if .Values.updateStrategy }}
strategy: {{ toYaml .Values.updateStrategy | nindent 4 }}用values.yml里的变量来渲染模板,生成最终的yaml文件:
// 从仓库中读出values.yml,将templates目录里的模板渲染成功
root@k8s-master:~/wordpress# helm template --version 9.0.3 azurerepo/wordpress
WARNING: This chart is deprecated
---
# Source: wordpress/charts/mariadb/templates/secrets.yaml
apiVersion: v1
kind: Secret
metadata:
name: release-name-mariadb
labels:
app: "mariadb"
chart: "mariadb-7.3.12"
release: "release-name"
heritage: "Helm"
type: Opaque
data:
mariadb-root-password: "RjY4UE5nbDk2UA=="
mariadb-password: "RjJqTVJXTHZkeA=="
---
# Source: wordpress/templates/secrets.yaml
apiVersion: v1
kind: Secret
......如果有值不满意,可以手工指定某一个参数,或者用本地的values.yaml
先试试手工指定,看了一下仓库里的value,要用这个镜像,随便改一个看看
root@k8s-master:~/wordpress# helm show values azurerepo/wordpress | grep ^image: -A 10
image:
registry: docker.io
repository: bitnami/wordpress
tag: 5.3.2-debian-10-r32
## Specify a imagePullPolicy
## Defaults to 'Always' if image tag is 'latest', else set to 'IfNotPresent'
## ref: http://kubernetes.io/docs/user-guide/images/#pre-pulling-images
##
pullPolicy: IfNotPresent
## Optionally specify an array of imagePullSecrets.
## Secrets must be manually created in the namespace.渲染时手工指定某个参数,比如替换一个镜像的registry,通过–set参数指定了镜像的registry,并且生成了模板:
root@k8s-master:~/wordpress# helm template --version 9.0.3 azurerepo/wordpress --set image.registry=linuxcenter.cn > custom.yml
WARNING: This chart is deprecated
root@k8s-master:~/wordpress# grep linuxcenter custom.yml
image: linuxcenter.cn/bitnami/wordpress:5.3.2-debian-10-r32
image: linuxcenter.cn/bitnami/wordpress:5.3.2-debian-10-r32上面的set是瞎写的,镜像仓库不存在,只是为了演示参数,重新用默认参数渲染出最终的yaml,然后向集群部署。这一步将安装mariadb和wordpress,这里用的是存储章节设置的默认存储类,所以会自动创建pv以及pvc,要是还没有默认存储类,往上翻,重新做一下存储类并标记为默认即可
root@k8s-master:~/wordpress# helm template --version 9.0.3 azurerepo/wordpress > lixiaohui.yml
WARNING: This chart is deprecated
root@k8s-master:~/wordpress# kubectl apply -f lixiaohui.yml
secret/release-name-mariadb created
secret/release-name-wordpress created
configmap/release-name-mariadb created
configmap/release-name-mariadb-tests created
persistentvolumeclaim/release-name-wordpress created
service/release-name-mariadb created
service/release-name-wordpress created
deployment.apps/release-name-wordpress created
statefulset.apps/release-name-mariadb created
pod/release-name-mariadb-test-mfwqi created
pod/release-name-credentials-test created不需要看到pod工作正常,只研究helm自身,如果你需要它工作正常,需要搞定镜像、机器内存需要再加一下,不然数据库起不来
以上就是研究的过程,其实一般来说,不用这么麻烦,比如我们最后实际上就是用的默认value,如果默认value你就满意,可以用下面的方法直接让helm来管理,我们不用改东西,如果你并不是用的helm install,后面就不受helm管理,因为当你使用 helm template 命令生成 Kubernetes 资源清单文件并手动将其部署到集群中时,这些资源不会被 Helm 的生命周期管理所跟踪。因此,当你运行 helm list 命令时,不会看到任何相关的 Helm Release,因为 Helm 的 Release 管理机制没有被触发。
18.6.2 helm仓库直接安装
这一步将安装mariadb和wordpress,这里用的是存储章节设置的默认存储类,所以会自动创建pv以及pvc,你要是还没有默认存储类,往上翻,重新做一下存储类并标记为默认即可
helm install 也是只是--set参数的,不一定非要用默认的值
root@k8s-master:~/wordpress# helm install wordpress azurerepo/wordpress
WARNING: This chart is deprecated
NAME: wordpress
LAST DEPLOYED: Tue Jul 22 11:25:19 2025
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
This Helm chart is deprecated
......
root@k8s-master:~/wordpress# helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
wordpress default 1 2025-07-22 11:25:19.467906563 +0800 CST deployed wordpress-9.0.3 5.3.2查询服务端口和pod所在节点:
root@k8s-master:~/wordpress# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
wordpress LoadBalancer 10.96.139.221 <pending> 80:32231/TCP,443:31808/TCP 3m12s
wordpress-mariadb ClusterIP 10.100.62.255 <none> 3306/TCP 3m12s
// 不需要看到pod工作正常,只研究helm自身,如果需要它工作正常,需要搞定镜像、机器内存需要再加一下,不然数据库起不来
root@k8s-master:~/wordpress# kubectl get pod -o wide18.7 Dashboard安装
为了安全,不要在任何生产环境中使用dashboard
添加helm仓库:
root@k8s-master:~# helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
Error: looks like "https://kubernetes.github.io/dashboard/" is not a valid chart repository or cannot be reached: Get "https://kubernetes.github.io/dashboard/index.yaml": read tcp 192.168.8.3:55470->185.199.111.153:443: read: connection reset by peer
root@k8s-master:~# helm repo add kubernetes-dashboard https://oss.linuxcenter.cn/files/cka/helm
"kubernetes-dashboard" has been added to your repositories部署dashboard:
root@k8s-master:~# helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard
Release "kubernetes-dashboard" does not exist. Installing it now.
NAME: kubernetes-dashboard
LAST DEPLOYED: Tue Jul 22 11:37:56 2025
NAMESPACE: kubernetes-dashboard
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
*************************************************************************************************
*** PLEASE BE PATIENT: Kubernetes Dashboard may need a few minutes to get up and become ready ***
*************************************************************************************************
Congratulations! You have just installed Kubernetes Dashboard in your cluster.
To access Dashboard run:
kubectl -n kubernetes-dashboard port-forward svc/kubernetes-dashboard-kong-proxy 8443:443
NOTE: In case port-forward command does not work, make sure that kong service name is correct.
Check the services in Kubernetes Dashboard namespace using:
kubectl -n kubernetes-dashboard get svc
Dashboard will be available at:
https://localhost:8443查看具体部署了什么:
root@k8s-master:~# kubectl get all -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/kubernetes-dashboard-api-6dc59d487d-qx52x 1/1 Running 0 2m21s
pod/kubernetes-dashboard-auth-85cdc4974f-5k65d 1/1 Running 0 2m21s
pod/kubernetes-dashboard-kong-79867c9c48-qlw4p 1/1 Running 0 2m21s
pod/kubernetes-dashboard-metrics-scraper-76df4956c4-rlgtc 1/1 Running 0 2m21s
pod/kubernetes-dashboard-web-56df7655d9-nc9fc 1/1 Running 0 2m21s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes-dashboard-api ClusterIP 10.102.148.211 <none> 8000/TCP 2m21s
service/kubernetes-dashboard-auth ClusterIP 10.103.11.172 <none> 8000/TCP 2m21s
service/kubernetes-dashboard-kong-proxy ClusterIP 10.101.12.174 <none> 443/TCP 2m21s
service/kubernetes-dashboard-metrics-scraper ClusterIP 10.102.77.130 <none> 8000/TCP 2m21s
service/kubernetes-dashboard-web ClusterIP 10.109.209.151 <none> 8000/TCP 2m21s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kubernetes-dashboard-api 1/1 1 1 2m21s
deployment.apps/kubernetes-dashboard-auth 1/1 1 1 2m21s
deployment.apps/kubernetes-dashboard-kong 1/1 1 1 2m21s
deployment.apps/kubernetes-dashboard-metrics-scraper 1/1 1 1 2m21s
deployment.apps/kubernetes-dashboard-web 1/1 1 1 2m21s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kubernetes-dashboard-api-6dc59d487d 1 1 1 2m21s
replicaset.apps/kubernetes-dashboard-auth-85cdc4974f 1 1 1 2m21s
replicaset.apps/kubernetes-dashboard-kong-79867c9c48 1 1 1 2m21s
replicaset.apps/kubernetes-dashboard-metrics-scraper-76df4956c4 1 1 1 2m21s
replicaset.apps/kubernetes-dashboard-web-56df7655d9 1 1 1 2m21s在中国会遇到了镜像无法下载的情况,看看都有哪些镜像?
root@k8s-master:~# kubectl get deployments.apps -n kubernetes-dashboard -o yaml | grep image:
image: docker.io/kubernetesui/dashboard-api:1.12.0
image: docker.io/kubernetesui/dashboard-auth:1.2.4
image: kong:3.8
image: kong:3.8
image: docker.io/kubernetesui/dashboard-metrics-scraper:1.2.2
image: docker.io/kubernetesui/dashboard-web:1.6.2在所有的节点上都准备一下镜像:
docker pull registry.myk8s.cn/kubernetesui/dashboard-api:1.12.0
docker pull registry.myk8s.cn/kubernetesui/dashboard-auth:1.2.4
docker pull registry.myk8s.cn/library/kong:3.8
docker pull registry.myk8s.cn/kubernetesui/dashboard-metrics-scraper:1.2.2
docker pull registry.myk8s.cn/kubernetesui/dashboard-web:1.6.2
docker tag registry.myk8s.cn/kubernetesui/dashboard-api:1.12.0 docker.io/kubernetesui/dashboard-api:1.12.0
docker tag registry.myk8s.cn/kubernetesui/dashboard-auth:1.2.4 docker.io/kubernetesui/dashboard-auth:1.2.4
docker tag registry.myk8s.cn/library/kong:3.8 kong:3.8
docker tag registry.myk8s.cn/kubernetesui/dashboard-metrics-scraper:1.2.2 docker.io/kubernetesui/dashboard-metrics-scraper:1.2.2
docker tag registry.myk8s.cn/kubernetesui/dashboard-web:1.6.2 docker.io/kubernetesui/dashboard-web:1.6.2
docker rmi registry.myk8s.cn/kubernetesui/dashboard-api:1.12.0
docker rmi registry.myk8s.cn/kubernetesui/dashboard-auth:1.2.4
docker rmi registry.myk8s.cn/library/kong:3.8
docker rmi registry.myk8s.cn/kubernetesui/dashboard-metrics-scraper:1.2.2
docker rmi registry.myk8s.cn/kubernetesui/dashboard-web:1.6.2重启deployment:
root@k8s-master:~# kubectl get deployments.apps -n kubernetes-dashboard -o name | xargs kubectl rollout restart -n kubernetes-dashboard
deployment.apps/kubernetes-dashboard-api restarted
deployment.apps/kubernetes-dashboard-auth restarted
deployment.apps/kubernetes-dashboard-kong restarted
deployment.apps/kubernetes-dashboard-metrics-scraper restarted
deployment.apps/kubernetes-dashboard-web restarted看看pod状态:
root@k8s-master:~# kubectl get pod -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
kubernetes-dashboard-api-6f4dbb77f7-2r6dq 1/1 Running 0 113s
kubernetes-dashboard-auth-86d5ff99c6-kk2xw 1/1 Running 0 113s
kubernetes-dashboard-kong-85f48497cf-cgjxw 1/1 Running 0 113s
kubernetes-dashboard-metrics-scraper-7f44579d58-s9ddn 1/1 Running 0 113s
kubernetes-dashboard-web-6849df5ccc-7vzvv 1/1 Running 0 113s看到kong-proxy是ClusterIP,不方便查看,直接改为nodeport,就可以用任何节点的ip打开查看了
root@k8s-master:~# kubectl edit service -n kubernetes-dashboard kubernetes-dashboard-kong-proxy
...
spec:
type: NodePort
service/kubernetes-dashboard-kong-proxy edited看看端口是多少:
root@k8s-master:~# kubectl get service -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard-api ClusterIP 10.102.148.211 <none> 8000/TCP 12m
kubernetes-dashboard-auth ClusterIP 10.103.11.172 <none> 8000/TCP 12m
kubernetes-dashboard-kong-proxy NodePort 10.101.12.174 <none> 443:30925/TCP 12m
kubernetes-dashboard-metrics-scraper ClusterIP 10.102.77.130 <none> 8000/TCP 12m
kubernetes-dashboard-web ClusterIP 10.109.209.151 <none> 8000/TCP 12m浏览器访问:https://192.168.8.3:30925/#/login
创建一个用户登录的超级用户,并创建长期有效的token
cat > create-dash-user.yml <<-'EOF'
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: lxh-dash
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: lxh-dash-cluster-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: lxh-dash
namespace: kubernetes-dashboard
---
apiVersion: v1
kind: Secret
metadata:
name: lxh-dash-secret
namespace: kubernetes-dashboard
annotations:
kubernetes.io/service-account.name: "lxh-dash"
type: kubernetes.io/service-account-token
EOFroot@k8s-master:~# kubectl create -f create-dash-user.yml
serviceaccount/lxh-dash created
clusterrolebinding.rbac.authorization.k8s.io/lxh-dash-cluster-admin created
secret/lxh-dash-secret created获取登录token:
root@k8s-master:~# kubectl get secret lxh-dash-secret -n kubernetes-dashboard -o jsonpath={".data.token"} | base64 -d
eyJhbGciOiJSUzI1NiIsImtpZCI6IklwMGJUWHYwVXNSS1QyN3pCSFFCWDlYaWowOVlOcm9VakhNMV9IWXhQNGsifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJseGgtZGFzaC1zZWNyZXQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoibHhoLWRhc2giLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJiMzZhZjM5MC1lNDQ3LTQ5ZWEtYTlkNS02NWQ1YTY1ZDhjYWIiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6bHhoLWRhc2gifQ.HnWCUW2iRs29MLthTGeAGiZo_yDj9jJLKg0Jv3ymCUO3U-A377T47NhlH2Q2mqTnV11ssBpb3XKEoOdSUz1fpzNG1aWIYgmz_N2dzl9W4amZcDGsQvRIoMA-amUsPpSamTfD6isXWE-t86FzUlvht0JBZZCKd_X4AavJ__pETsZGqGUvry82dqo7abJaLniKa4iI6wCGsHTAf6qq_05448qCf-CBAF3WEYgMnIn6HcGvRJfJLYGC3LH07xMfIAv9AVg_jOo5gNiJIKpRjEhAmCrOUO7k6Q3duxjLRcUBbO5gXh_7v8ClspOpsBpP3Pr40zQUUVAisLWkwIYustMzPg除了bash的root@master:~#提示符之外,把所有的内容复制一下,然后粘贴到登录框里并点击登录:
18.8 Helm常用命令
| 命令 | 作用 |
|---|---|
| helm create [chart-name] | 初始化一个新的Chart目录结构(含values.yaml、templates/ 等文件) |
| helm install [release-name] [chart-path] | 安装Chart到Kubernetes集群,生成指定名称的Release |
| helm list | 列出当前命名空间下所有已部署的Release |
| helm uninstall [release-name] | 卸载指定Release及其关联的Kubernetes资源 |
| helm search repo [keyword] | 在已添加的仓库中搜索Chart(支持 –version 指定版本) |
19 监控与升级
Kubernetes 在每个级别上提供有关应用程序资源使用情况的详细信息。 此信息使你可以评估应用程序的性能,以及在何处可以消除瓶颈以提高整体性能。
资源指标管道提供了一组与集群组件,例如 Horizontal Pod Autoscaler 控制器以及 kubectl top实用程序相关的有限度量。 这些指标是由轻量级的、短期、内存存储的 metrics-server 收集的,通过 metrics.k8s.io 公开。
19.1 部署Metrics
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
将image换成metrics-server:v0.6.1
在args中添加 - --kubelet-insecure-tls来解决自签名证书问题
kubectl create -f components.yaml
root@k8s-master:~# kubectl apply -f https://www.linuxcenter.cn/files/cka/cka-yaml/metrics-components.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created需要解决镜像的问题,在所有机器上都准备一下:
root@k8s-master:~# kubectl get deployments.apps -n kube-system metrics-server -o yaml | grep image:
image: registry.k8s.io/metrics-server/metrics-server:v0.7.2root@k8s-master:~# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.7.2
root@k8s-master:~# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.7.2 registry.k8s.io/metrics-server/metrics-server:v0.7.2
root@k8s-master:~# docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server:v0.7.2重启deployment触发部署:
root@k8s-master:~# kubectl rollout restart deployment -n kube-system metrics-server
deployment.apps/metrics-server restarted
// 部署好后,执行相关命令会返回结果
root@k8s-master:~# kubectl top nodes
NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
k8s-master 109m 5% 2358Mi 62%
k8s-worker1 45m 2% 775Mi 42%
k8s-worker2 91m 4% 968Mi 53%
root@k8s-master:~# kubectl top pod
NAME CPU(cores) MEMORY(bytes)
cnlxhtest 0m 3Mi
configmapvolume 1m 6Mi
emptydir 1m 10Mi
frontend 0m 3Mi
high-priority-test-7dc84c65ff-2wx7q 0m 3Mi
high-priority-test-7dc84c65ff-cltdl 0m 11Mi
high-priority-test-7dc84c65ff-hmplw 0m 3Mi
lxhnodename 0m 3Mi
nfs-client-provisioner-5998cfc9bc-zh2fv 2m 25Mi
nginx 0m 3Mi
require 0m 3Mi
tolerationsmust 0m 15Mi19.2 常规维护操作
1.查看pod详情,可通过最下面的event查看事件
root@k8s-master:~# kubectl describe pod frontend
2.查看pod日志
root@k8s-master:~# kubectl logs frontend
3.查看pod资源用量
root@k8s-master:~# kubectl top pod frontend
NAME CPU(cores) MEMORY(bytes)
frontend 0m 3Mi
4.查看节点资源用量
root@k8s-master:~# kubectl top nodes
NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
k8s-master 104m 5% 2349Mi 62%
k8s-worker1 31m 1% 747Mi 41%
k8s-worker2 39m 1% 1017Mi 55%
19.3 HPA 自动扩容
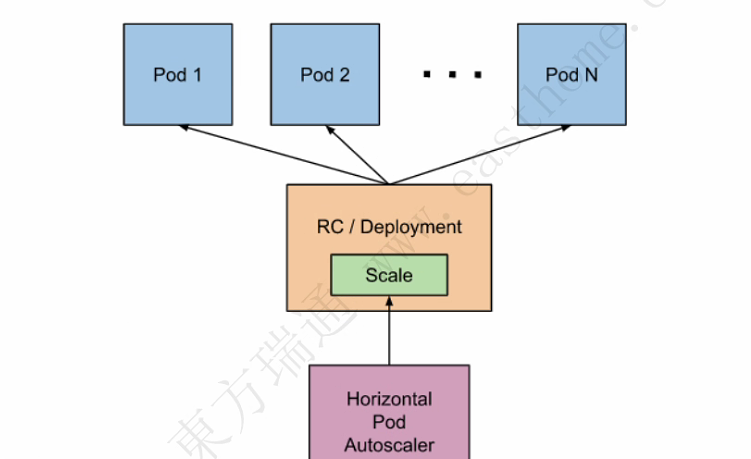
在部署了metrics server后,可以给HPA提供自动扩容的资源用量指标,帮助HPA快速识别用量,并完成自动扩容
先创建一个deployment以及上层的访问service
cat > hpatest.yml <<-EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: mirrorgooglecontainers/hpa-example
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
EOF根据以上代码,deployment创建了一个pod副本,service提供了一个名为php-apache的访问点
先在所有机器上下载一下镜像:
docker pull mirrorgooglecontainers/hpa-example创建后,测试一下pod和service本身是否可以访问
root@k8s-master:~# kubectl create -f hpatest.yml
deployment.apps/php-apache created
service/php-apache created
root@k8s-master:~# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
high-priority-test 3/3 3 3 3d2h
nfs-client-provisioner 1/1 1 1 4d22h
php-apache 1/1 1 1 13s
release-name-wordpress 0/1 1 0 3h34m
wordpress 0/1 1 0 3h32m
root@k8s-master:~# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 105d
php-apache ClusterIP 10.97.147.249 <none> 80/TCP 55s
release-name-mariadb ClusterIP 10.102.208.149 <none> 3306/TCP 3h35m
release-name-wordpress LoadBalancer 10.97.205.180 <pending> 80:32099/TCP,443:30311/TCP 3h35m
wordpress LoadBalancer 10.96.139.221 <pending> 80:32231/TCP,443:31808/TCP 3h33m
wordpress-mariadb ClusterIP 10.100.62.255 <none> 3306/TCP 3h33m
root@k8s-master:~# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
php-apache-869df9d947-n85hh 1/1 Running 0 67s 172.16.194.104 k8s-worker1 <none> <none>
root@k8s-master:~# curl 172.16.194.104
OK!
OK!root@k8s-master:~# curl 10.97.147.249
OK!经过测试,pod和service都可以访问,现在来做一个CPU利用率大于50,就扩容的例子
需要注意的是,这里为了规避瞬时高峰的波动,给扩容和缩容设置了稳定的时间窗口
1.扩容场景:
当 CPU 使用率超过目标值(50%)时,HPA 会检测到需要扩容。
但因为设置了 stabilizationWindowSeconds: 10,HPA 会等待 10 秒,观察这段时间内的 CPU 使用率是否持续高于目标值。
如果在这 10 秒内,CPU 使用率一直高于 50%,HPA 会执行扩容操作。
如果在这 10 秒内,CPU 使用率恢复正常(低于 50%),HPA 则不会执行扩容操作。
2.缩容场景:
当 CPU 使用率低于目标值(50%)时,HPA 会检测到需要缩容。
但因为设置了 stabilizationWindowSeconds: 30,HPA 会等待 30 秒,观察这段时间内的 CPU 使用率是否持续低于目标值。
如果在这 30 秒内,CPU 使用率一直低于 50%,HPA 会执行缩容操作。
如果在这 30 秒内,CPU 使用率恢复正常(高于 50%),HPA 则不会执行缩容操作。
cat > hpa.yml <<-'EOF'
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
behavior:
scaleUp:
stabilizationWindowSeconds: 10
scaleDown:
stabilizationWindowSeconds: 30
EOFroot@k8s-master:~# kubectl apply -f hpa.yml
horizontalpodautoscaler.autoscaling/php-apache created一分钟后,执行以下命令查看实时CPU利用率和目标的差距,并观察副本数
root@k8s-master:~# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache cpu: 0%/50% 1 10 1 95s启动一个不同的 Pod 作为客户端。 客户端 Pod 中的容器在无限循环中运行,向 php-apache 服务发送查询。
不断的访问,将产生压力,压力大了,hpa就会扩容
需要注意的是,需要先在所有节点上下载busybox镜像
root@k8s-master:~# kubectl run -i --tty load-generator --rm --image=busybox:1.32.1 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"运行后会不断的输出ok,不要结束输出,开一个新的ssh会话,运行以下命令,观察hpa收集到的信息以及pod的扩容情况:
// 按下CTRL C结束ok的输出,再次观察target的利用率下降
root@k8s-master:~# kubectl get hpa php-apache --watch
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache cpu: 0%/50% 1 10 1 5m49s
php-apache Deployment/php-apache cpu: 43%/50% 1 10 1 7m1s
php-apache Deployment/php-apache cpu: 250%/50% 1 10 1 7m16s
php-apache Deployment/php-apache cpu: 102%/50% 1 10 5 7m31s
php-apache Deployment/php-apache cpu: 57%/50% 1 10 5 7m46s
php-apache Deployment/php-apache cpu: 49%/50% 1 10 6 8m1s
php-apache Deployment/php-apache cpu: 48%/50% 1 10 6 8m16s
php-apache Deployment/php-apache cpu: 15%/50% 1 10 6 8m31s
php-apache Deployment/php-apache cpu: 0%/50% 1 10 6 8m46s
php-apache Deployment/php-apache cpu: 0%/50% 1 10 2 9m1s19.4 部署Prometheus
手工部署较为复杂,采用operator进行部署,先克隆它的operator,本次采用的是0.14.0版本
root@k8s-master:~# wget https://www.linuxcenter.cn/files/cka/kube-prometheus-0.14.0.tar
--2025-07-22 16:35:40-- https://www.linuxcenter.cn/files/cka/kube-prometheus-0.14.0.tar
Resolving www.linuxcenter.cn (www.linuxcenter.cn)... 120.226.91.62, 120.226.91.100, 117.135.206.157, ...
Connecting to www.linuxcenter.cn (www.linuxcenter.cn)|120.226.91.62|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 648980 (634K) [application/x-tar]
Saving to: ‘kube-prometheus-0.14.0.tar’
kube-prometheus-0.14.0.tar 100%[=========================================================================>] 633.77K 1.83MB/s in 0.3s
2025-07-22 16:35:45 (1.83 MB/s) - ‘kube-prometheus-0.14.0.tar’ saved [648980/648980]
root@k8s-master:~# tar xf kube-prometheus-0.14.0.tar
root@k8s-master:~# cd kube-prometheus-0.14.0
root@k8s-master:~/kube-prometheus-0.14.0# kubectl create -f manifests/setup/
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusagents.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/scrapeconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
namespace/monitoring created测试是否符合条件,如果上一步全部成功,这里会显示全部符合
root@k8s-master:~/kube-prometheus-0.14.0# kubectl wait --for condition=Established --all CustomResourceDefinition --namespace=monitoring在master上自动给所有节点准备容器镜像,此处会产生大量网络流量,需要较长时间,请耐心等待
cat > dockerimage <<'EOF'
#!/bin/bash
function sshcmd {
sshpass -p vagrant ssh root@$1 $2
}
echo
echo Pulling images on $(hostname)
echo
docker pull registry.myk8s.cn/prometheus/alertmanager:v0.27.0
docker pull registry.myk8s.cn/prometheus/blackbox-exporter:v0.25.0
docker pull registry.myk8s.cn/jimmidyson/configmap-reload:v0.13.1
docker pull registry.myk8s.cn/brancz/kube-rbac-proxy:v0.18.1
docker pull registry.myk8s.cn/grafana/grafana:11.2.0
docker pull registry.myk8s.cn/kube-state-metrics/kube-state-metrics:v2.13.0
docker pull registry.myk8s.cn/prometheus/node-exporter:v1.8.2
docker pull registry.myk8s.cn/prometheus-adapter/prometheus-adapter:v0.12.0
docker pull registry.myk8s.cn/prometheus-operator/prometheus-operator:v0.76.2
docker pull registry.myk8s.cn/prometheus/prometheus:v2.54.1
docker tag registry.myk8s.cn/prometheus/alertmanager:v0.27.0 quay.io/prometheus/alertmanager:v0.27.0
docker tag registry.myk8s.cn/prometheus/blackbox-exporter:v0.25.0 quay.io/prometheus/blackbox-exporter:v0.25.0
docker tag registry.myk8s.cn/jimmidyson/configmap-reload:v0.13.1 ghcr.io/jimmidyson/configmap-reload:v0.13.1
docker tag registry.myk8s.cn/brancz/kube-rbac-proxy:v0.18.1 quay.io/brancz/kube-rbac-proxy:v0.18.1
docker tag registry.myk8s.cn/grafana/grafana:11.2.0 grafana/grafana:11.2.0
docker tag registry.myk8s.cn/kube-state-metrics/kube-state-metrics:v2.13.0 registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.13.0
docker tag registry.myk8s.cn/prometheus/node-exporter:v1.8.2 quay.io/prometheus/node-exporter:v1.8.2
docker tag registry.myk8s.cn/prometheus-adapter/prometheus-adapter:v0.12.0 registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0
docker tag registry.myk8s.cn/prometheus-operator/prometheus-operator:v0.76.2 quay.io/prometheus-operator/prometheus-operator:v0.76.2
docker tag registry.myk8s.cn/prometheus/prometheus:v2.54.1 quay.io/prometheus/prometheus:v2.54.1
docker rmi registry.myk8s.cn/prometheus/alertmanager:v0.27.0
docker rmi registry.myk8s.cn/prometheus/blackbox-exporter:v0.25.0
docker rmi registry.myk8s.cn/jimmidyson/configmap-reload:v0.13.1
docker rmi registry.myk8s.cn/brancz/kube-rbac-proxy:v0.18.1
docker rmi registry.myk8s.cn/grafana/grafana:11.2.0
docker rmi registry.myk8s.cn/kube-state-metrics/kube-state-metrics:v2.13.0
docker rmi registry.myk8s.cn/prometheus/node-exporter:v1.8.2
docker rmi registry.myk8s.cn/prometheus-adapter/prometheus-adapter:v0.12.0
docker rmi registry.myk8s.cn/prometheus-operator/prometheus-operator:v0.76.2
docker rmi registry.myk8s.cn/prometheus/prometheus:v2.54.1
echo
echo Saving images to file
echo
docker save -o alertmanager.tar quay.io/prometheus/alertmanager:v0.27.0
docker save -o blackbox-exporter.tar quay.io/prometheus/blackbox-exporter:v0.25.0
docker save -o configmap-reload.tar ghcr.io/jimmidyson/configmap-reload:v0.13.1
docker save -o kube-rbac-proxy.tar quay.io/brancz/kube-rbac-proxy:v0.18.1
docker save -o grafana.tar grafana/grafana:11.2.0
docker save -o kube-state-metrics.tar registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.13.0
docker save -o node-exporter.tar quay.io/prometheus/node-exporter:v1.8.2
docker save -o prometheus-adapter.tar registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.12.0
docker save -o prometheus-operator.tar quay.io/prometheus-operator/prometheus-operator:v0.76.2
docker save -o prometheus.tar quay.io/prometheus/prometheus:v2.54.1
echo
echo Copying images file to k8s-worker1 and import it
echo
scp alertmanager.tar root@k8s-worker1:/root
scp blackbox-exporter.tar root@k8s-worker1:/root
scp configmap-reload.tar root@k8s-worker1:/root
scp kube-rbac-proxy.tar root@k8s-worker1:/root
scp grafana.tar root@k8s-worker1:/root
scp kube-state-metrics.tar root@k8s-worker1:/root
scp node-exporter.tar root@k8s-worker1:/root
scp prometheus-adapter.tar root@k8s-worker1:/root
scp prometheus-operator.tar root@k8s-worker1:/root
scp prometheus.tar root@k8s-worker1:/root
sshcmd k8s-worker1 'docker load -i /root/alertmanager.tar'
sshcmd k8s-worker1 'docker load -i /root/blackbox-exporter.tar'
sshcmd k8s-worker1 'docker load -i /root/configmap-reload.tar'
sshcmd k8s-worker1 'docker load -i /root/kube-rbac-proxy.tar'
sshcmd k8s-worker1 'docker load -i /root/grafana.tar'
sshcmd k8s-worker1 'docker load -i /root/kube-state-metrics.tar'
sshcmd k8s-worker1 'docker load -i /root/node-exporter.tar'
sshcmd k8s-worker1 'docker load -i /root/prometheus-adapter.tar'
sshcmd k8s-worker1 'docker load -i /root/prometheus-operator.tar'
sshcmd k8s-worker1 'docker load -i /root/prometheus.tar'
echo
echo Copying images file to k8s-worker2 and import it
echo
scp alertmanager.tar root@k8s-worker2:/root
scp blackbox-exporter.tar root@k8s-worker2:/root
scp configmap-reload.tar root@k8s-worker2:/root
scp kube-rbac-proxy.tar root@k8s-worker2:/root
scp grafana.tar root@k8s-worker2:/root
scp kube-state-metrics.tar root@k8s-worker2:/root
scp node-exporter.tar root@k8s-worker2:/root
scp prometheus-adapter.tar root@k8s-worker2:/root
scp prometheus-operator.tar root@k8s-worker2:/root
scp prometheus.tar root@k8s-worker2:/root
sshcmd k8s-worker2 'docker load -i /root/alertmanager.tar'
sshcmd k8s-worker2 'docker load -i /root/blackbox-exporter.tar'
sshcmd k8s-worker2 'docker load -i /root/configmap-reload.tar'
sshcmd k8s-worker2 'docker load -i /root/kube-rbac-proxy.tar'
sshcmd k8s-worker2 'docker load -i /root/grafana.tar'
sshcmd k8s-worker2 'docker load -i /root/kube-state-metrics.tar'
sshcmd k8s-worker2 'docker load -i /root/node-exporter.tar'
sshcmd k8s-worker2 'docker load -i /root/prometheus-adapter.tar'
sshcmd k8s-worker2 'docker load -i /root/prometheus-operator.tar'
sshcmd k8s-worker2 'docker load -i /root/prometheus.tar'
EOF
bash dockerimage默认情况下,grafana等各个组件都提供了网络策略,无法被外部访问,我们先删除grafana的策略,并修改它的服务暴露方式为NodePort,因为要从外部访问它的图表面板
rm -rf manifests/grafana-networkPolicy.yaml
sed -i '/spec:/a\ type: NodePort' manifests/grafana-service.yaml
sed -i '/targetPort/a\ nodePort: 32000' manifests/grafana-service.yaml
sed -i '/ image: /a\ imagePullPolicy: IfNotPresent' manifests/nodeExporter-daemonset.yaml
sed -i '/ image: /a\ imagePullPolicy: IfNotPresent' manifests/blackboxExporter-deployment.yaml
sed -i '/ image: /a\ imagePullPolicy: IfNotPresent' manifests/grafana-deployment.yaml
sed -i '/ image: /a\ imagePullPolicy: IfNotPresent' manifests/kubeStateMetrics-deployment.yaml
sed -i '/ image: /a\ imagePullPolicy: IfNotPresent' manifests/prometheusAdapter-deployment.yaml
sed -i '/ image: /a\ imagePullPolicy: IfNotPresent' manifests/prometheusOperator-deployment.yaml
sed -i '/ image: /a\ imagePullPolicy: IfNotPresent' manifests/alertmanager-alertmanager.yaml
sed -i '/ image: /a\ imagePullPolicy: IfNotPresent' manifests/prometheus-prometheus.yaml
kubectl apply -f manifests/确定grafana已经定义了32000端口,直接在浏览器打开任意节点的IP地址访问
root@k8s-master:~# kubectl get service -n monitoring grafana
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.99.168.64 <none> 3000:32000/TCP 30m配置好解析后,在浏览器中打开 http://k8s-worker1:32000 ,或者不配置解析用IP也可以
用户名和密码都是admin,点击login之后会让你修改新密码,进行修改后点击submit或直接点击skip不修改

点击左侧或右上角的+号,选择import导入k8s模板
点击 [模板链接](Dashboards | Grafana Labs) 选一个模板,把ID填进来,点击load即可
category选择Docker,Data Source选择Prometheus可以更好的筛选
自己可以挑选喜欢的模板,点击进去可以看到图示,选好之后点击Copy ID,填到我们的系统中即可
填好ID之后,点击ID后侧的load按钮进行加载,在最下侧的Prometheus处,选择Prometheus,然后点击import
19.5 升级控制平面
先确定要升级的版本
root@k8s-master:~# apt update
root@k8s-master:~# apt list kubeadm -a
Listing... Done
kubeadm/unknown 1.32.7-1.1 amd64 [upgradable from: 1.32.0-1.1]
kubeadm/unknown 1.32.6-1.1 amd64
kubeadm/unknown 1.32.5-1.1 amd64
kubeadm/unknown 1.32.4-1.1 amd64
kubeadm/unknown 1.32.3-1.1 amd64
kubeadm/unknown 1.32.2-1.1 amd64
kubeadm/unknown 1.32.1-1.1 amd64
kubeadm/unknown,now 1.32.0-1.1 amd64 [installed,upgradable to: 1.32.7-1.1]
kubeadm/unknown 1.32.7-1.1 arm64
kubeadm/unknown 1.32.6-1.1 arm64
kubeadm/unknown 1.32.5-1.1 arm64
kubeadm/unknown 1.32.4-1.1 arm64
kubeadm/unknown 1.32.3-1.1 arm64
kubeadm/unknown 1.32.2-1.1 arm64
kubeadm/unknown 1.32.1-1.1 arm64
kubeadm/unknown 1.32.0-1.1 arm64
kubeadm/unknown 1.32.7-1.1 ppc64el
kubeadm/unknown 1.32.6-1.1 ppc64el
kubeadm/unknown 1.32.5-1.1 ppc64el
kubeadm/unknown 1.32.4-1.1 ppc64el
kubeadm/unknown 1.32.3-1.1 ppc64el
kubeadm/unknown 1.32.2-1.1 ppc64el
kubeadm/unknown 1.32.1-1.1 ppc64el
kubeadm/unknown 1.32.0-1.1 ppc64el
kubeadm/unknown 1.32.7-1.1 s390x
kubeadm/unknown 1.32.6-1.1 s390x
kubeadm/unknown 1.32.5-1.1 s390x
kubeadm/unknown 1.32.4-1.1 s390x
kubeadm/unknown 1.32.3-1.1 s390x
kubeadm/unknown 1.32.2-1.1 s390x
kubeadm/unknown 1.32.1-1.1 s390x
kubeadm/unknown 1.32.0-1.1 s390x在上一步可以看到一个可用的列表,假设要升级的目标为1.32.7-1.1的版本
禁止Master节点接收新调度
root@k8s-master:~# kubectl cordon k8s-master
node/k8s-master cordoned
root@k8s-master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready,SchedulingDisabled control-plane 105d v1.32.0
k8s-worker1 Ready worker 105d v1.32.0
k8s-worker2 Ready worker 105d v1.32.0驱逐Master节点上的现有任务
root@k8s-master:~# kubectl drain k8s-master --ignore-daemonsets --delete-emptydir-data安装目标的kubeadm、kubelet、kubectl
root@k8s-master:~# apt-get update
root@k8s-master:~# apt-get install -y kubelet=1.32.7-1.1 kubeadm=1.32.7-1.1 kubectl=1.32.7-1.1查看可升级的列表并升级
root@k8s-master:~# kubeadm upgrade plan看完之后来升级,一般数据库不升级,或者先备份好再升级
root@k8s-master:~# kubeadm upgrade apply v1.32.7 --etcd-upgrade=false恢复Master节点的调度能力
root@k8s-master:~# systemctl restart kubelet
root@k8s-master:~# kubectl uncordon k8s-master
node/k8s-master uncordoned
root@k8s-master:~# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane 105d v1.32.7
k8s-worker1 Ready worker 105d v1.32.0
k8s-worker2 Ready worker 105d v1.32.020 ETCD 备份与恢复
20.1 备份
先安装etcd客户端
root@k8s-master:~# apt install etcd-client -y备份成文件并查看
ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save etcdbackupfile.db20.2 恢复
1.停止服务
root@k8s-master:~# mv /etc/kubernetes/manifests /etc/kubernetes/manifests.bak
root@k8s-master:~# sleep 1m
2.删除现有ETCD,并恢复数据
root@k8s-master:~# mv /var/lib/etcd /var/lib/etcd.bak
root@k8s-master:~# ETCDCTL_API=3 etcdctl \
--endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
--data-dir /var/lib/etcd \
snapshot restore etcdbackupfile.db
3.恢复服务
root@k8s-master:~# mv /etc/kubernetes/manifests.bak /etc/kubernetes/manifests
root@k8s-master:~# systemctl restart kubelet.service
4.验证数据已经恢复
root@k8s-master:~# kubectl get pod
5.检查etcd是否健康
root@k8s-master:~# ETCDCTL_API=3 etcdctl --endpoints=https://192.168.8.3:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key endpoint health
https://192.168.8.3:2379 is healthy: successfully committed proposal: took = 6.794497ms21 Kustomize管理
21.1 Kustomize 概念
Kustomize 是 Kubernetes 的原生配置管理工具,它允许用户通过定义资源和它们之间的依赖关系来描述 Kubernetes 应用程序的配置。
Kustomize 的核心概念大概包括:
Kustomization 文件:
这是 Kustomize 配置的核心,它是一个 YAML 文件,定义了 Kubernetes 资源和如何定制它们。它可以用来指定要包含的资源、应用补丁、设置标签和注解、生成configmap和secret等
资源(Resources):
在 kustomization.yaml 文件中定义的 Kubernetes 资源列表,可以是文件、目录或者远程仓库中的资源。
生成器(Generators):
如 configMapGenerator 和 secretGenerator,它们可以根据文件或字面值生成 ConfigMap 或 Secret。
补丁(Patches):
用于修改现有资源的字段。Kustomize 支持策略性合并补丁(patchesStrategicMerge)和 JSON 补丁(patchesJson6902)。
基准(Bases):
包含 kustomization.yaml 文件的目录,定义了一组资源及其定制。
覆盖(Overlays):
也是一个目录,它引用基准目录作为基础,并且可以包含额外的定制。覆盖可以用来创建特定环境的配置,如开发、测试和生产环境。
Kustomize 的工作流程通常包括定义基准和覆盖,然后在覆盖中应用补丁和生成器来定制基准资源。这种方式使得用户可以轻松地为不同环境创建和管理 Kubernetes 资源配置。
21.2 Kustomize 实验概述
本实验旨在通过实际操作,让大家掌握 Kustomize 的使用,以便能够根据不同的环境需求(如开发、测试和生产环境)定制和管理 Kubernetes 应用的配置。
21.3 Kustomize 实验目标
理解 Kustomize 的作用和优势:
理解 Kustomize 如何简化 Kubernetes 应用的配置管理。
创建和管理 Base 目录:
学会创建包含通用资源定义的 Base 目录。
编写 kustomization.yaml 文件来声明资源、生成器和补丁。
定制 Overlay 配置:
学会创建 Overlay 目录以适应特定环境的配置需求。
应用 patchesStrategicMerge 和 patchesJson6902 来定制 Deployment 资源。
生成 ConfigMap 和 Secret:
使用 configMapGenerator 和 secretGenerator 来生成环境特定的配置和敏感信息。
应用环境标签和注解:
在资源上添加环境特定的标签(如 env: dev)和注解。
禁用名称后缀哈希:
配置 generatorOptions 以禁用资源名称的哈希后缀,以保持资源名称的一致性。
验证 Overlay 配置:
使用 kubectl kustomize 命令来验证 Overlay 目录的最终 Kubernetes 资源配置。
部署到 Kubernetes 集群:
使用 kubectl apply -k 命令将定制的 Overlay 配置应用到 Kubernetes 集群。
清理和维护:
学会如何清理实验中创建的资源,包括 Namespace 和各种 Kubernetes 资源。
21.4 Kustomize 实验步骤
21.4.1 准备Base目录
先在base目录中创建一些通用的yaml文件
root@k8s-master:~# mkdir base
root@k8s-master:~# cd base
root@k8s-master:~/base#在base目录中,创建一个secret,稍后可以在overlay目录中打补丁或者不打,secret文件如下:
这个密码是ABCabc123
cat > Secret.yml <<-EOF
apiVersion: v1
data:
password: QUJDYWJjMTIz
kind: Secret
metadata:
name: mysqlpass
EOF在base目录中,创建一个Deployment,replicas是3,标签为app: nginx, Deployment文件如下:
cat > Deployment.yml <<-EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: mysqlname
image: mysql:5.7
imagePullPolicy: IfNotPresent
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysqlpass
key: password
EOF在base目录中,创建一个Service,Service文件如下:
cat > Service.yml <<-EOF
apiVersion: v1
kind: Service
metadata:
name: nodeservice
spec:
type: NodePort
selector:
app: nginx
ports:
- protocol: TCP
port: 8000
targetPort: 80
nodePort: 31788
EOF最后生成kustomization.yaml,在这个文件中包含刚创建的3个资源:
cat > kustomization.yaml <<-EOF
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
metadata:
name: lxh-base-kustomization
resources:
- Secret.yml
- Deployment.yml
- Service.yml
EOF查看现在文件列表:
root@k8s-master:~/base# apt install tree -y
root@k8s-master:~/base# tree .
.
├── Deployment.yml
├── kustomization.yaml
├── Secret.yml
└── Service.yml
1 directory, 4 files以上在base目录中的文件将用于生成:
一个名为mysqlpass的机密
一个名为nginx-deployment的部署,此部署的pod将具有app: nginx标签,并引用mysqlpass机密作为密码,密码值为ABCabc123
一个名为nodeservice的服务,监听在8000端口,收到请求后,转发给具有app: nginx标签的pod,并启用了31788的nodePort
21.4.2 准备Overlay目录
创建开发环境
root@k8s-master:~/base# cd
root@k8s-master:~# mkdir -p overlays/development
root@k8s-master:~# cd overlays/development
root@k8s-master:~/overlays/development#创建开发环境的kustomization.yaml 文件:
Kustomize 功能特性列表参阅:
https://kubernetes.io/zh-cn/docs/tasks/manage-kubernetes-objects/kustomization/#kustomize-feature-list
1. patchesStrategicMerge补丁将会更新nginx-deployment这个Deployment
2. patchesJson6902补丁也会更新nginx-deployment这个Deployment
3. overlay的对象是刚创建的base目录下的内容
4. 全体对象添加env: dev
5. 禁止添加hash后缀
6. 产生两个新的configmap和secretcat > kustomization.yaml <<-EOF
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: lxh-dev
patches:
- path: patchesStrategicMerge-demo.yaml
target:
kind: Deployment
name: nginx-deployment
options:
allowNameChange: true
- path: patchesJson6902-demo.yaml
target:
kind: Deployment
name: nginx-deployment
options:
allowNameChange: true
resources:
- ../../base
commonLabels:
env: dev
generatorOptions:
disableNameSuffixHash: true
configMapGenerator:
- name: cmusername
files:
- configmap-1.yml
- name: cmage
literals:
- cmage=18
secretGenerator:
- name: username
files:
- secret-1.yml
type: Opaque
- name: secrettest
literals:
- password=LiXiaoHui
type: Opaque
EOF21.4.3 生成器Generator
在kustomization.yaml,如果用文件来生成configmap和secret,会将文件名也作为数据的一部分,建议用literals
生成configmap和secret的文件
cat > configmap-1.yml <<-EOF
username=lixiaohui
EOF
cat > secret-1.yml <<-EOF
username=admin
password=secret
EOF21.4.4 策略性合并与JSON补丁
在 Kustomize 中,patchesStrategicMerge 和 patchesJson6902 都用于修改现有的 Kubernetes 资源。
1.patchesStrategicMerge补丁方式使用 YAML 文件来定义,它允许直接编辑资源的 YAML 结构,就像编辑原始资源文件一样。这种方式直观且易于理解,特别是对于那些熟悉 Kubernetes 资源配置的人来说
2.patchesJson6902 使用的是 JSON 补丁(JSON Patch)的方式,这是一种更为灵活和强大的补丁应用方式。JSON 补丁遵循 JSON Patch 规范(RFC 6902),允许执行更复杂的操作,如添加、删除、替换、测试等。这种方式使用 JSON 格式定义,可能在处理复杂的修改时更加强大。
生成策略性合并补丁
这里的名字一定要和已有的资源的名称一致
更新deployment的replicas为4
cat > patchesStrategicMerge-demo.yaml <<-EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 4
EOF生成JSON补丁
新增deployment下的pod标签为dev: release1
cat > patchesJson6902-demo.yaml <<-EOF
[
{
"op": "add",
"path": "/spec/template/metadata/labels/dev",
"value": "release1"
}
]
EOF目前的文件列表:
root@k8s-master:~/overlays/development# tree .
.
├── configmap-1.yml
├── kustomization.yaml
├── patchesJson6902-demo.yaml
├── patchesStrategicMerge-demo.yaml
└── secret-1.yml
1 directory, 5 files21.4.5 验证overlay最终成果
root@k8s-master:~/overlays/development# kubectl kustomize ./
# Warning: 'commonLabels' is deprecated. Please use 'labels' instead. Run 'kustomize edit fix' to update your Kustomization automatically.
apiVersion: v1
data:
cmage: "18"
kind: ConfigMap
metadata:
labels:
env: dev
name: cmage
namespace: lxh-dev
---
apiVersion: v1
data:
configmap-1.yml: |
username=lixiaohui
kind: ConfigMap
metadata:
labels:
env: dev
name: cmusername
namespace: lxh-dev
---
apiVersion: v1
data:
password: QUJDYWJjMTIz
kind: Secret
metadata:
labels:
env: dev
name: mysqlpass
namespace: lxh-dev
---
apiVersion: v1
data:
password: TGlYaWFvSHVp
kind: Secret
metadata:
labels:
env: dev
name: secrettest
namespace: lxh-dev
type: Opaque
---
apiVersion: v1
data:
secret-1.yml: dXNlcm5hbWU9YWRtaW4KcGFzc3dvcmQ9c2VjcmV0Cg==
kind: Secret
metadata:
labels:
env: dev
name: username
namespace: lxh-dev
type: Opaque
---
apiVersion: v1
kind: Service
metadata:
labels:
env: dev
name: nodeservice
namespace: lxh-dev
spec:
ports:
- nodePort: 31788
port: 8000
protocol: TCP
targetPort: 80
selector:
app: nginx
env: dev
type: NodePort
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: nginx
env: dev
name: nginx-deployment
namespace: lxh-dev
spec:
replicas: 4
selector:
matchLabels:
app: nginx
env: dev
template:
metadata:
labels:
app: nginx
dev: release1
env: dev
spec:
containers:
- env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
key: password
name: mysqlpass
image: mysql:5.7
imagePullPolicy: IfNotPresent
name: mysqlname21.4.6 发布开发环境
root@k8s-master:~/overlays/development# cd /root/overlays/development/
root@k8s-master:~/overlays/development# kubectl create namespace lxh-dev
namespace/lxh-dev created
root@k8s-master:~/overlays/development# kubectl apply -k .
# Warning: 'commonLabels' is deprecated. Please use 'labels' instead. Run 'kustomize edit fix' to update your Kustomization automatically.
configmap/cmage created
configmap/cmusername created
secret/mysqlpass created
secret/secrettest created
secret/username created
service/nodeservice created
deployment.apps/nginx-deployment created查询创建的内容
发现新configmap和secret已经生效,两个补丁也都生效了,一个补丁将deployment的pod数量该为4,一个补丁添加了dev=release1的标签
root@k8s-master:~/overlays/development# kubectl get configmaps -n lxh-dev
NAME DATA AGE
cmage 1 90s
cmusername 1 90s
kube-root-ca.crt 1 99s
root@k8s-master:~/overlays/development# kubectl get secrets -n lxh-dev
NAME TYPE DATA AGE
mysqlpass Opaque 1 100s
secrettest Opaque 1 100s
username Opaque 1 100s
root@k8s-master:~/overlays/development# kubectl get service -n lxh-dev
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nodeservice NodePort 10.108.18.219 <none> 8000:31788/TCP 116s
root@k8s-master:~/overlays/development# kubectl get deployments.apps -n lxh-dev
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deployment 2/4 4 2 2m4s
root@k8s-master:~/overlays/development# kubectl get pod --show-labels -n lxh-dev
NAME READY STATUS RESTARTS AGE LABELS
nginx-deployment-7dc9f5ffbf-4pv2v 1/1 Running 0 4m13s app=nginx,dev=release1,env=dev,pod-template-hash=7dc9f5ffbf
nginx-deployment-7dc9f5ffbf-bskzl 0/1 ContainerCreating 0 4m13s app=nginx,dev=release1,env=dev,pod-template-hash=7dc9f5ffbf
nginx-deployment-7dc9f5ffbf-fx5v7 0/1 ContainerCreating 0 4m13s app=nginx,dev=release1,env=dev,pod-template-hash=7dc9f5ffbf
nginx-deployment-7dc9f5ffbf-nqwb8 1/1 Running 0 4m13s app=nginx,dev=release1,env=dev,pod-template-hash=7dc9f5ffbf